Best AI tools for< Voice Actress >
Infographic
20 - AI tool Sites
Narrify AI
Narrify AI is an AI-powered application that transforms your videos by adding sports commentary to them. With Narrify AI, users can upload any video file up to 45 seconds in length and enhance it with personalized commentary, highlighting names and key words. The application allows users to create engaging and fun narrated videos to share with friends and family. Narrify AI is a user-friendly tool that adds a unique touch to your videos, making them more entertaining and memorable.

Voice.ai
Voice.ai is a free real-time voice changer and the largest ecosystem of free AI voice tools. With Voice.ai, you can change your voice in real-time, clone voices, create soundboards, and more. Voice.ai is perfect for streamers, content creators, gamers, and anyone who wants to have fun with their voice.

Voice-Swap
Voice-Swap is an AI voice transformation tool designed for musicians and creators. It allows users to create custom AI voice models using the Model Studio, share them via a free VST Plugin, and embed AI voices in apps using the API. With high-quality AI voices, Voice-Swap has gained popularity among professional creators and companies. The platform offers a range of features and benefits for transforming voices with AI, making it a valuable tool for music production and content creation.

Controlla Voice
Controlla Voice is an AI application that allows users to transform vocals into new voices or instruments, swap any song to their own voice in any language, and create unique blended voices. Users can train their own AI singing voice, generate AI cover songs, and create realistic choirs with customizable harmonies. The application provides a vocal toolkit for never-before-heard sounds and offers flexible pricing options to access high-quality AI singing voices. With Controlla Voice, users can enhance their voice, express themselves in their most natural way, and monetize their music with automatic royalties.
AI Voice Detector
AI Voice Detector is an AI tool designed to protect individuals and businesses from audio manipulation and AI-generated voices. It offers a high accuracy rate in identifying real voices versus AI-generated ones, integrated features to remove background noise and music, and the ability to detect AI cloned voices from various platforms. The tool can be used to scan voices on popular platforms like Youtube, WhatsApp, Tiktok, Zoom, and Google Meet. It helps individuals verify voice messages and calls to prevent falling victim to AI voice scams, while also assisting businesses in authenticating audio messages, calls, and meetings to avoid financial losses.
Voice Air
