Best AI tools for< Test Takers >
Infographic
20 - AI tool Sites
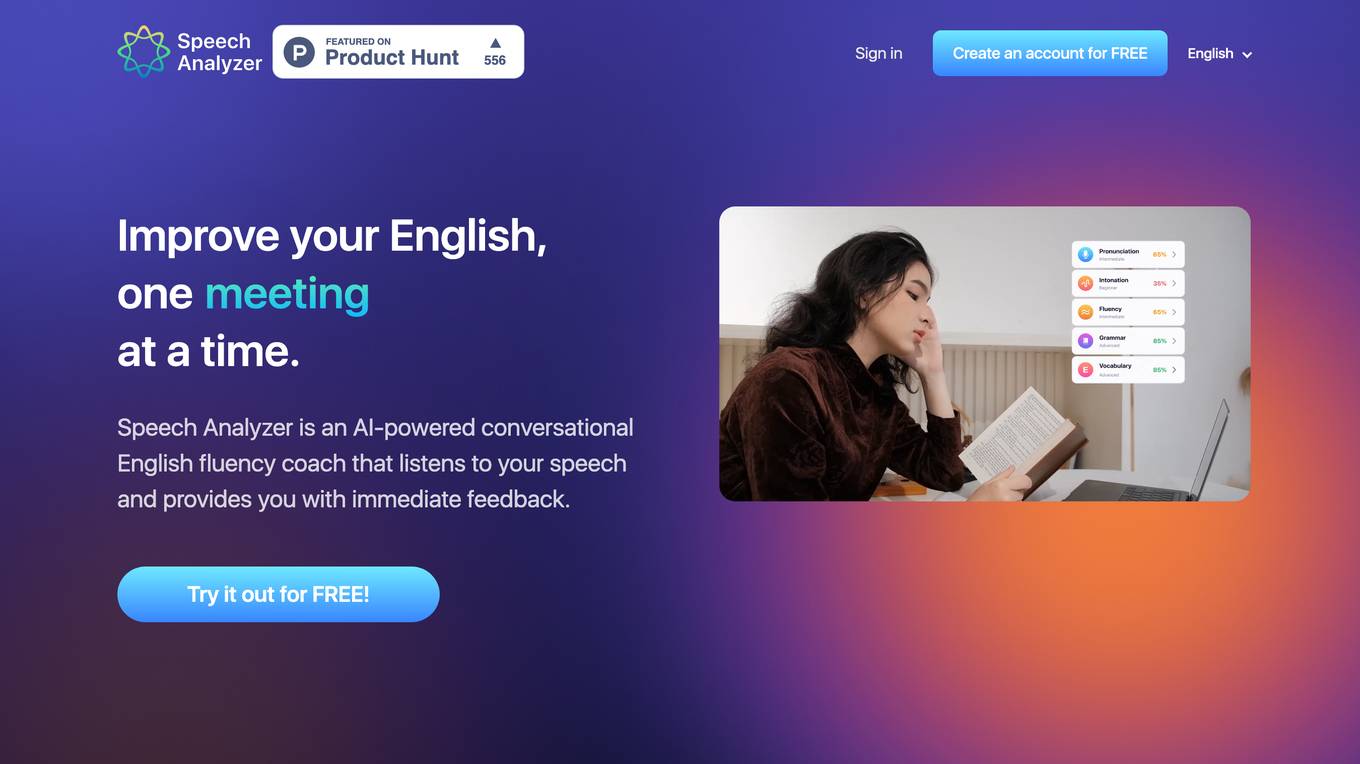
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on your speech. It helps users improve their pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English speaking skills and communication abilities.
