Best AI tools for< Voice Cloning >
Infographic
20 - AI tool Sites
MyVocal.ai
MyVocal.ai is a text-to-speech and voice cloning tool that allows users to create realistic-sounding voices from text. With MyVocal.ai, you can clone your own voice or choose from a variety of pre-recorded voices. You can then use these voices to create songs, audiobooks, podcasts, and other audio content. MyVocal.ai also offers a variety of features to help you customize your voice, including the ability to change the pitch, speed, and volume. Additionally, MyVocal.ai offers a variety of features to help you create high-quality audio content, including the ability to add background music and sound effects.
ToneShift
ToneShift is an AI-powered platform that allows users to clone voices, separate music, and join a community of voices. With ToneShift, users can transform recordings into versatile voices for various purposes, separate vocals and instrumentals from songs to create new remixes and mashups, and join a community to discover new tones, contribute their creations, and collaborate with others.
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
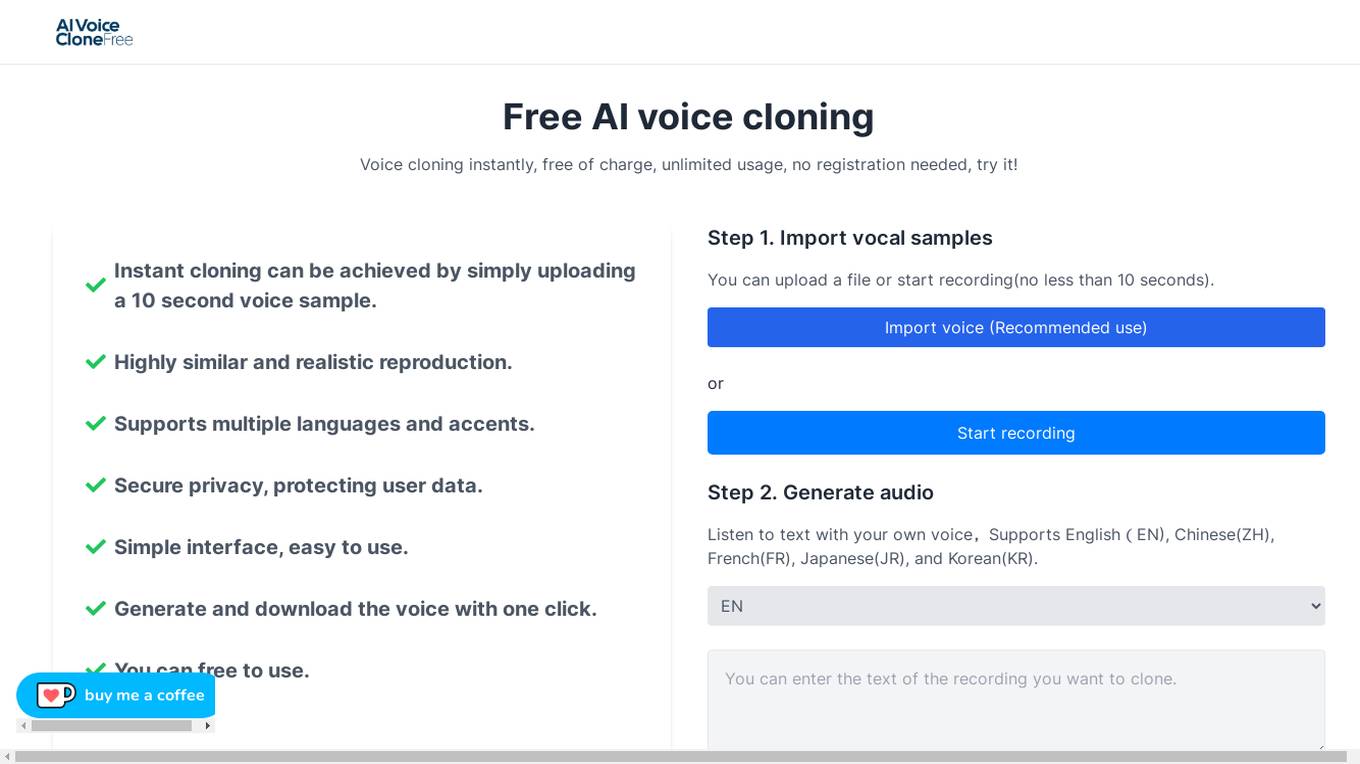
Woy AI Tools
Woy AI Tools is a free AI voice cloning application that allows users to instantly clone voices with high similarity and realism. Users can upload a 10-second voice sample to generate and download cloned voices in multiple languages and accents. The tool ensures secure privacy and offers a simple interface for easy usage.
