Best AI tools for< Vision Therapist >
Infographic
20 - AI tool Sites
Seeing AI
Seeing AI is a free app designed for the blind and low vision community. It utilizes AI technology to narrate the world around users, assisting with tasks such as reading, describing photos, and identifying products. The app is an ongoing research project that evolves based on feedback from the community and advancements in AI research.
AI VisionBoard Launch App
AI VisionBoard Launch App is an AI-powered application that allows users to create personalized vision boards to visualize their dreams and aspirations. Users can quickly visualize their dreams in seconds by typing them out or using random prompt ideas. The app also enables users to add their photos and see themselves in their dreams. Additionally, users can explore a community of shared dreams, share their vision board creations, and connect with like-minded individuals. The app also features an AI Life Coach chat function for personal growth and well-being support, providing users with a 24/7 companion. AI VisionBoard aims to help users turn their aspirations into reality through visualization and community support.
PocketCoach
PocketCoach is an online AI-powered learning platform designed for athletes worldwide who aim to enhance their sports skills. The platform utilizes cutting-edge AI and computer vision technology to provide gamified drills, comprehensive analytics, and real-time feedback to help athletes break through plateaus and achieve faster results. PocketCoach also offers an innovative computer vision app called Playi, which transforms practice sessions by offering real-time analysis and personalized feedback on technique using a smartphone's camera.
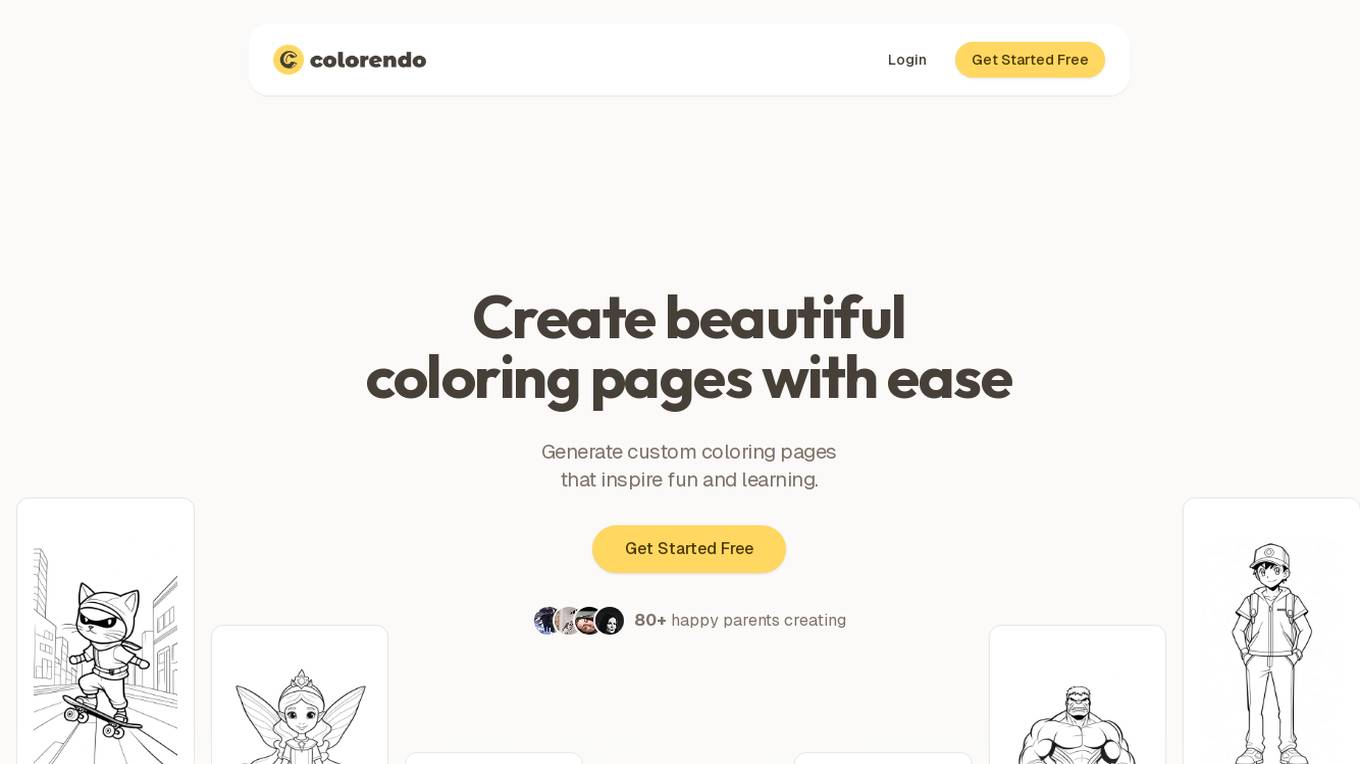
Colorendo
Colorendo is an AI coloring page generator that allows users to create custom coloring pages effortlessly. By simply describing an idea and clicking 'Generate', the AI brings the vision to life in seconds, catering to parents seeking engaging and educational activities for children. With versatile designs suitable for all ages and skill levels, Colorendo offers flexible subscription options and a free trial to explore the magic of AI-generated coloring pages.
Kaia Health
Kaia Health is a digital therapy platform for musculoskeletal (MSK) pain. It combines human care with technology to provide personalized, evidence-based care. Kaia's platform includes a variety of features, such as automated feedback, coaching, and medical support. It has been shown to be effective in reducing pain, improving function, and reducing the need for surgery and pain medication.
BookHero
BookHero is an online platform that provides parents with a library of over 100 books to read to their children. Parents can also create their own books in just minutes using BookHero's WordPics illustrations. WordPics are beautiful illustrations that help children improve their vocabulary and spelling.
PolygrAI
PolygrAI is a digital polygraph powered by AI technology that provides real-time risk assessment and sentiment analysis. The platform meticulously analyzes facial micro-expressions, body language, vocal attributes, and linguistic cues to detect behavioral fluctuations and signs of deception. By combining well-established psychology practices with advanced AI and computer vision detection, PolygrAI offers users actionable insights for decision-making processes across various applications.
AI Image to Music Generator
AI Image to Music Generator is a tool that uses artificial intelligence to convert images into music. It analyzes various visual elements in the image using computer vision and generates diverse musical compositions in different genres and styles. The tool offers a simple operation interface, fast generation process, and no login requirement, providing users with the freedom to experiment with music creation. AI Image to Music Generator has applications in media & entertainment, advertising & marketing, personalized gifts, therapeutic tools, education, and casual creativity.
Joseph Chet Redmon's Computer Vision Platform
The website is a platform maintained by Joseph Chet Redmon, a graduate student working on computer vision. It features information on his projects, publications, talks, and teaching activities. The site also includes details about the Darknet Neural Network Framework, tactics in Coq, and research work. Visitors can learn about computer vision, object recognition, and visual question answering through the resources provided on the site.
Tangram Vision
Tangram Vision is a company that provides sensor calibration tools and infrastructure for robotics and autonomous vehicles. Their products include MetriCal, a high-speed bundle adjustment software for precise sensor calibration, and AutoCal, an on-device, real-time calibration health check and adjustment tool. Tangram Vision also offers a high-resolution depth sensor called HiFi, which combines high-resolution depth data with high-powered AI capabilities. The company's mission is to accelerate the development and deployment of autonomous systems by providing the tools and infrastructure needed to ensure the accuracy and reliability of sensors.
Custom Vision
Custom Vision is a cognitive service provided by Microsoft that offers a user-friendly platform for creating custom computer vision models. Users can easily train the models by providing labeled images, allowing them to tailor the models to their specific needs. The service simplifies the process of implementing visual intelligence into applications, making it accessible even to those without extensive machine learning expertise.
Apex Vision AI
Apex Vision AI is an AI-powered homework helper that provides instant answers and assistance to college students. It utilizes advanced machine learning algorithms to generate accurate answers for multiple-choice homework and quizzes, saving students time and boosting their confidence. The extension seamlessly integrates into the user's browser, offering real-time answers with a click or keyboard shortcut. Its user-friendly interface and intuitive design make it easy for students to use, helping them study smarter and not harder.