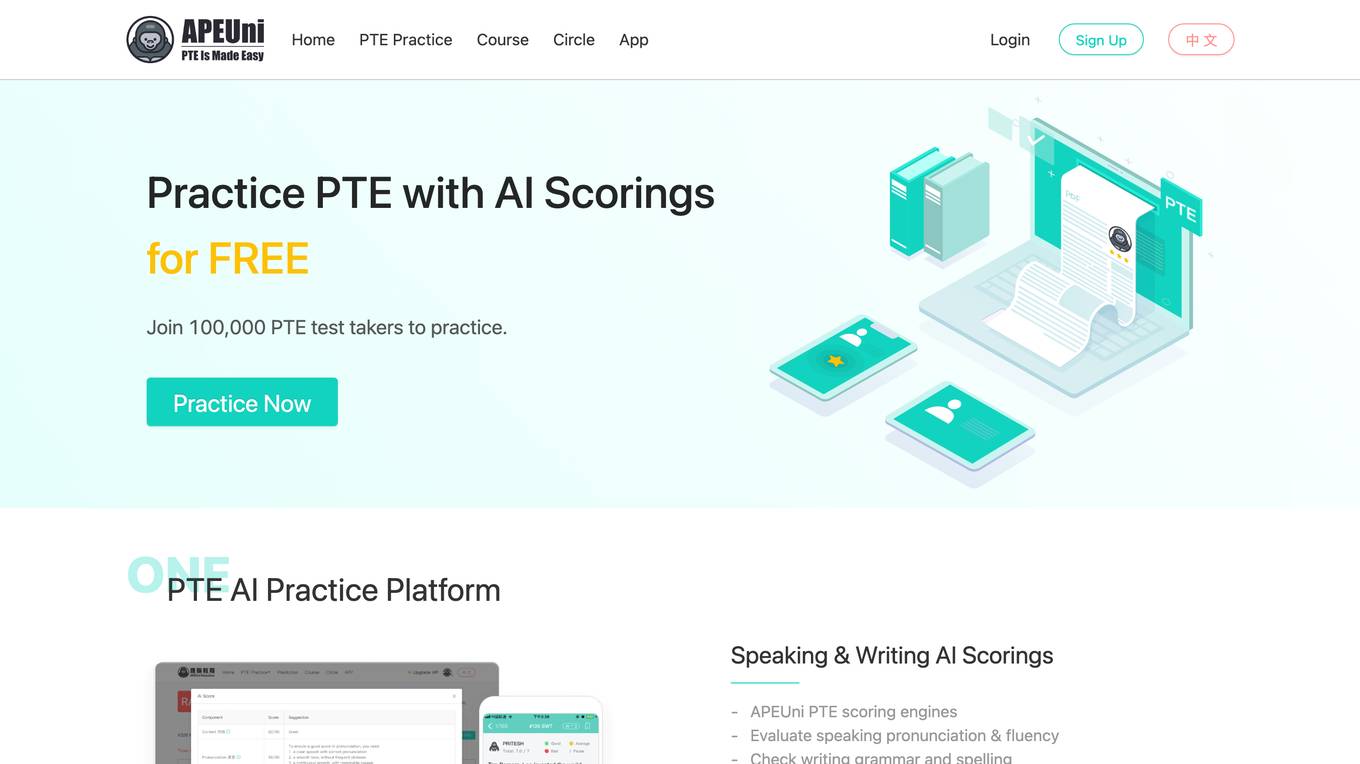
APEUni
APEUni is an AI-powered platform designed to help users practice for the Pearson Test of English (PTE) exam. It offers various AI scoring features for different sections of the PTE exam, such as Speaking, Writing, Reading, and Listening. Users can access practice materials, study guides, and receive detailed score reports to improve their performance. APEUni aims to provide a comprehensive and efficient way for PTE test takers to prepare for the exam.
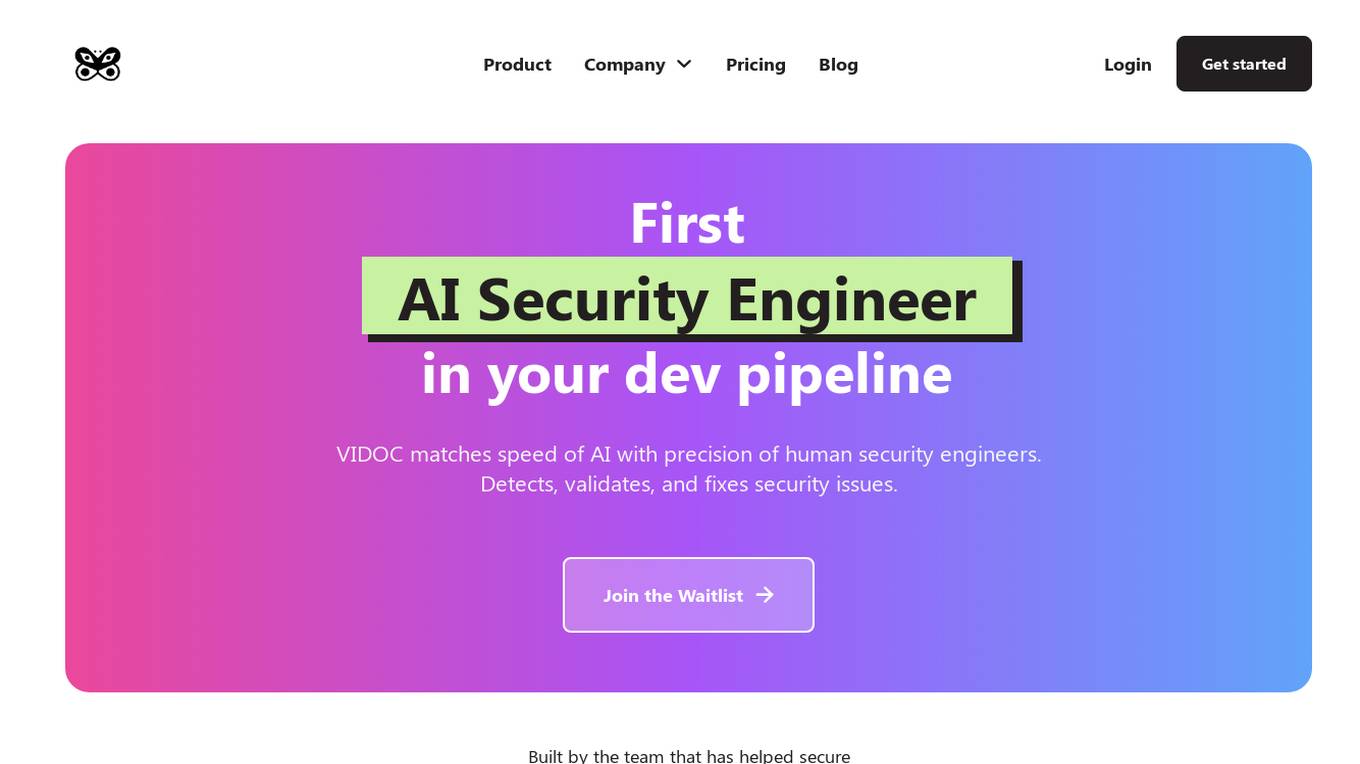
VIDOC
VIDOC is an AI-powered security engineer that automates code review and penetration testing. It continuously scans and reviews code to detect and fix security issues, helping developers deliver secure software faster. VIDOC is