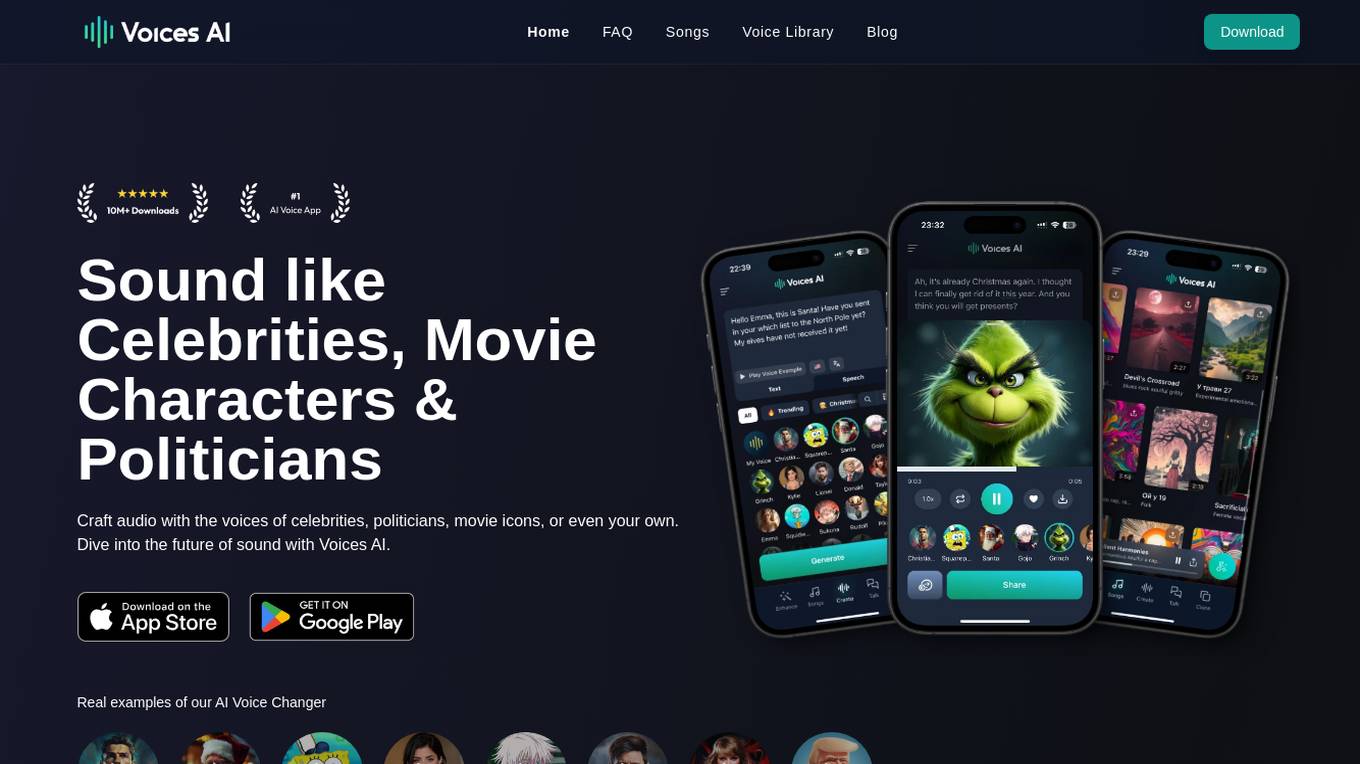
Voices AI
Voices AI is an AI voice generator and celebrity voice changer application that allows users to craft audio using the voices of celebrities, politicians, and movie characters. It offers features such as turning text into speech, chatting with AI characters, emotional speech with speech-to-speech capabilities, voice cloning, generating AI songs, and a vast library of hyper-realistic AI voices. The application ensures privacy of voice recordings and updates its voice library regularly to include trending and popular voices. Voices AI stands out from other voice generation tools with its focus on continuous innovation, user experience, and audio quality.
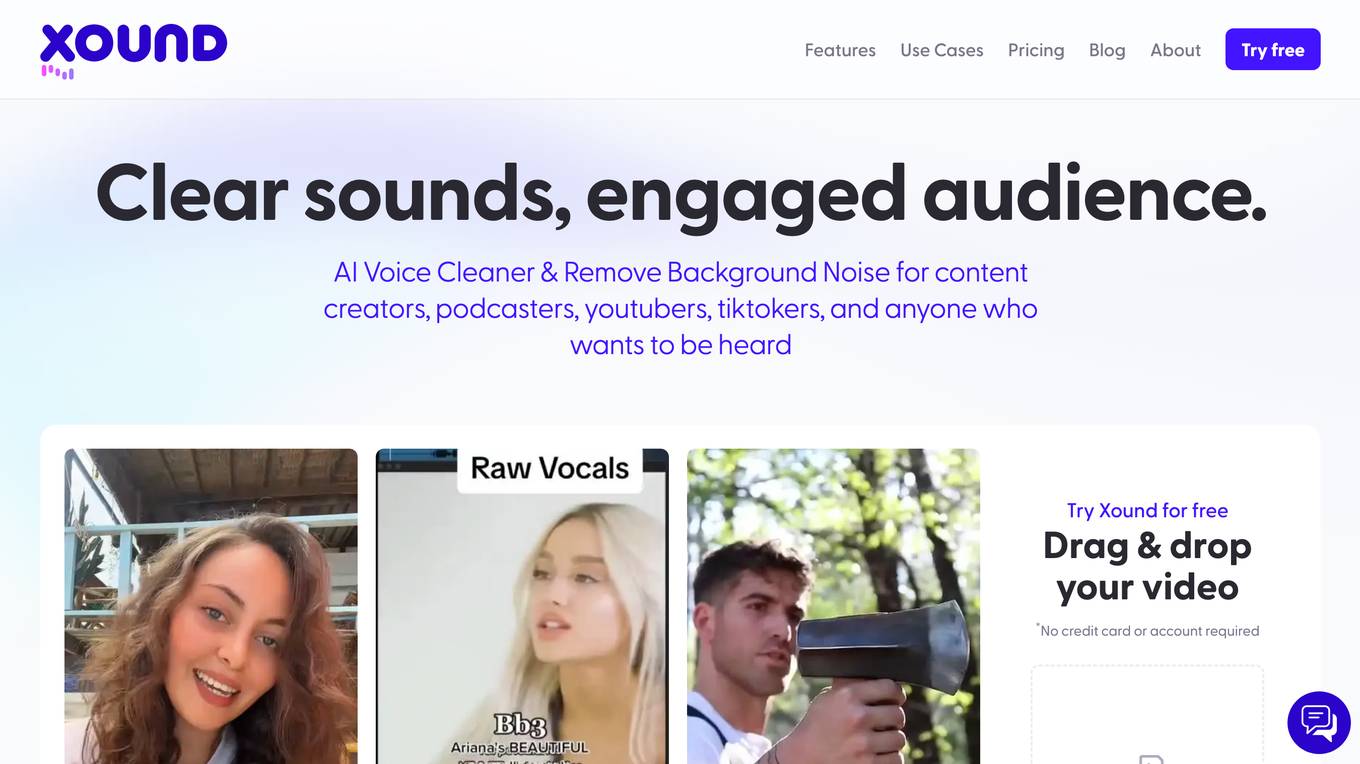
Xound.io
Xound.io is an AI-powered voice cleaner and background noise removal tool designed for content creators, podcasters, YouTubers, TikTokers, and anyone who wants to improve the audio quality of their content. It uses advanced algorithms to remove background noise, enhance vocals, and improve the overall listening experience. Xound.io is easy to use, with a simple drag-and-drop interface and no need for any technical expertise. It also offers a variety of features, including natural pitch correction, AI background noise removal, and high-frequency presence.