Voice Air is an AI-powered Text to Speech Generator that allows users to create studio-quality audio and video content with advanced AI voices on web and mobile applications. It offers cutting-edge features to enhance content creation, such as human-like voiceovers, award-winning music library, and AI features for content scaling. Voice Air is used in 70+ countries, with 100,000+ downloads and is loved by 12,000+ content creators. The application aims to revolutionize content creation by providing high-quality, natural-sounding voices and innovative features.
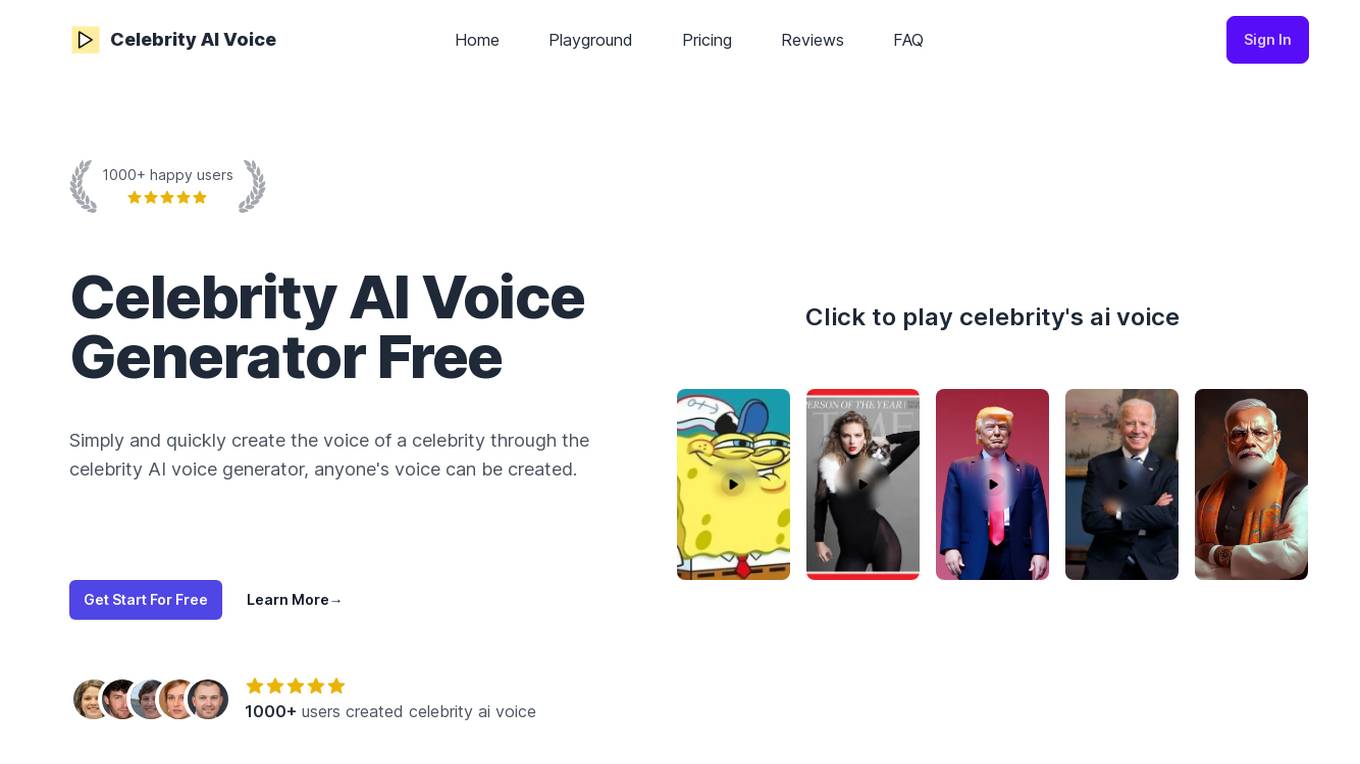
Celebrity AI Voice Generator
Celebrity AI Voice Generator is a free online tool that allows you to create realistic AI-generated voices of celebrities. With just a short audio clip of the person you want to replicate, you can generate voices that sound incredibly real. The tool is easy to use and offers a variety of features, including the ability to control voice styles, emotions, and accents. You can also use the tool to generate voices in different languages. Celebrity AI Voice Generator is a powerful tool that can be used for a variety of purposes, including creating voiceovers, dubbing videos, and developing video games.
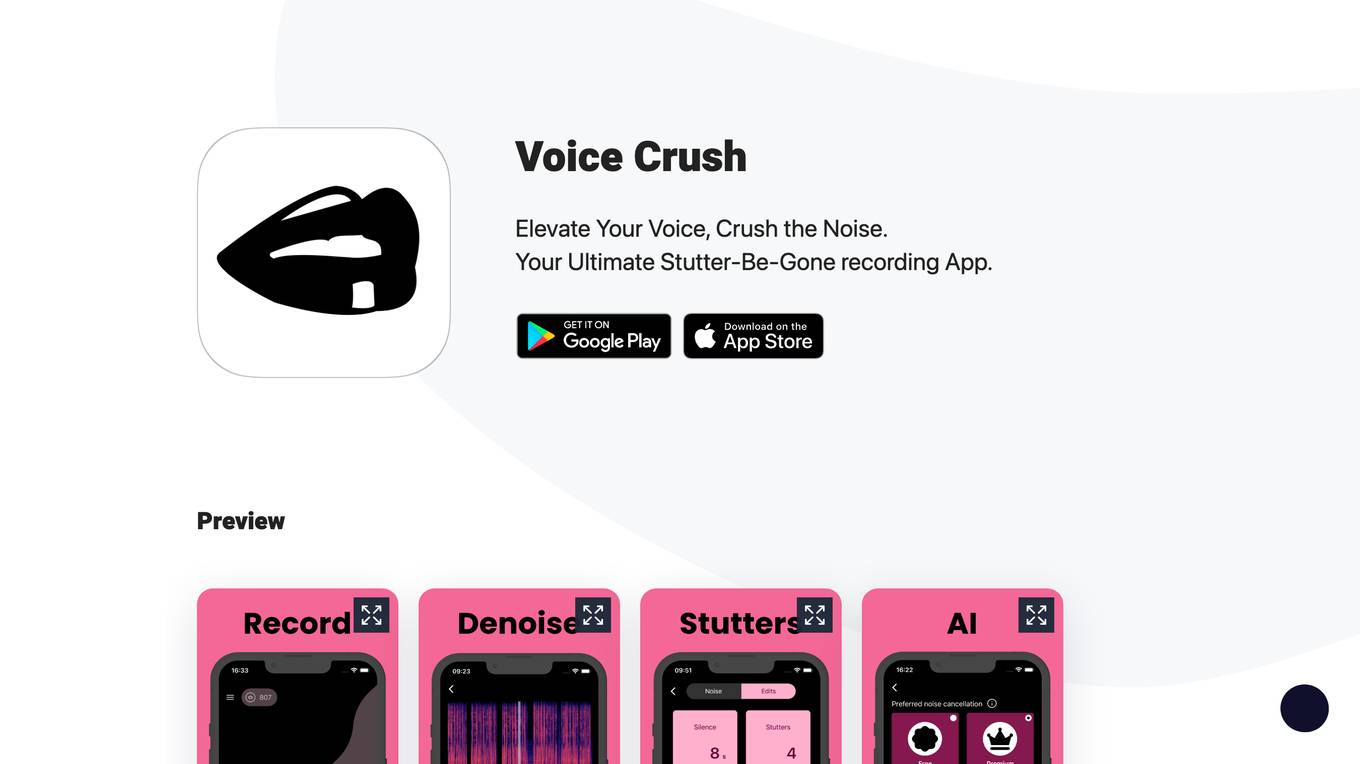
Voice Crush