easy to use, requiring only two lines of code to be added to a GitHub Actions workflow. It then takes care of the rest, providing developers with a tailored code solution to fix any issues found.
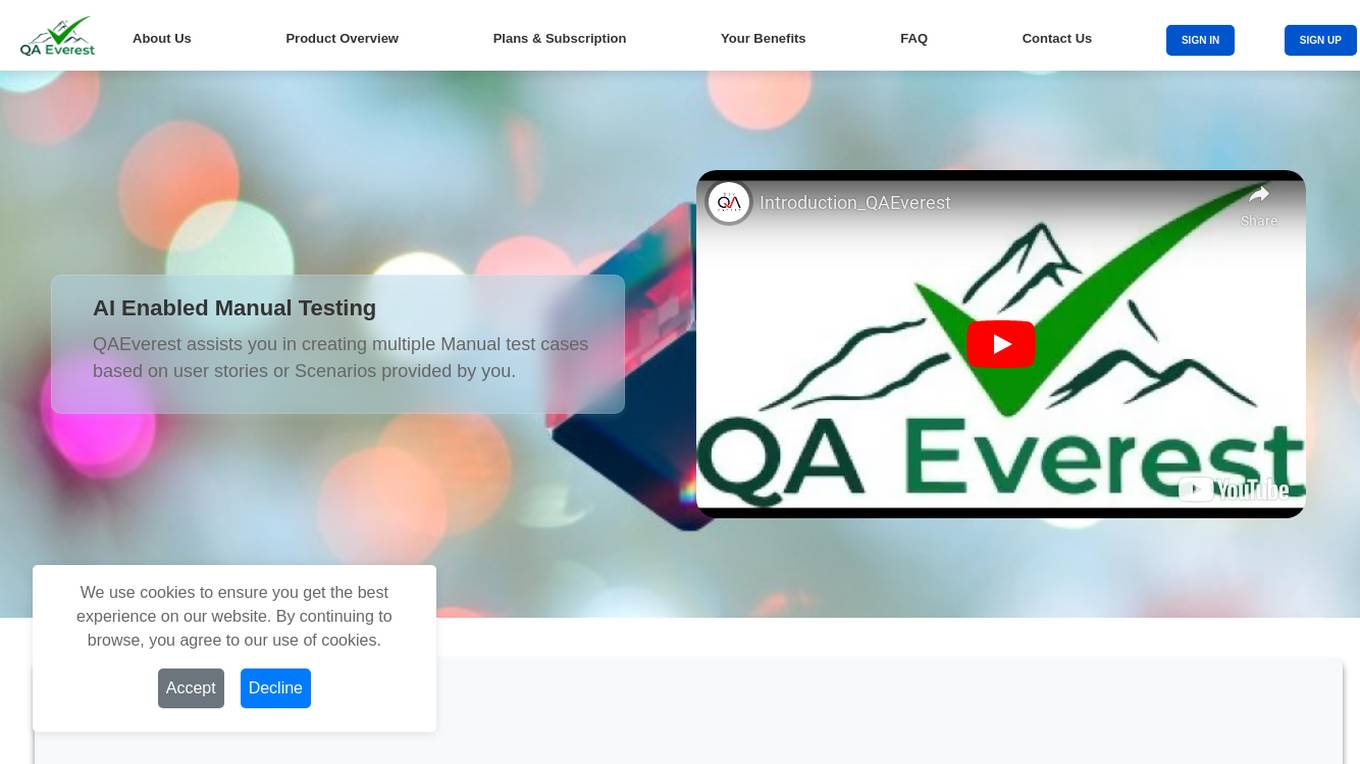
AI Generated Test Cases
AI Generated Test Cases is an innovative tool that leverages artificial intelligence to automatically generate test cases for software applications. By utilizing advanced algorithms and machine learning techniques, this tool can efficiently create a comprehensive set of test scenarios to ensure the quality and reliability of software products. With AI Generated Test Cases, software development teams can save time and effort in the testing phase, leading to faster release cycles and improved overall productivity.