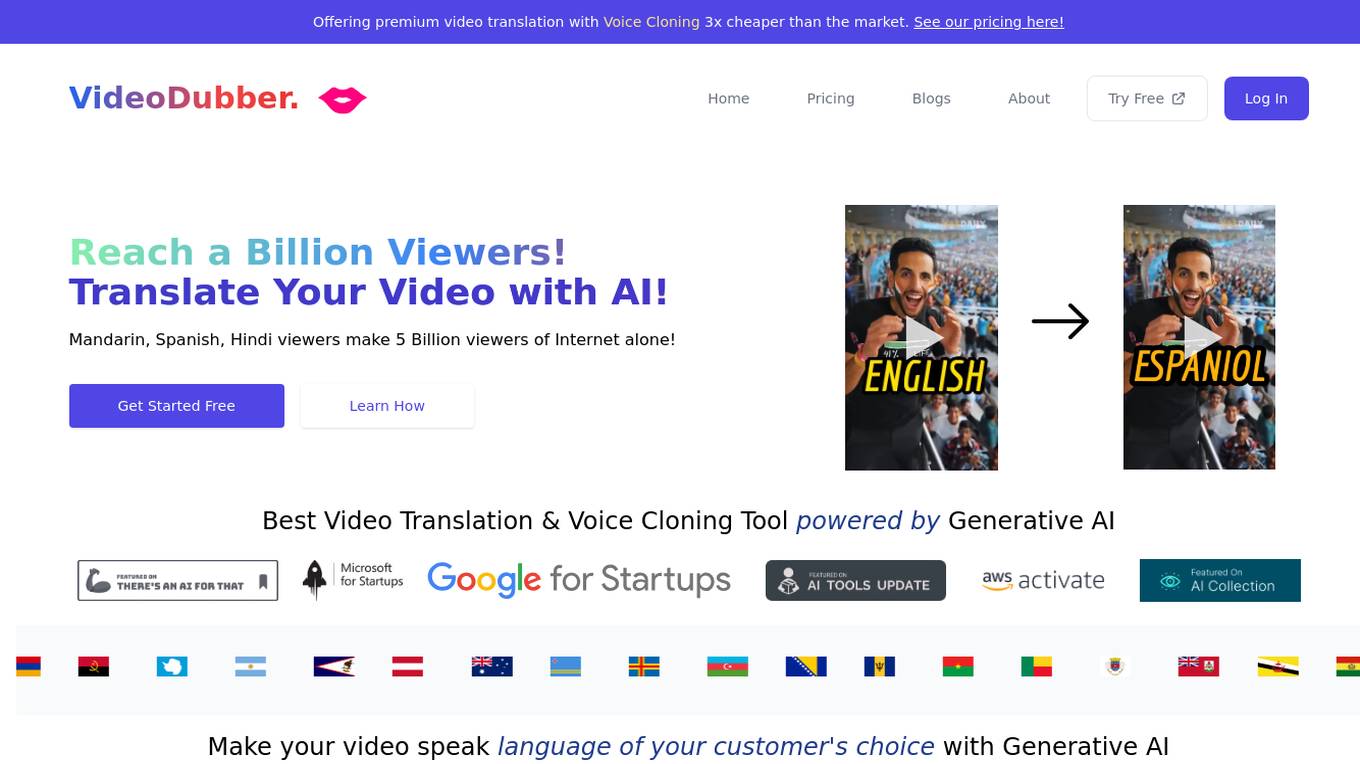
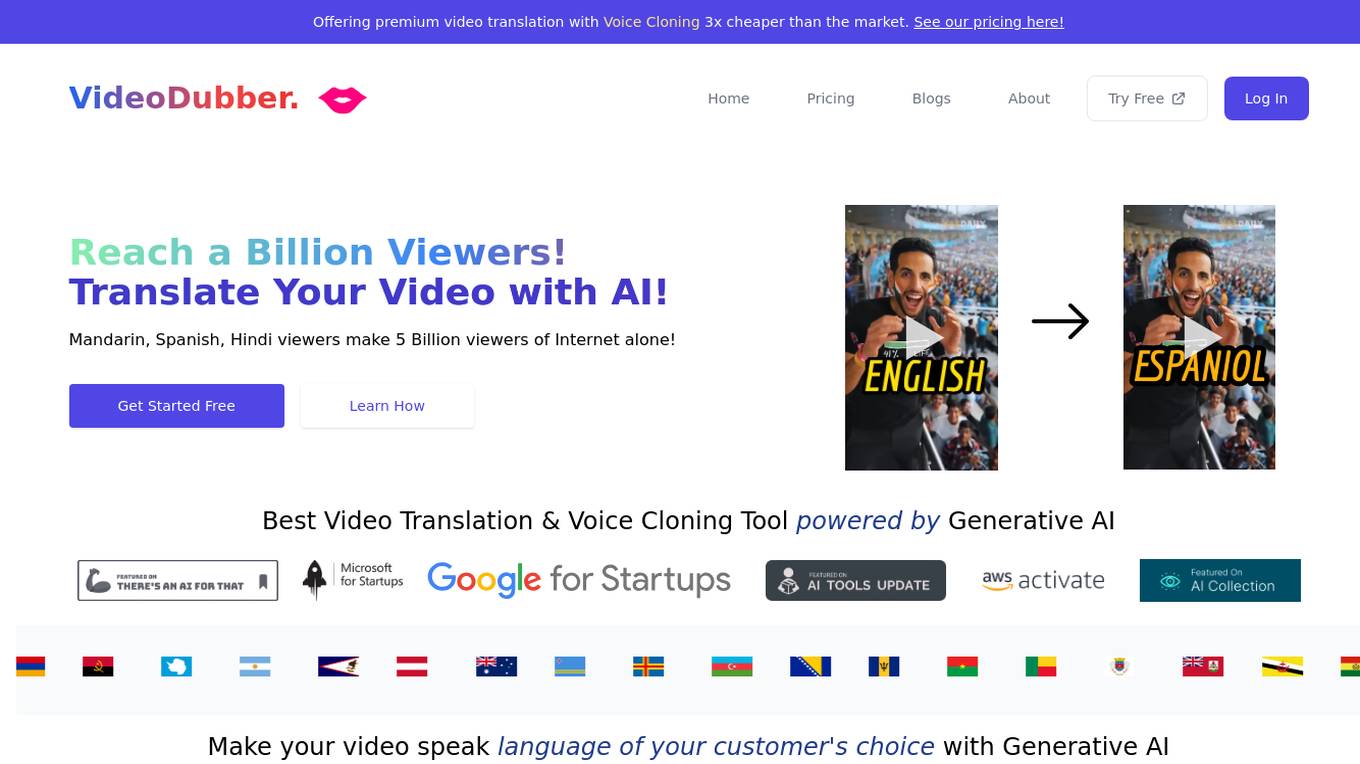
VideoDubber
VideoDubber is an AI-powered video translation and voice cloning tool that allows users to translate videos into over 150 languages with just one click. It also offers features such as voice cloning, text-to-speech, and subtitling. VideoDubber is designed to help businesses and content creators reach a global audience by making their videos accessible to viewers who speak different languages.