Voice Crush is an AI-powered recording application designed to enhance audio quality by eliminating background noise and stuttering. It offers a user-friendly interface for individuals looking to improve their voice recordings in challenging acoustic environments. With state-of-the-art denoising AI technology, Voice Crush ensures that your voice stands out clearly in every recording. Whether you are a language learner or a professional seeking to deliver articulate messages, Voice Crush provides the tools to boost your confidence and improve the flow of your voice messages. Say goodbye to noisy backgrounds and stuttering with Voice Crush, your ultimate solution for high-quality audio recordings.
Voice AI Note
Voice AI Note is a web-based application that allows users to quickly and easily create voice notes using advanced AI. With Voice AI Note, you can create voice notes that are fluent, accurate, and sound natural. The application is easy to use and requires no prior experience with AI or voice recording. Simply enter the text you want to convert to speech, and Voice AI Note will do the rest.
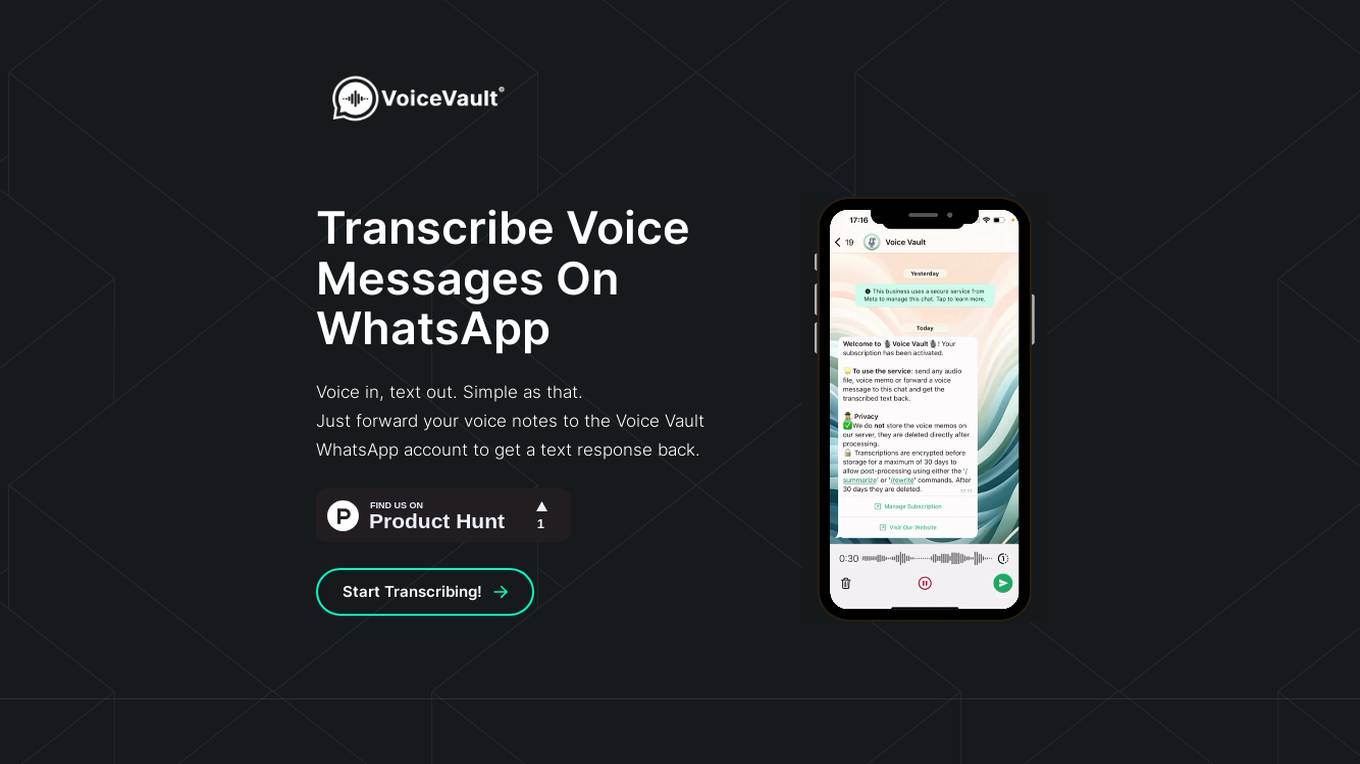
Voice Vault
Voice Vault is an AI tool that transcribes voice messages on WhatsApp. It allows users to forward voice notes to the Voice Vault WhatsApp account to receive a text response back. The application simplifies tasks such as searching through voice memos, content writing, note-taking, and more. Voice Vault offers two pricing plans with different features, including support for various audio formats and languages. The tool prioritizes user privacy by not storing voice memos and ensuring data is not used for training AI models.