AI Test Kitchen
AI Test Kitchen is a website that provides a variety of AI-powered tools for creative professionals. These tools can be used to generate images, music, and text, as well as to explore different creative concepts. The website is designed to be a place where users can experiment with AI and learn how to use it to enhance their creative process.
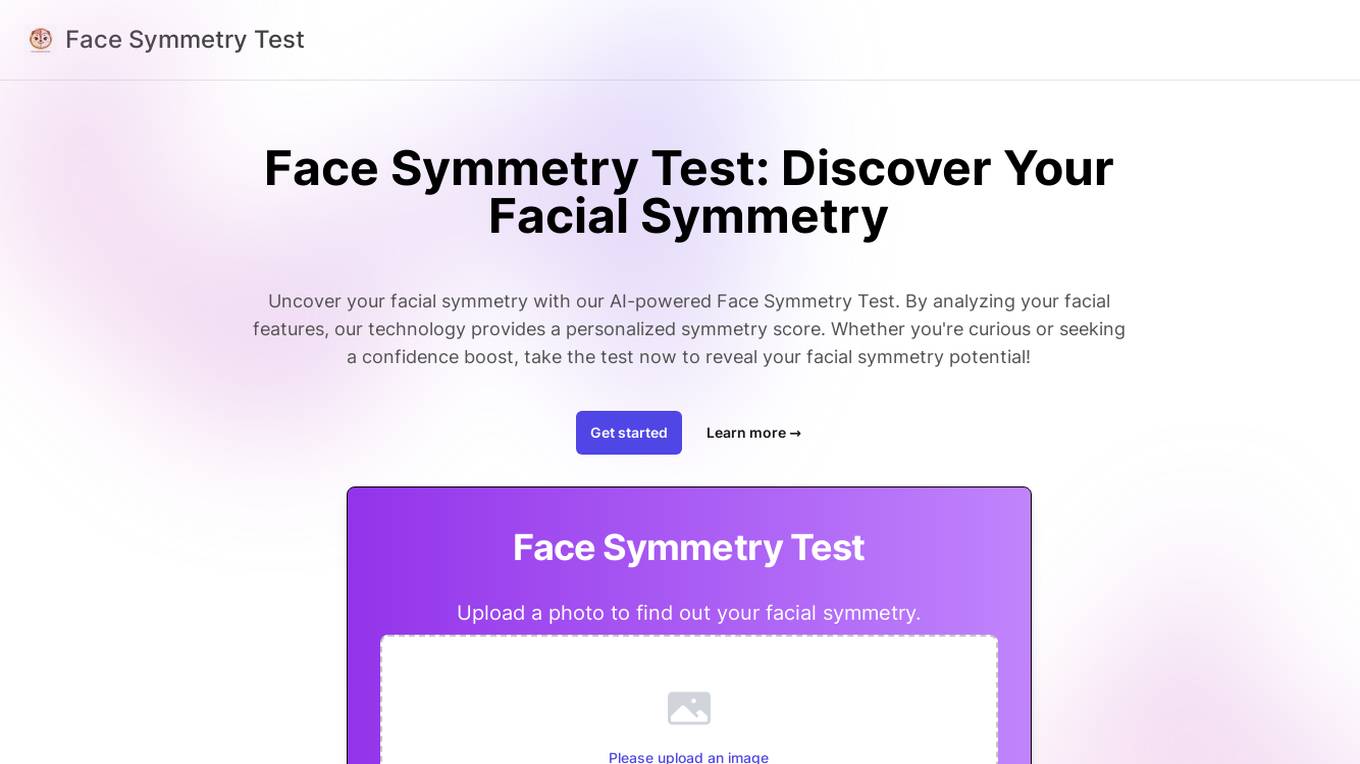
Face Symmetry Test
Face Symmetry Test is an AI-powered tool that analyzes the symmetry of facial features by detecting key landmarks such as eyes, nose, mouth, and chin. Users can upload a photo to receive a personalized symmetry score, providing insights into the balance and proportion of their facial features. The tool uses advanced AI algorithms to ensure accurate results and offers guidelines for improving the accuracy of the analysis. Face Symmetry Test is free to use and prioritizes user privacy and security by securely processing uploaded photos without storing or sharing data with third parties.
