Best AI tools for< Vocal Coach >
Infographic
20 - AI tool Sites
Vocalist.ai
Vocalist.ai is a cutting-edge AI-powered platform that empowers users to transform their vocals into world-class singers and rappers in a matter of seconds. With its innovative technology, users can leverage a diverse range of expertly curated and beautifully modeled vocalists and rappers covering multiple genres. This groundbreaking tool allows for effortless creation of both male and female versions of songs, or even the addition of rap features to enhance the musical experience. Vocalists.ai is committed to ethical AI practices, ensuring fair payment to artists and maintaining a low barrier to entry for creators. By balancing the goals of creators and artists, Vocalists.ai fosters a thriving ecosystem for emerging AI in the music industry.

Controlla Voice
Controlla Voice is an AI application that allows users to transform vocals into new voices or instruments, swap any song to their own voice in any language, and create unique blended voices. Users can train their own AI singing voice, generate AI cover songs, and create realistic choirs with customizable harmonies. The application provides a vocal toolkit for never-before-heard sounds and offers flexible pricing options to access high-quality AI singing voices. With Controlla Voice, users can enhance their voice, express themselves in their most natural way, and monetize their music with automatic royalties.

Voice-Swap
Voice-Swap is an AI voice transformation tool designed for musicians and creators. It allows users to create custom AI voice models using the Model Studio, share them via a free VST Plugin, and embed AI voices in apps using the API. With high-quality AI voices, Voice-Swap has gained popularity among professional creators and companies. The platform offers a range of features and benefits for transforming voices with AI, making it a valuable tool for music production and content creation.
Vocal Image
Vocal Image is an AI-powered coaching app that offers speech and communication lessons to help speakers and singers boost confidence and enhance the attractiveness of their voice. The app provides voice evaluations, educational content, specialized programs, and challenges designed to improve voice quality and communication skills. Users can record their voice, receive feedback from a community of voice enthusiasts, and engage with AI coach recommendations to achieve their voice goals.
Huru
Huru is the #1 AI-Powered Interview Prep App designed to help users ace their job interviews. It offers unlimited mock interviews with realistic, job-specific questions and provides instant, personalized feedback on answers, body language, and vocal delivery. With powerful features and integrations from popular job boards, Huru helps users build confidence, improve communication skills, and stand out in any interview scenario. The application covers diverse industries and roles, offering tailored interview questions and expert AI feedback to enhance interview performance. Huru is available on multiple platforms and languages, making it a comprehensive tool for job seekers at any career stage.

Moshi AI
Moshi AI is a new voice assistant with advanced vocal capabilities that simulate human-like conversations. It can be used as a personal coach or companion, providing guidance and support in various scenarios. Moshi AI offers real-time voice interaction, efficient multimodal processing, and enhanced privacy and security features. The application is designed to enhance business operations, improve customer interactions, and streamline decision-making processes.
Vocal Remover Oak
Vocal Remover Oak is an advanced AI tool designed for music producers, video makers, and karaoke enthusiasts to easily separate vocals and accompaniment in audio files. The website offers a free online vocal remover service that utilizes deep learning technology to provide fast processing, high-quality output, and support for various audio and video formats. Users can upload local files or provide YouTube links to extract vocals, accompaniment, and original music. The tool ensures lossless audio output quality and compatibility with multiple formats, making it suitable for professional music production and personal entertainment projects.
AudioStrip
AudioStrip is a free online vocal isolator that allows you to remove vocals from any song. It uses artificial intelligence to separate the vocals from the music, and it does a surprisingly good job. You can use AudioStrip to create a cappella versions of your favorite songs, or you can use it to isolate the vocals from a song so that you can sing along with them. AudioStrip is easy to use. Just upload a song to the website, and then click the "Extract Vocals" button. AudioStrip will then process the song and create a new file that contains only the vocals. You can then download the new file to your computer.