Japan Computer Vision (JCV)
Japan Computer Vision (JCV) is a leading technology company specializing in advanced computer vision solutions (image recognition). As a 100% subsidiary of SoftBank Corp., JCV focuses on security and innovation to provide cutting-edge technologies that transform industries and improve lives worldwide. Through solutions for smart buildings and smart retail, JCV enhances office environments, streamlines operations, improves hospitality in stores and commercial facilities, and creates new work and lifestyle experiences.

Big Vision
Big Vision provides consulting services in AI, computer vision, and deep learning. They help businesses build specific AI-driven solutions, create intelligent processes, and establish best practices to reduce human effort and enable faster decision-making. Their enterprise-grade solutions are currently serving millions of requests every month, especially in critical production environments.
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.

Edge AI and Vision Alliance
The Edge AI and Vision Alliance is a platform that provides practical technical insights and expert advice for developers building AI or vision-enabled products. It offers information on the latest vision, AI, and deep learning technologies, standards, market research, and applications. The Alliance aims to help users incorporate visual and artificial intelligence into their products effectively and efficiently.
Personal Voice and Vision Assistant
This AI-powered voice and vision assistant offers a range of features to enhance communication, productivity, and learning. Engage in natural voice conversations, get assistance with daily tasks, manage your schedule, and interact with visuals seamlessly. The assistant adapts to your needs, providing personalized support and advice. With its intuitive interface and affordable pricing, it's an ideal companion for individuals of all ages and interests.