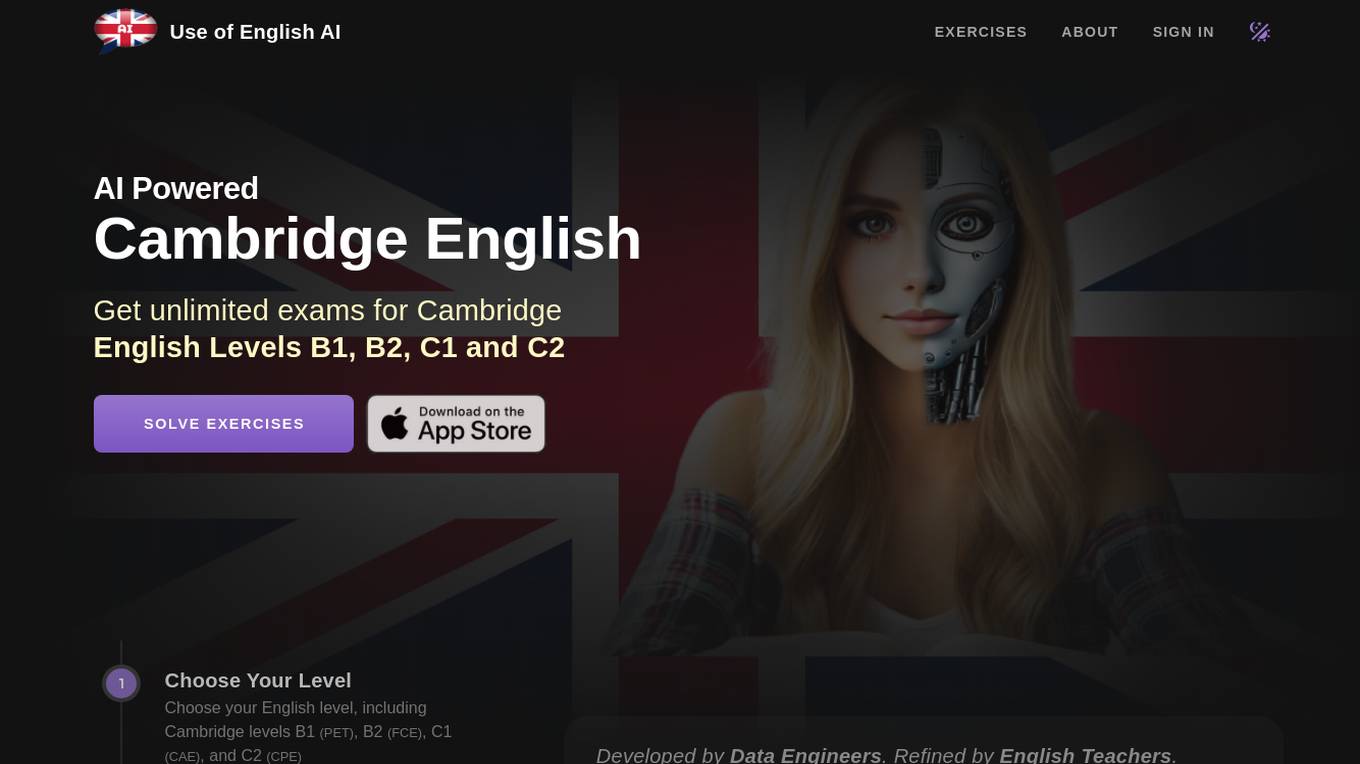
Cambridge English Test AI
The AI-powered Cambridge English Test platform offers exercises for English levels B1, B2, C1, and C2. Users can select exercise types such as Reading and Use of English, including activities like Open Cloze, Multiple Choice, Word Formation, and more. The AI, developed by Shining Apps in partnership with Use of English PRO, provides a unique learning experience by generating exercises from a database of over 5000 official exams. It uses advanced Natural Language Processing (NLP) to understand context, tweak exercises, and offer detailed feedback for effective learning.