Moises
Moises is an AI-powered musician's app that allows users to remove vocals and instruments from any song. With Moises, musicians and music enthusiasts can isolate specific elements of a track for learning, remixing, or practicing purposes. The app utilizes advanced AI algorithms to provide high-quality audio separation, making it a valuable tool for music production and analysis. Moises offers a user-friendly interface and intuitive controls, making it accessible to both beginners and professionals in the music industry.
Frettable
Frettable is an AI-powered music transcription tool that allows musicians to convert their instrument recordings into MIDI and sheet music. With Frettable, musicians can play their instruments and have the AI instantly write the sheet music for them, saving them time and effort. Frettable is also polyphonic, meaning it can handle both notes and chords, and it can generate tabs for guitar and other stringed instruments. Frettable is available as a web app and as a mobile app, making it easy for musicians to use wherever they are.
Lamucal
Lamucal is an AI-powered platform that provides tabs and chords for any song. It offers real-time chords, lyrics, tabs, and melody for any song, making it a valuable tool for musicians and music enthusiasts. Users can upload songs or search for any song to access chords and other musical elements. With a user-friendly interface and a wide range of features, Lamucal aims to enhance the music learning and playing experience for its users.

AI Music Maker
AI Music Maker is an innovative online platform that harnesses the power of artificial intelligence to enable users to create music effortlessly. From generating full tracks, beats, and lyrics in seconds to providing tools like AI Lyrics Generator, AI Music Extender, and Vocal Remover, AI Music Maker simplifies the music production process for creators of all levels. With high-quality output options and a user-friendly interface, this platform offers a complete creative toolkit for music enthusiasts, professionals, and beginners alike.
Vozart AI Music & Lyrics Generator
Vozart.ai is an advanced AI music and lyrics generator platform that empowers users to create original music tracks, lyrics, voice clones, and more with the help of artificial intelligence technology. The platform offers a wide range of features, from music composition tools to vocal removal and stem splitting capabilities, making professional music production accessible to both beginners and experienced musicians. Vozart.ai revolutionizes the music creation process by providing a seamless and intuitive online experience, allowing users to generate high-quality, royalty-free music tracks in seconds.
Media.io
Media.io is an online platform offering a wide range of AI tools for video, audio, and image editing. Users can easily enhance their creative projects with features like AI Portrait Generator, AI Video Generator, Video Editor, Image Enhancer, and more. The platform provides a drag-and-drop interface, flexible editing options, a vast template library, and powerful AI tools, all accessible directly from the browser. Media.io aims to redefine video creation by providing smart editing solutions for creators in various fields such as business, marketing, social media, and entertainment.
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
Narrify AI
Narrify AI is an AI-powered application that transforms your videos by adding sports commentary to them. With Narrify AI, users can upload any video file up to 45 seconds in length and enhance it with personalized commentary, highlighting names and key words. The application allows users to create engaging and fun narrated videos to share with friends and family. Narrify AI is a user-friendly tool that adds a unique touch to your videos, making them more entertaining and memorable.
LALAL.AI
LALAL.AI is a next-generation vocal remover and music source separation service that offers fast, easy, and precise stem extraction. It allows users to remove vocals, instrumental tracks, drums, bass, guitar, and more without quality loss. The platform uses advanced AI technology to provide high-quality stem splitting based on transformer-based audio separation approach. Users can create custom voices, remove background noise, change voices, and separate lead and backing vocals with pinpoint accuracy. LALAL.AI offers various packages for individuals and businesses, with features like fast processing queue, batch upload, and stem download. The service supports a wide range of input/output formats for audio and video files.