Recognito
Recognito is a leading facial recognition technology provider, offering the NIST FRVT Top 1 Face Recognition Algorithm. Their high-performance biometric technology is used by police forces and security services to enhance public safety, manage individual movements, and improve audience analytics for businesses. Recognito's software goes beyond object detection to provide detailed user role descriptions and develop user flows. The application enables rapid face and body attribute recognition, video analytics, and artificial intelligence analysis. With a focus on security, living, and business improvements, Recognito helps create safer and more prosperous cities.
AIM Intelligent Machines
AIM Intelligent Machines is an AI application that transforms existing heavy equipment into autonomous fleets, enhancing safety and productivity in mining and construction operations. The AIM Technology Platform offers a rugged plug-and-play solution for various heavy equipment fleets, enabling partners to transition to autonomous operation seamlessly. The solution ensures continuous peak performance of heavy equipment, even in challenging weather conditions, leading to maximally safe operational sites and improved efficiency. AIM is fully insured for autonomous operation and empowers employees to upskill in site planning, remote management, and data analytics.
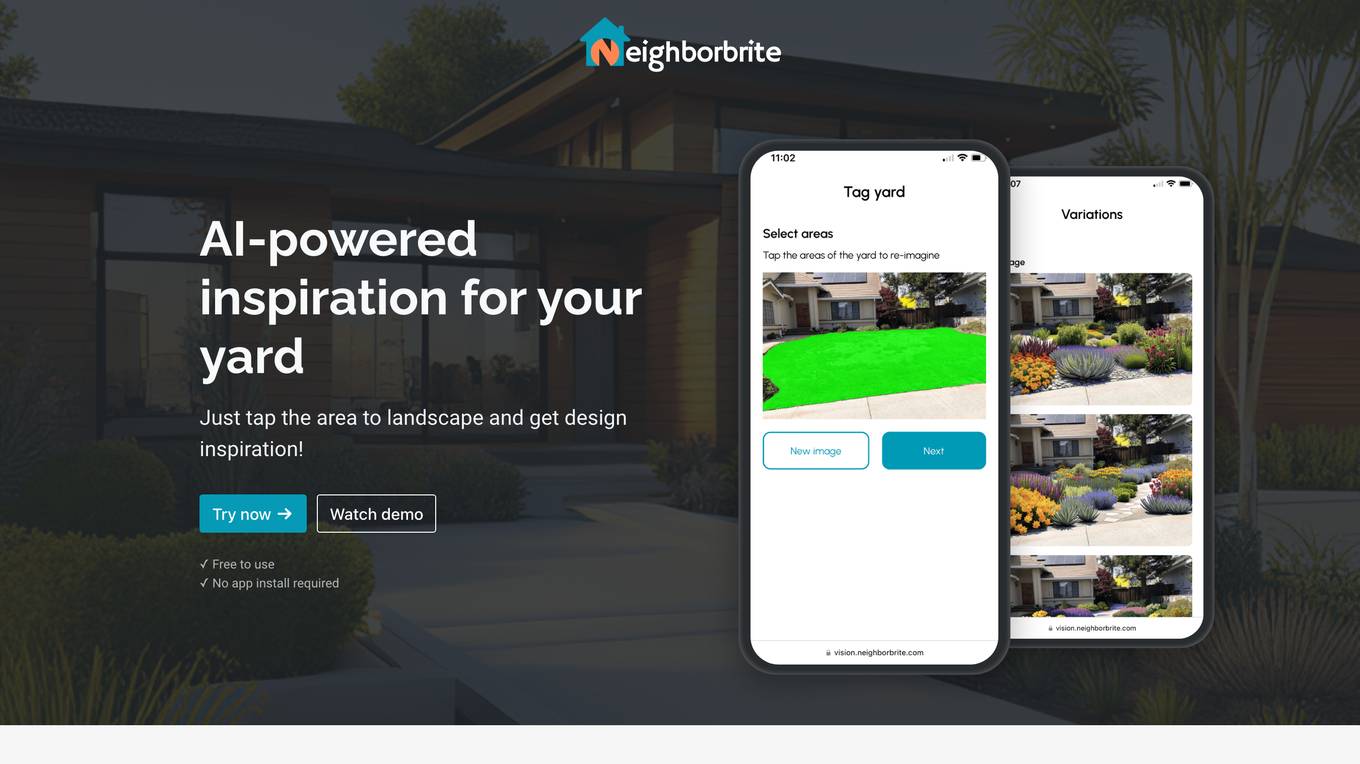
Neighborbrite
Neighborbrite is a free AI landscape design tool that empowers users to transform their yards with AI-powered design. It is designed for everyone who desires a beautiful garden with just a simple tap. Users can upload a photo of their yard, select from various garden styles, and customize details to match their vision. The tool offers location-based plant suggestions and allows for customization of specific garden elements, providing a personalized and easy-to-use experience for creating dream outdoor spaces.
0 - Open Source Tools
20 - OpenAI Gpts
Eye Care
Specialist in vision care, offering eye health tips and information on eye conditions.

Opto assistent
Assists optometrists with answers and support in their daily work, in English and Estonian.
Dream Weaver
See what you dream. Transform night visions into vivid artwork and unlock the secrets of your subconscious.



Landmark Vision Identifier
Analyzes images to identify landmarks and shares historical insights and captivating facts.
The Future Business Vision Bot
Let me help you create a vision for the future business of your dreams.

Pixie: Computer Vision Engineer
Expert in computer vision, deep learning, ready to assist you with 3d and geometric computer vision. https://github.com/kornia/pixie
Dream Vision Board
Describe what you would like to include in your ultimate vision or dream board and I will generate it for you.