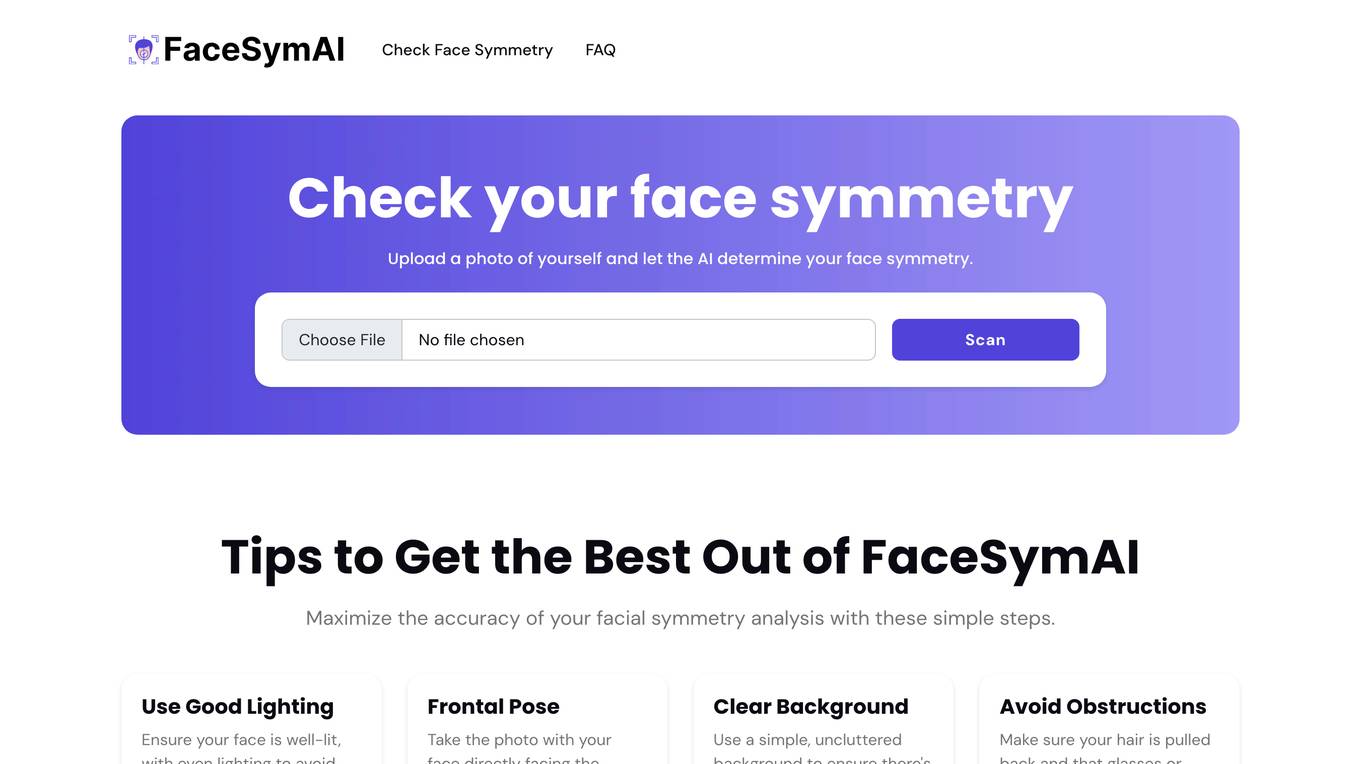
FaceSymAI
FaceSymAI is an online tool that utilizes advanced AI algorithms to analyze and determine the symmetry of your face. By uploading a photo, the AI examines your facial features, including the eyes, nose, mouth, and overall structure, to provide an accurate assessment of your facial symmetry. The analysis is based on mathematical and statistical methods, ensuring reliable and precise results. FaceSymAI is designed to be user-friendly and accessible, offering a free service to everyone. The uploaded photos are treated with utmost confidentiality and are not stored or used for any other purpose, ensuring your privacy is respected.