VideoDubber
VideoDubber is an AI-powered video translation and voice cloning tool that allows users to translate videos into over 150 languages with just one click. It also offers features such as voice cloning, text-to-speech, and subtitling. VideoDubber is a valuable tool for businesses and content creators who want to reach a global audience with their videos.
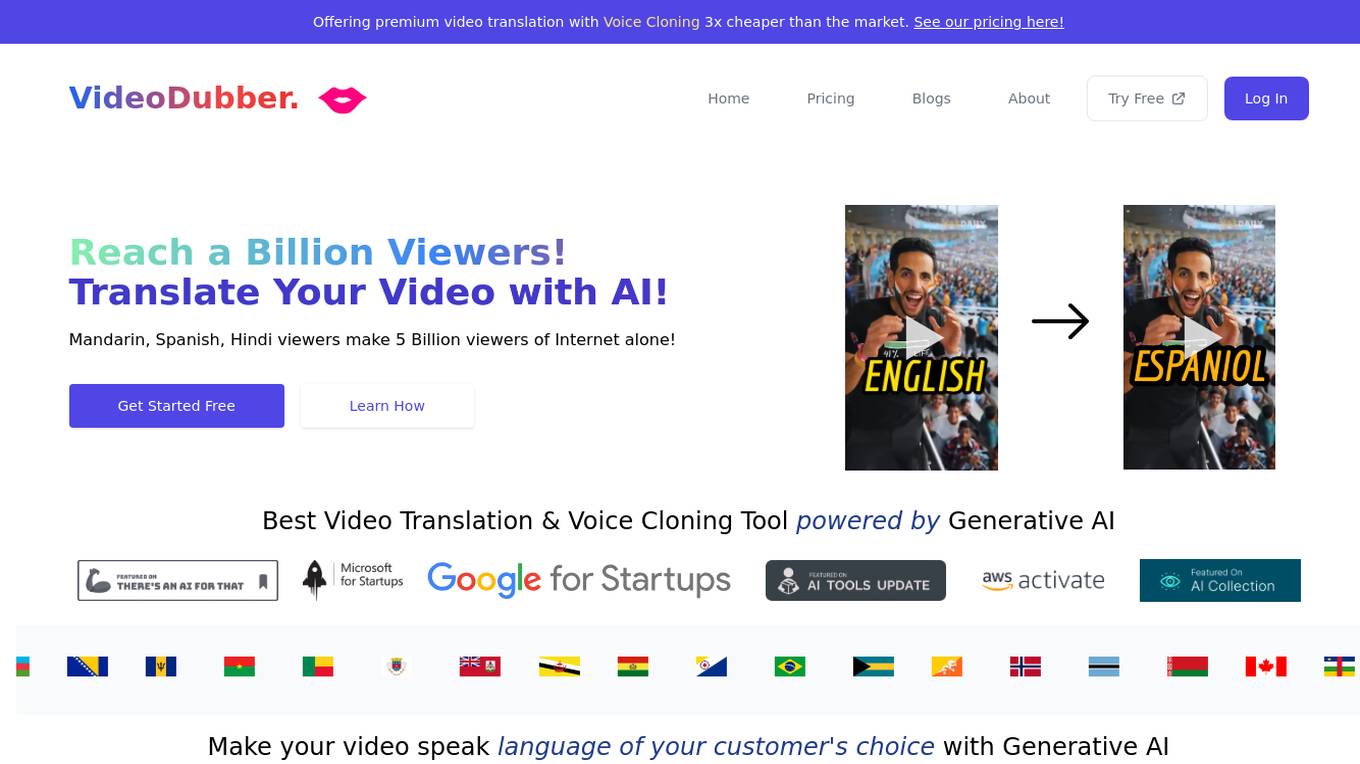
VideoDubber
VideoDubber is an AI-powered video translation and text-to-speech tool that offers premium video translation with voice cloning at a fraction of the market price. It enables users to make their videos speak in the language of their audience's choice using Generative AI. The platform supports translation to over 150 languages and accents, providing features like voice cloning, subtitles modification, and dubbing minutes. VideoDubber caters to a wide range of users, including Youtubers, businesses, and content creators, helping them reach a global audience and enhance viewer engagement through multilingual content.