Emvoice
Emvoice is a cutting-edge vocal synthesis platform that empowers users to create realistic and expressive synthetic voices. With its advanced AI algorithms and intuitive interface, Emvoice makes it easy to generate high-quality voiceovers, audiobooks, and other audio content. Whether you're a professional voice actor, a content creator, or simply looking to add a touch of personality to your projects, Emvoice has the tools you need to bring your words to life.
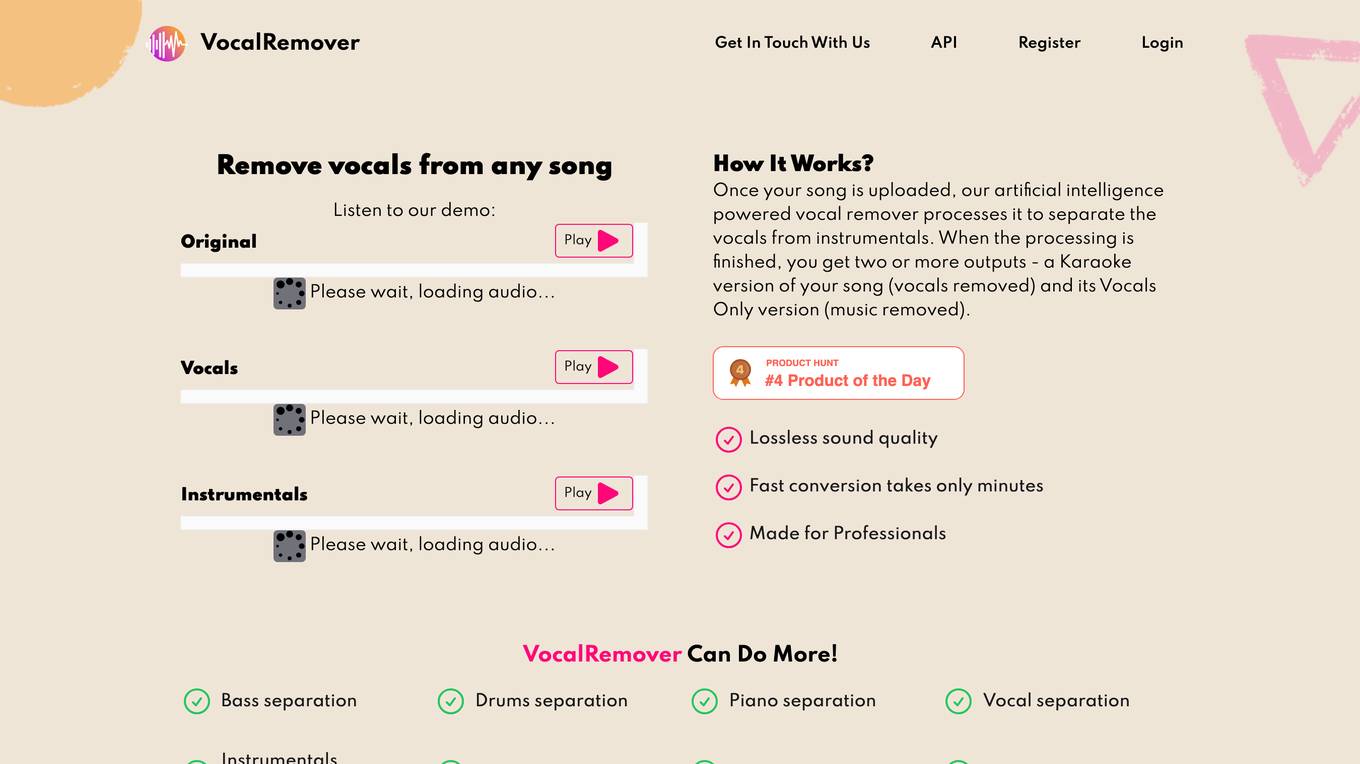
VocalRemover
VocalRemover is an online tool that uses artificial intelligence to remove vocals from any music track. It is easy to use, simply upload your song and the AI will process it to separate the vocals from the instrumentals. You can then download the resulting karaoke version or vocals-only version of your song. VocalRemover is a great tool for musicians, singers, and anyone who wants to create their own karaoke tracks.
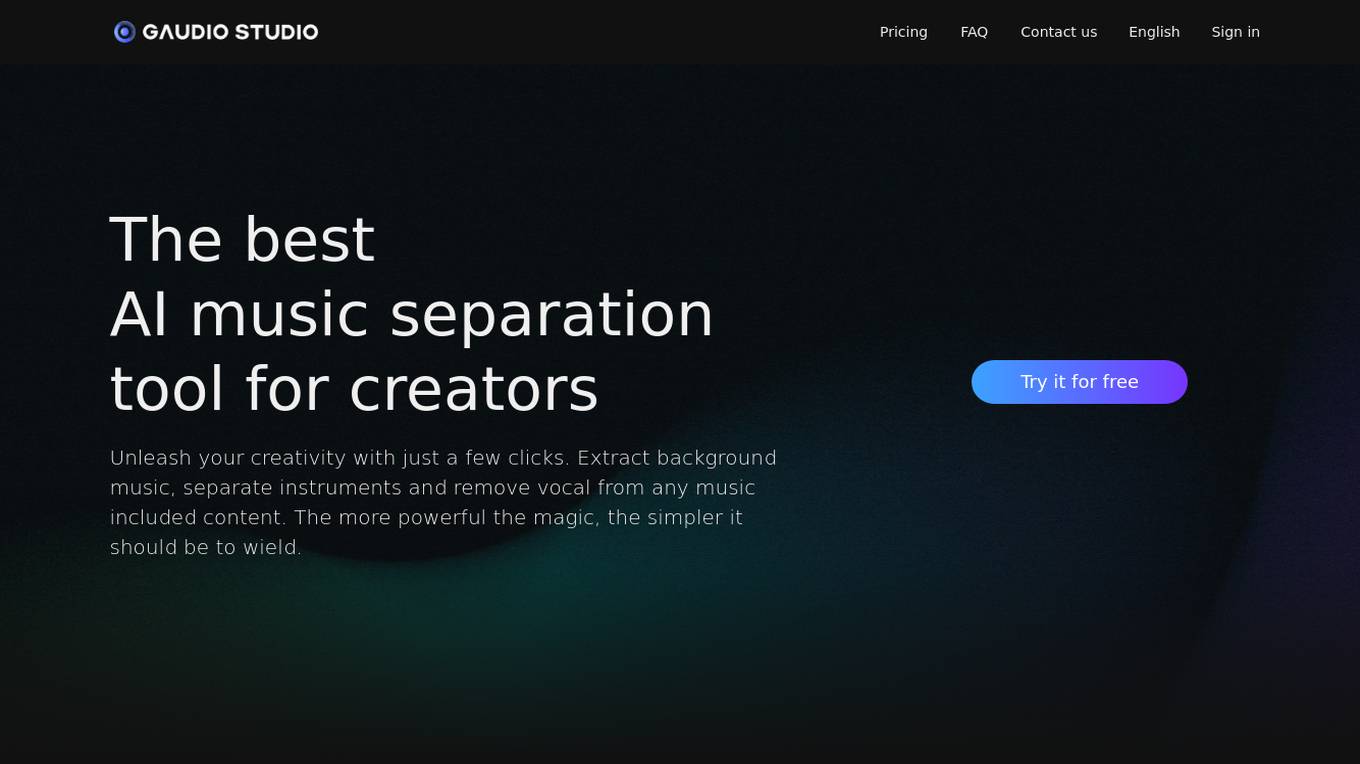
Gaudio Studio
Gaudio Studio is an AI music separation tool designed for creators to unleash their creativity with ease. It allows users to extract background music, separate instruments, and remove vocals from any music content. Powered by GSEP (Gaudio source SEParation), a high-quality and easy-to-use AI stem separation model, Gaudio Studio offers a seamless experience for audio separation. Users can upload their songs in various formats, access the tool from desktop or mobile devices, and enjoy Studio Plans for advanced processing. Additionally, Gaudio Studio can be integrated with cloud APIs and On-device SDKs for business applications, offering a versatile solution for music professionals and enthusiasts.
0 - Open Source Tools
20 - OpenAI Gpts

Academia de Rock
Tutor virtual de rock entusiasta y amigable, adaptando lecciones y ejercicios al nivel del alumno.

SpeechTherapist GPT
Your very own speech therapy assistant. Completely private and confidential.
JLPT Vocab Quiz Master
Drills Japanese students on JLPT vocabulary and tracks progression reinforced via spaced repetition
German Vocab Helper
Provides images, examples, and structured grammar tables for German vocabulary.
GRE Word Tutor
Teaches GRE vocab through personalized stories and thoughtful questions, featuring GregMat


MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Studio Wizard
Home studio recording magician, offering equipment, technique, mixing advice, and the occasional spell. Use the Message box at the bottom for your own questions.