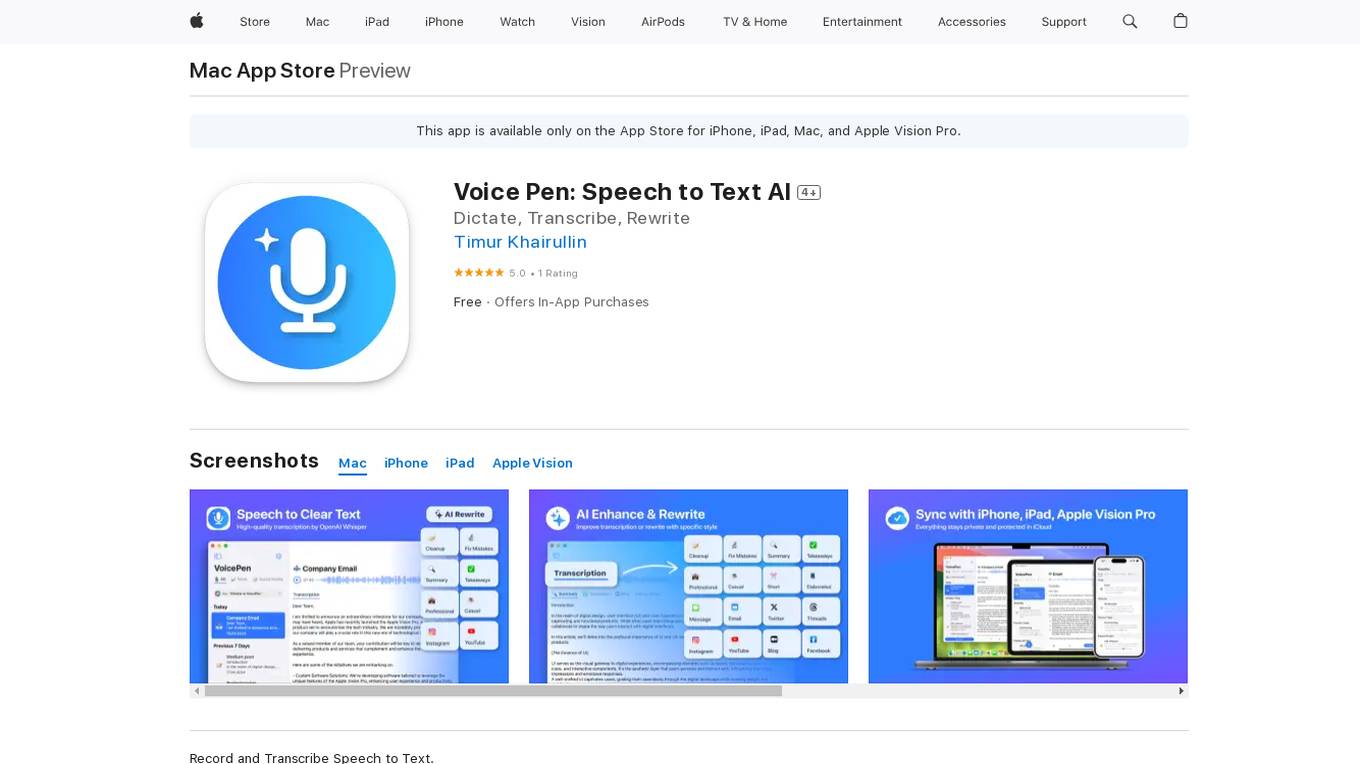
Voice Pen
Voice Pen is a Speech to Text AI application available on the App Store for Apple devices. It allows users to record and transcribe speech into text, which can then be used to create notes, summaries, emails, messages, and blog posts. The app supports more than 50 languages and offers AI options for rewriting and transforming text. Voice Pen enhances productivity by providing features like background audio recording, language autodetection, and the ability to create various types of content. It also prioritizes user privacy by only collecting app usage analytics and not storing any audio or text data on its servers.
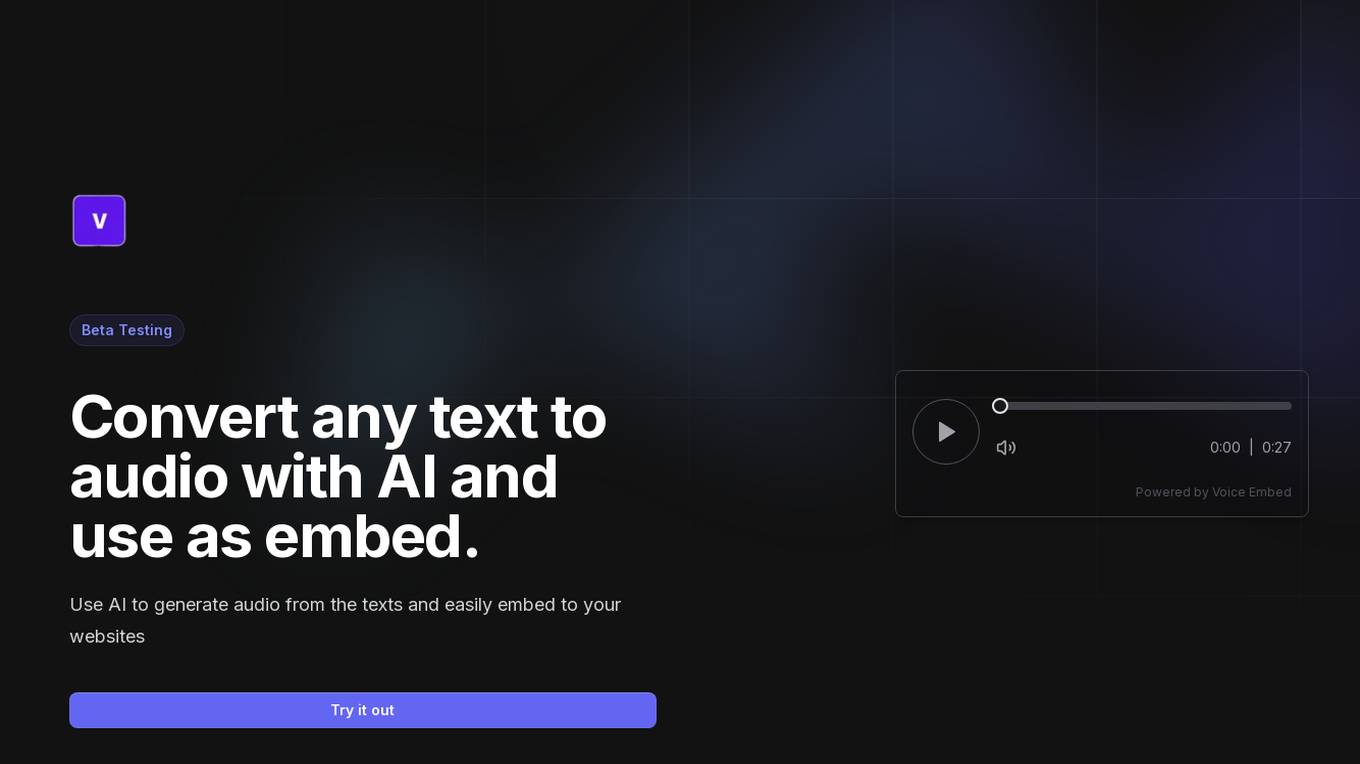
Voice Embed
Voice Embed is an AI tool that allows users to convert any text into audio using AI technology. Users can easily embed the generated audio into their websites, making the content more engaging and interactive. Voice Embed provides a one-click solution to create and share audio from articles, with free cloud storage for all generated audio files. The tool simplifies the process of adding audio to blogs and websites, offering a user-friendly experience for content creators.