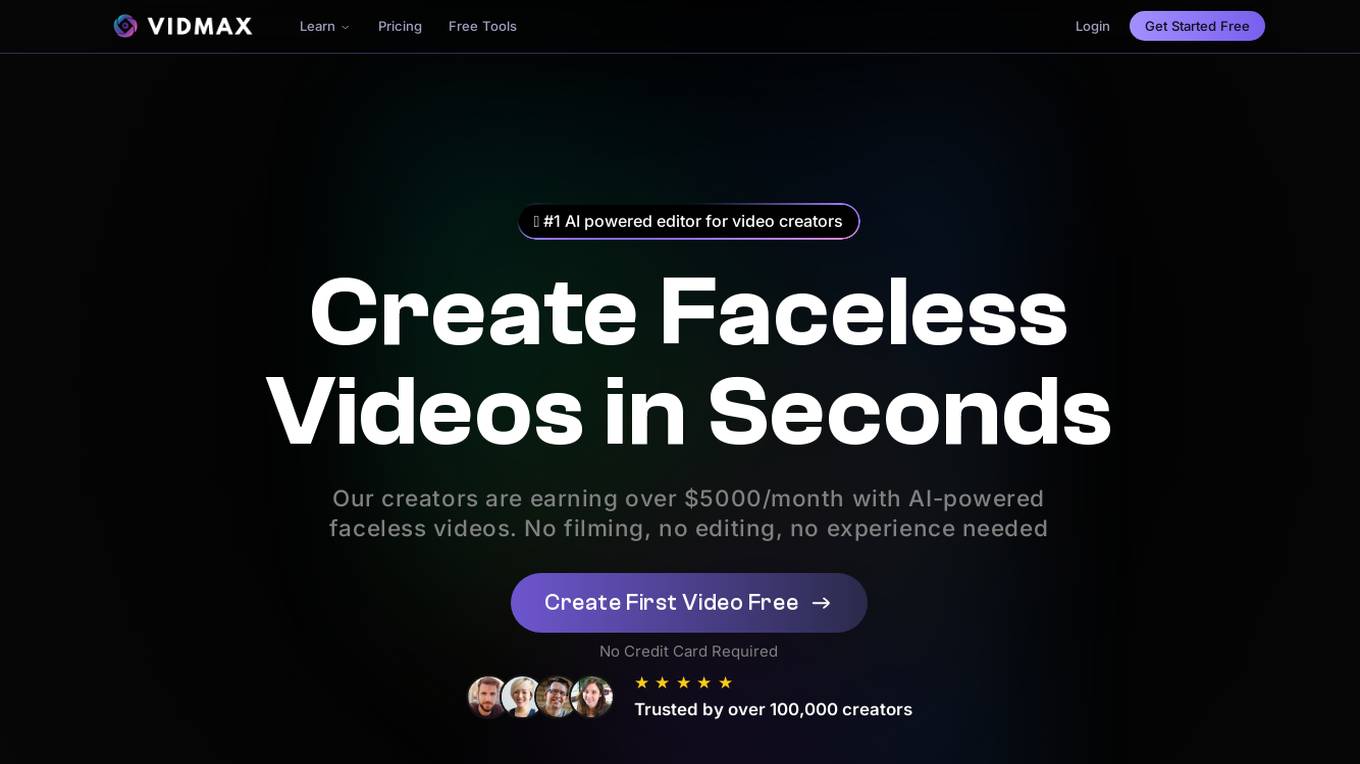
VidMax AI
VidMax AI is an AI video generator tool that allows users to create viral faceless videos in minutes. The tool utilizes artificial intelligence technology to automatically generate engaging videos without the need for manual editing or filming. Users can simply input their desired content and the tool will handle the rest, making it easy for anyone to create professional-looking videos quickly and efficiently.
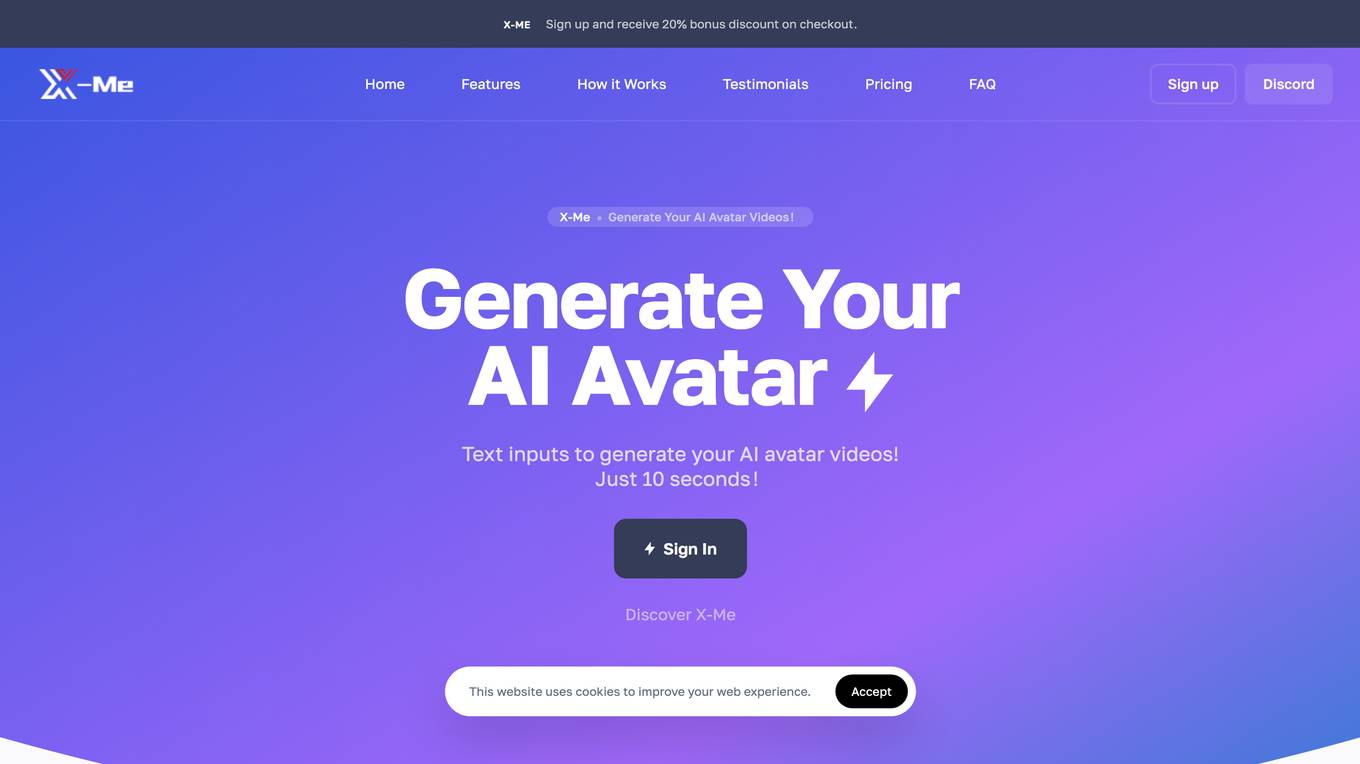
X-Me
X-Me is an AI tool that allows users to generate personalized AI avatar videos effortlessly. Users can create AI avatars that mimic famous personalities like AI Trump, AI Musk, AI Johnson, Al Kard, and AI Gaga by inputting text in multiple languages. The tool supports 147 languages, offers zero customization fees, and requires zero training. With X-Me, users can upload a selfie video, enter text, and generate AI avatar videos that reflect their face, voice, and story. The platform is known for its efficient, fast, and user-friendly approach to creating realistic digital human videos without the need for complex model training processes.
X-Me
X-Me is an AI-powered platform that allows users to create realistic digital human videos using just a selfie video and text input. With X-Me, users can generate videos in over 147 languages, and the platform offers a variety of features to customize the videos, including the ability to add music, change the background, and adjust the lighting. X-Me is a powerful tool for creating engaging and shareable content, and it is perfect for businesses, educators, and anyone who wants to create high-quality videos without the need for expensive equipment or software.