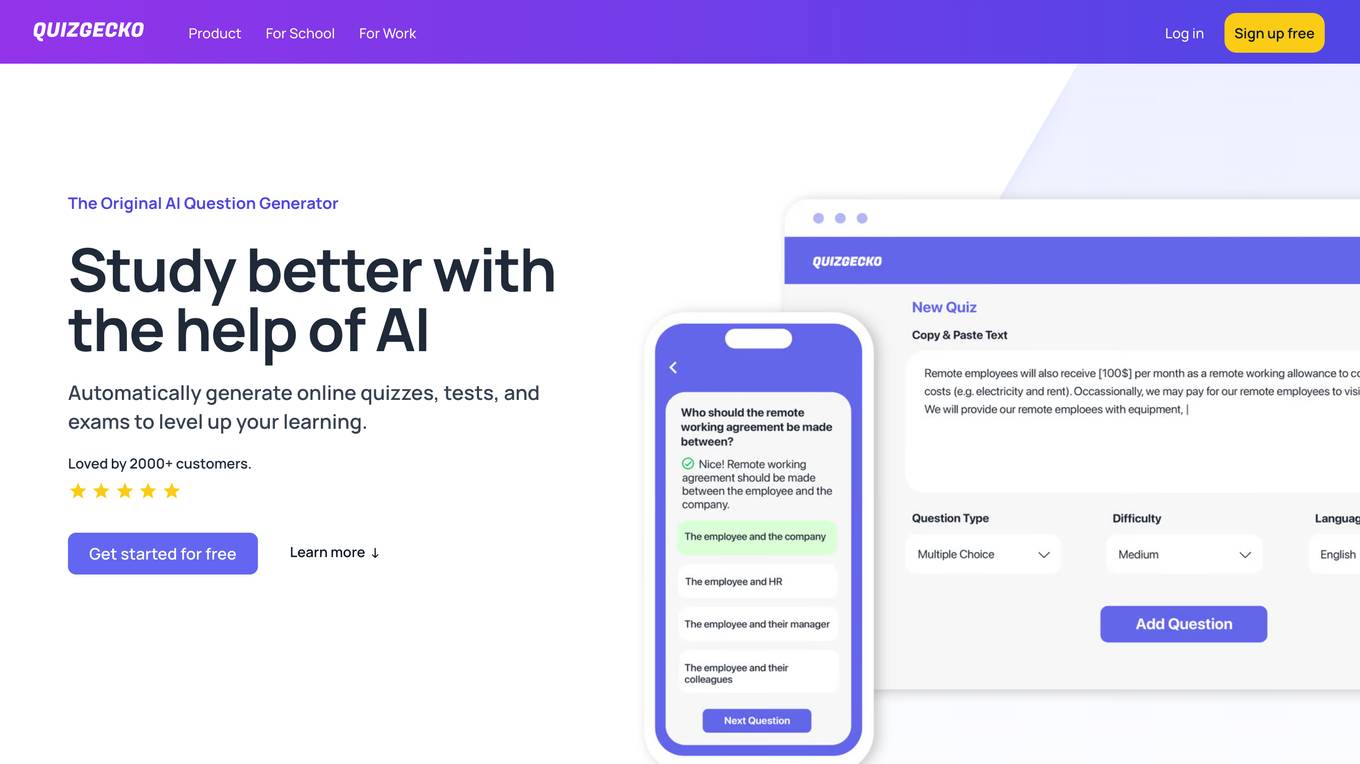
Quizgecko
Quizgecko.com is an online platform that offers a variety of quizzes and trivia games for users to enjoy. Users can test their knowledge on a wide range of topics, including history, science, pop culture, and more. The website provides a fun and interactive way to challenge yourself and learn new things. With a user-friendly interface, quizgecko.com is suitable for people of all ages who are looking for entertainment and mental stimulation.

Leapwork
Leapwork is an AI-powered test automation platform that enables users to build, manage, maintain, and analyze complex data-driven testing across various applications, including AI apps. It offers a democratized testing approach with an intuitive visual interface, composable architecture, and generative AI capabilities. Leapwork supports testing of diverse application types, web, mobile, desktop applications, and APIs. It allows for scalable testing with reusable test flows that adapt to changes in the application under test. Leapwork can be deployed on the cloud or on-premises, providing full control to the users.
Vocera
Vocera is an AI voice agent testing tool that allows users to test and monitor voice AI agents efficiently. It enables users to launch voice agents in minutes, ensuring a seamless conversational experience. With features like testing against AI-generated datasets, simulating scenarios, and monitoring AI performance, Vocera helps in evaluating and improving voice agent interactions. The tool provides real-time insights, detailed logs, and trend analysis for optimal performance, along with instant notifications for errors and failures. Vocera is designed to work for everyone, offering an intuitive dashboard and data-driven decision-making for continuous improvement.
Thumblytics
Thumblytics is a tool that helps YouTubers test their YouTube thumbnails and titles before they publish them. It uses a combination of machine learning and human feedback to help users choose the best thumbnail and title combination for their videos. Thumblytics is designed to be easy to use, even for beginners. Users simply upload their thumbnail and title variants to Thumblytics, and the tool will preview them in a YouTube template and show them to hundreds of real people to collect click data. Thumblytics then crunches the data to help users pick the highest click-through rate (CTR) thumbnail and title.