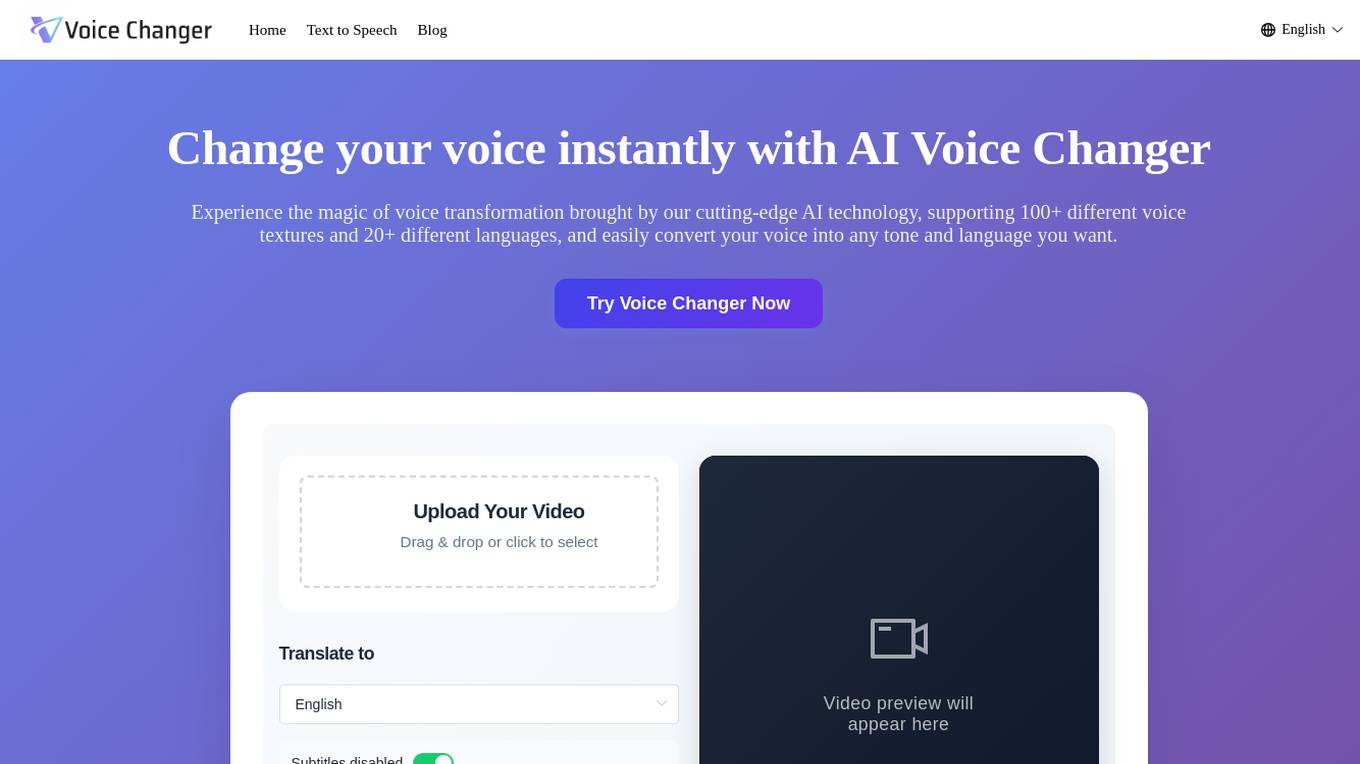
Voice Changer
Voice Changer is a free online tool powered by cutting-edge AI technology that allows users to instantly transform their voice into different tones and languages. With support for 100+ voice textures and 20+ languages, users can easily convert their voice for various purposes such as content creation, education, animation, marketing, and more. The tool offers natural and realistic voice transformations, making it ideal for a wide range of applications.