Respeecher
Respeecher is a voice cloning software that allows users to create synthetic voices that are indistinguishable from the original speaker. The software is used by content creators in a variety of industries, including film, television, gaming, advertising, and audiobooks. Respeecher's technology is based on artificial intelligence and machine learning, and it can replicate the voice of any person with just a few minutes of audio recording. The software is easy to use and can be accessed through a web interface. Respeecher offers a variety of features, including the ability to change the pitch, speed, and volume of the synthetic voice, as well as the ability to add effects such as reverb and delay. The software also includes a library of pre-recorded voices that can be used for a variety of purposes.
DubSmart
DubSmart is an AI-powered platform that offers advanced video dubbing and voice cloning services. It allows users to transform text into lifelike speech, dub videos with voice cloning technology, and generate subtitles for audio or video content. With a user-friendly interface, DubSmart enables users to create unique voices, edit projects, and download finished projects in various formats. The platform supports 33 languages for AI dubbing and 60+ languages for speech-to-text conversion. DubSmart caters to small creators, YouTubers, and companies looking to enhance their audiovisual content with personalized voices and multilingual capabilities.
Respeecher
Respeecher is an AI tool that combines technology and magic to deliver authentic voices across various industries. It uses cutting-edge public models and proprietary technology to provide high-quality voice solutions. The team of dedicated sound professionals at Respeecher ensures ethical use of synthetic media, making it a trusted choice for voice cloning and voice conversion services.

Voice.ai
Voice.ai is a free real-time voice changer and the largest ecosystem of free AI voice tools. With Voice.ai, you can change your voice in real-time, clone voices, create soundboards, and more. Voice.ai is perfect for streamers, content creators, gamers, and anyone who wants to have fun with their voice.
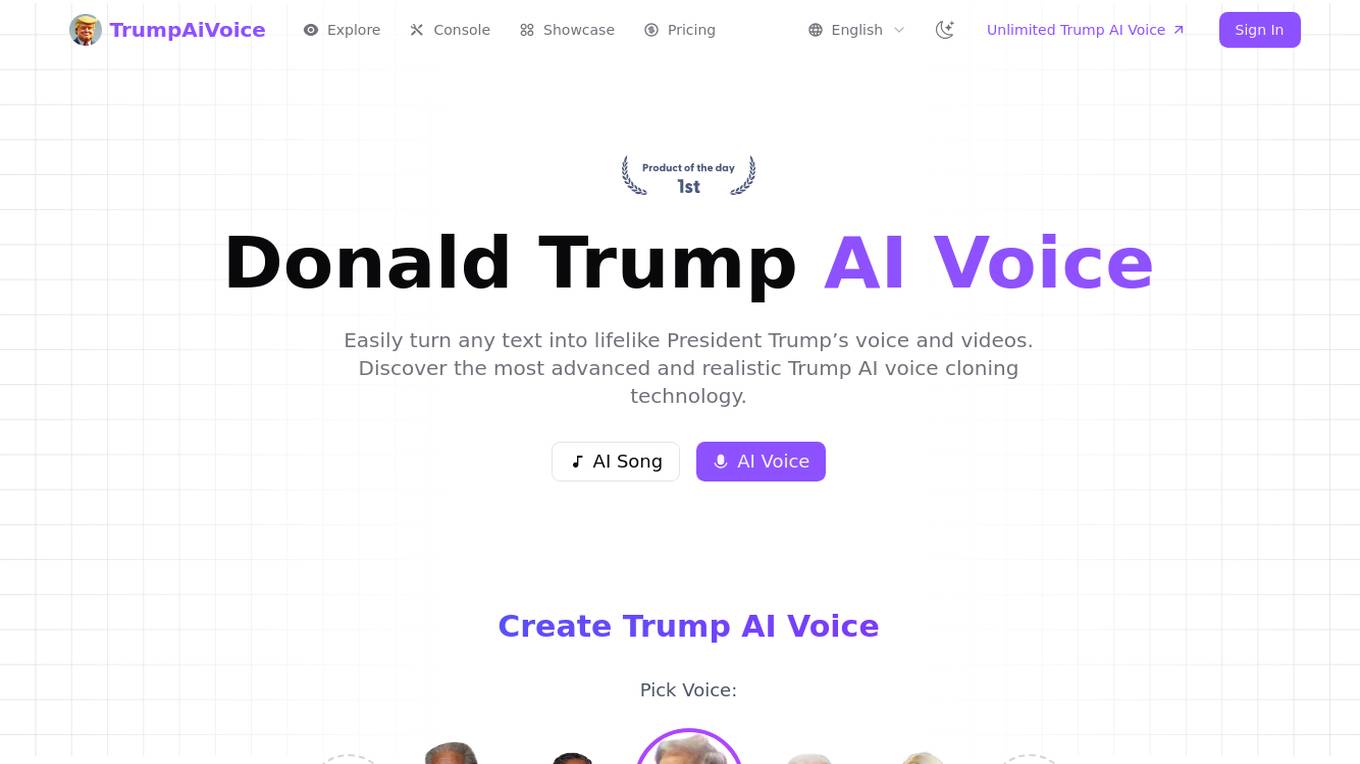
Trump AI Voice Generator
Trump AI Voice Generator is an advanced AI voice generation platform that allows users to create lifelike voice and video content using President Trump's voice and other celebrity voices. The platform offers a premium voice collection, instant voice generation, smart content rewriting, enterprise-grade infrastructure, detailed analytics dashboard, and complete privacy protection. Users can easily generate professional-quality audio and video content in seconds, customize settings, and access a variety of voices for content creation. The platform is trusted by content creators worldwide for its realism, authenticity, and versatility.