Spur
Spur is an AI QA tool that allows users to test websites using natural language, eliminating the need for complex test scripts. It offers reliable automated tests that adapt to UI changes, real-time playback for debugging, and powerful validations. Spur's AI-powered tests reduce manual testing time, improve software testing processes, and ensure the reliability of tests even with site changes. The tool is user-friendly, requires no coding skills, and supports API testing.
ILoveMyQA
ILoveMyQA is an AI-powered QA testing service that provides comprehensive, well-documented bug reports. The service is affordable, easy to get started with, and requires no time-zapping chats. ILoveMyQA's team of Rockstar QAs is dedicated to helping businesses find and fix bugs before their customers do, so they can enjoy the results and benefits of having a QA team without the cost, management, and headaches.
Webomates
Webomates is an AI-powered test automation platform that helps users release software faster by providing comprehensive AI-enhanced testing services. It offers solutions for DevOps, code coverage, media & telecom, small and medium businesses, cross-browser testing, and intelligent test automation. The platform leverages AI and machine learning to predict defects, reduce false positives, and accelerate software releases. Webomates also features intelligent automation, smart reporting, and scalable payment options. It seamlessly integrates with popular development tools and processes, providing analytics and support for manual and AI automation testing.

Webo.AI
Webo.AI is a test automation platform powered by AI that offers a smarter and faster way to conduct testing. It provides generative AI for tailored test cases, AI-powered automation, predictive analysis, and patented AiHealing for test maintenance. Webo.AI aims to reduce test time, production defects, and QA costs while increasing release velocity and software quality. The platform is designed to cater to startups and offers comprehensive test coverage with human-readable AI-generated test cases.
Checkmyidea-IA
Checkmyidea-IA is an AI-powered tool that helps entrepreneurs and businesses evaluate their business ideas before launching them. It uses a variety of factors, such as customer interest, uniqueness, initial product development, and launch strategy, to provide users with a comprehensive review of their idea's potential for success. Checkmyidea-IA can help users save time, increase their chances of success, reduce risk, and improve their decision-making.
Fake Hacker News
The website is a platform where users can submit fake hacker news for testing purposes. Users can log in to submit their titles and test their submissions. The platform allows users to see how readers may respond to their posts. The website was built by Justin and Michael.
bottest.ai
bottest.ai is an AI-powered chatbot testing tool that focuses on ensuring quality, reliability, and safety in AI-based chatbots. The tool offers automated testing capabilities without the need for coding, making it easy for users to test their chatbots efficiently. With features like regression testing, performance testing, multi-language testing, and AI-powered coverage, bottest.ai provides a comprehensive solution for testing chatbots. Users can record tests, evaluate responses, and improve their chatbots based on analytics provided by the tool. The tool also supports enterprise readiness by allowing scalability, permissions management, and integration with existing workflows.

Quizbot
Quizbot.ai is an advanced AI question generator designed to revolutionize the process of question and exam development. It offers a cutting-edge artificial intelligence system that can generate various types of questions from different sources like PDFs, Word documents, videos, images, and more. Quizbot.ai is a versatile tool that caters to multiple languages and question types, providing a personalized and engaging learning experience for users across various industries. The platform ensures scalability, flexibility, and personalized assessments, along with detailed analytics and insights to track learner performance. Quizbot.ai is secure, user-friendly, and offers a range of subscription plans to suit different needs.
0 - Open Source Tools
20 - OpenAI Gpts


GetPaths
This GPT takes in content related to an application, such as HTTP traffic, JavaScript files, source code, etc., and outputs lists of URLs that can be used for further testing.
Test Shaman
Test Shaman: Guiding software testing with Grug wisdom and humor, balancing fun with practical advice.
Raven's Progressive Matrices Test
Provides Raven's Progressive Matrices test with explanations and calculates your IQ score.

IQ Test Assistant
An AI conducting 30-question IQ tests, assessing and providing detailed feedback.
Test Case GPT
I will provide guidance on testing, verification, and validation for QA roles.

GRE Test Vocabulary Learning
Helps user learn essential vocabulary for GRE test with multiple choice questions
Lab Test Insights
I'm your lab test consultant for blood tests and microbial cultures. How can I help you today?


Cyber Test & CareerPrep
Helping you study for cybersecurity certifications and get the job you want!
Complete Apex Test Class Assistant
Crafting full, accurate Apex test classes, with 100% user service.