AI Voice Studio
AI Voice Studio is an innovative online tool that allows users to convert text into lifelike speech using advanced AI technology. With AI Voice Studio, users can easily create high-quality voiceovers for various purposes such as videos, podcasts, and presentations. The tool offers a user-friendly interface and a wide range of customization options to tailor the voice output to specific needs. Whether you are a content creator, marketer, or educator, AI Voice Studio provides a convenient and efficient solution for generating natural-sounding voice content.
Authors' Voice
Authors' Voice is a cutting-edge AI tool designed to convert text-based books into high-quality audiobooks efficiently and quickly. The platform utilizes state-of-the-art AI-based text-to-speech technology to provide clear and natural-sounding narration with varied pacing and inflection. Authors' Voice aims to cater to content creators, independent authors, and publishers by offering affordable and profitable solutions to tap into the fast-growing audiobook market.

Outer Voice AI
Outer Voice AI is a mobile application that provides users with an AI-powered coach. The coach can be used to get advice, support, or information on a variety of topics. The coach's responses are generated using artificial intelligence, and they are tailored to the user's individual needs. The coach's voice can also be customized to sound like the user's own voice.
Personal Voice and Vision Assistant
This AI-powered voice and vision assistant offers a range of features to enhance communication, productivity, and learning. Engage in natural voice conversations, get assistance with daily tasks, manage your schedule, and interact with visuals seamlessly. The assistant adapts to your needs, providing personalized support and advice. With its intuitive interface and affordable pricing, it's an ideal companion for individuals of all ages and interests.

AI Voice Generator
AI Voice Generator is a Telegram bot that converts text into audio using artificial intelligence. It offers a variety of neural voices, making it easy to create natural-sounding voiceovers. The bot is simple to use, and you can generate audio in seconds.
TikTok Voice
TikTok Voice is a free online AI text-to-speech tool that transforms text into various TikTok voices like the popular lady voice, Siri, Rocket, and Ghostface. Users can generate voices for video editing, text reading, and e-books. The tool offers a convenient way for video editing on PC and provides voices not available in the TikTok app. Users can easily choose the language and voice accent, type the text, generate the voice, and download it. For specific voice requests, users can email [email protected].
TikTok Voice Generator
TikTok Voice Generator is an AI tool that allows users to generate various AI voices for TikTok videos. Users can choose from a wide range of voice options including different languages, accents, genders, and characters. The tool provides a simple interface where users can input text and generate the desired voice within seconds. It is a free text-to-speech generator specifically designed for TikTok content creators.
0 - Open Source Tools
20 - OpenAI Gpts
Anime Voice Match
Anime Voice Match, identifies anime characters similar to the user's voice.
Voice/Style/Tone AI Prompt Snippet Generator
Analyzes your writing and produces a prompt snippet you can use in any other prompt to guide AI in replicating your voice, style, and tone. Just provide the text in the prompt box or in a document (don't use a link or image). You don't need to write any additional prompt language with your text.


Voice Memo
Record your thoughts with ChatGPT Voice Conversations 💡. Get started by clicking the 🎧 icon right to the chat input. Available on mobile only. Ask 'how do you work?' to learn more.
Vedic Voice
A scholar in Hindu literature providing positive, brief insights against negativity.

Skillful Voice
Premier expert in household management, offering unparalleled advice and guidance.


Earth Conscious Voice
Hi ;) Ask me for data & insights gathered from an environmentally aware global community
Bring Your Writing Voice to Every Task
This GPT will help you recreate your writing voice across multiple tasks. All you need is a prior writing sample (email, blog, article, tweet) and a new task.
Passive to Active Voice Text Converter AI
I convert and rewrite passive voice text into active voice tone and language. Simply put your passive voice text below! Perfect for sentences, paragraphs, daily emails, and longer texts.