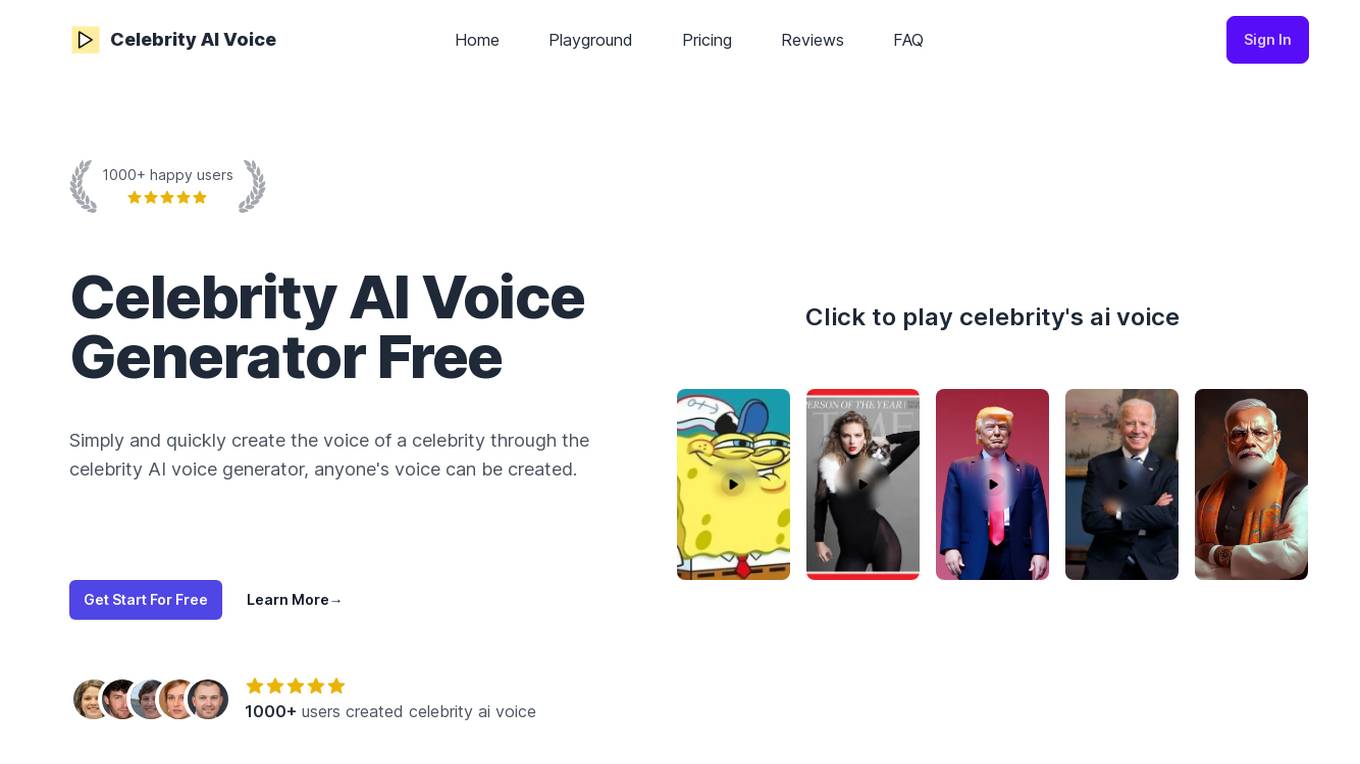
Celebrity AI Voice Generator
Celebrity AI Voice Generator is a free online tool that allows you to create realistic AI-generated voices of celebrities. With just a short audio clip of the person you want to replicate, you can generate voices that sound incredibly real. The tool is easy to use and offers a variety of features, including the ability to control voice styles, emotions, and accents. You can also use the tool to generate voices in different languages. Celebrity AI Voice Generator is a powerful tool that can be used for a variety of purposes, including creating voiceovers, dubbing videos, and developing video games.
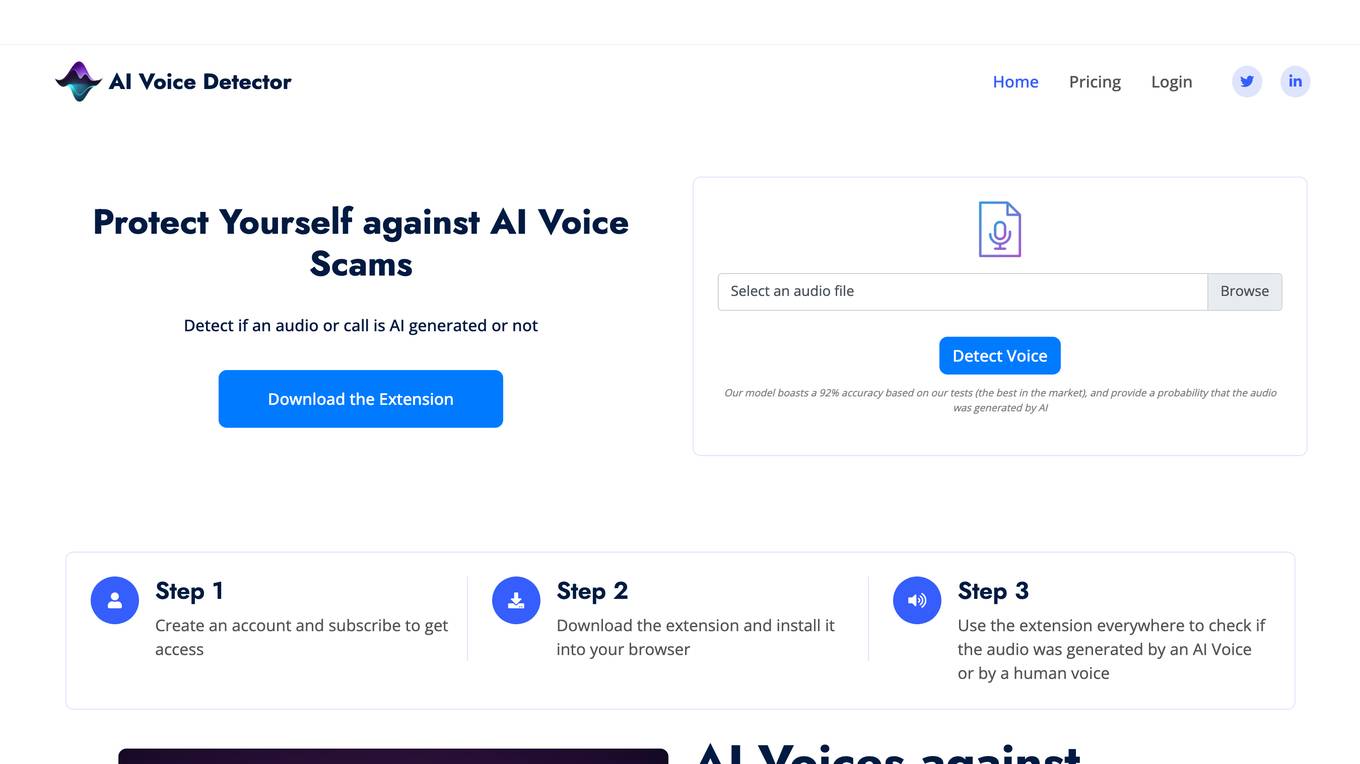
AI Voice Detector
AI Voice Detector is an AI tool designed to protect individuals and businesses from audio manipulation and AI-generated voices. It offers a high accuracy rate in identifying real voices versus AI-generated ones, integrated features to remove background noise and music, and the ability to detect AI cloned voices from various platforms. The tool can be used to scan voices on popular platforms like Youtube, WhatsApp, Tiktok, Zoom, and Google Meet. It helps individuals verify voice messages and calls to prevent falling victim to AI voice scams, while also assisting businesses in authenticating audio messages, calls, and meetings to avoid financial losses.
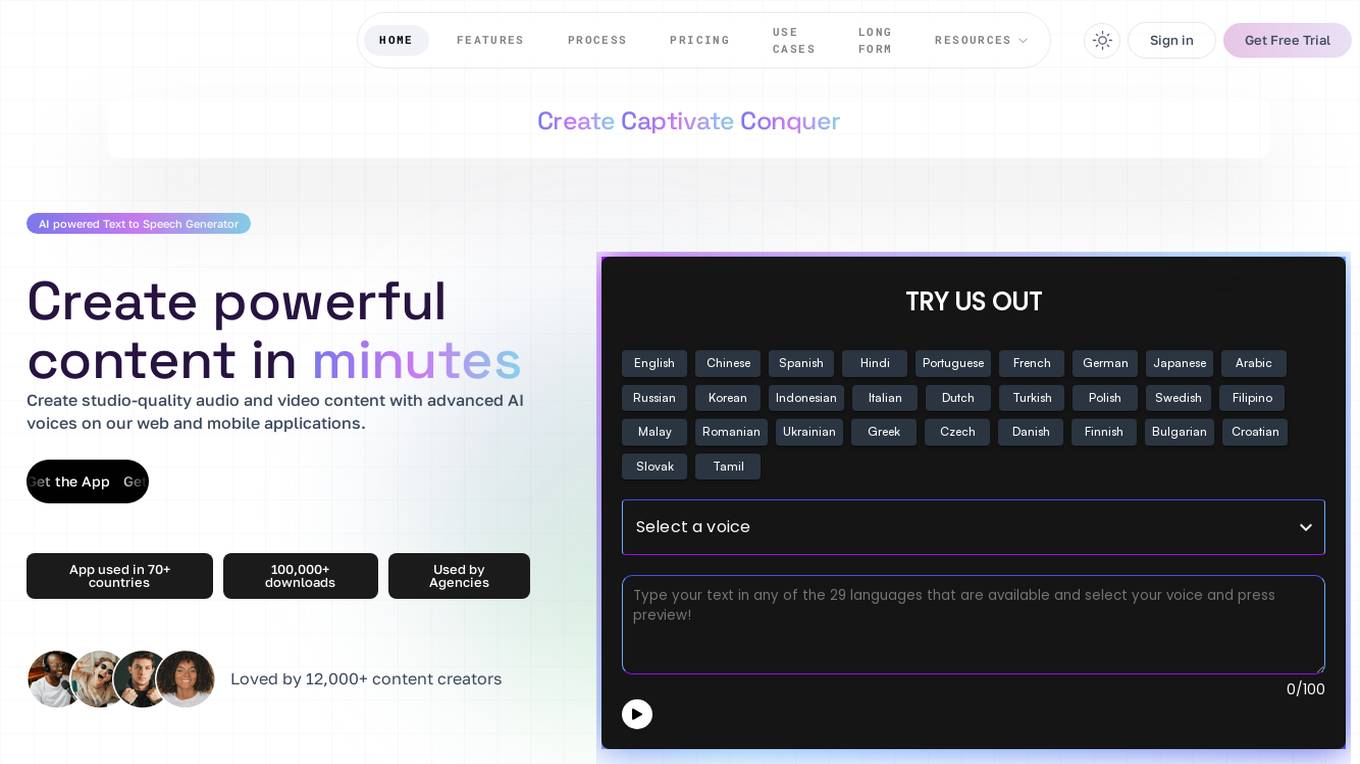
Voice Air
Voice Air is an AI-powered Text to Speech Generator that allows users to create studio-quality audio and video content with advanced AI voices on web and mobile applications. It offers cutting-edge features to enhance content creation, such as human-like voiceovers, award-winning music library, and AI features for content scaling. Voice Air is used in 70+ countries, with 100,000+ downloads and is loved by 12,000+ content creators. The application aims to revolutionize content creation by providing high-quality, natural-sounding voices and innovative features.
1 - Open Source Tools

Applio
Applio is a VITS-based Voice Conversion tool focused on simplicity, quality, and performance. It features a user-friendly interface, cross-platform compatibility, and a range of customization options. Applio is suitable for various tasks such as voice cloning, voice conversion, and audio editing. Its key features include a modular codebase, hop length implementation, translations in over 30 languages, optimized requirements, streamlined installation, hybrid F0 estimation, easy-to-use UI, optimized code and dependencies, plugin system, overtraining detector, model search, enhancements in pretrained models, voice blender, accessibility improvements, new F0 extraction methods, output format selection, hashing system, model download system, TTS enhancements, split audio, Discord presence, Flask integration, and support tab.
20 - OpenAI Gpts
Anime Voice Match
Anime Voice Match, identifies anime characters similar to the user's voice.
Voice/Style/Tone AI Prompt Snippet Generator
Analyzes your writing and produces a prompt snippet you can use in any other prompt to guide AI in replicating your voice, style, and tone. Just provide the text in the prompt box or in a document (don't use a link or image). You don't need to write any additional prompt language with your text.


Voice Memo
Record your thoughts with ChatGPT Voice Conversations 💡. Get started by clicking the 🎧 icon right to the chat input. Available on mobile only. Ask 'how do you work?' to learn more.
Vedic Voice
A scholar in Hindu literature providing positive, brief insights against negativity.

Skillful Voice
Premier expert in household management, offering unparalleled advice and guidance.


Earth Conscious Voice
Hi ;) Ask me for data & insights gathered from an environmentally aware global community
Bring Your Writing Voice to Every Task
This GPT will help you recreate your writing voice across multiple tasks. All you need is a prior writing sample (email, blog, article, tweet) and a new task.
Passive to Active Voice Text Converter AI
I convert and rewrite passive voice text into active voice tone and language. Simply put your passive voice text below! Perfect for sentences, paragraphs, daily emails, and longer texts.