Best AI tools for< Test Lead >
Infographic
20 - AI tool Sites
ILoveMyQA
ILoveMyQA is an AI-powered QA testing service that provides comprehensive, well-documented bug reports. The service is affordable, easy to get started with, and requires no time-zapping chats. ILoveMyQA's team of Rockstar QAs is dedicated to helping businesses find and fix bugs before their customers do, so they can enjoy the results and benefits of having a QA team without the cost, management, and headaches.
mabl
Mabl is a leading unified test automation platform built on cloud, AI, and low-code innovations that delivers a modern approach ensuring the highest quality software across the entire user journey. Our SaaS platform allows teams to scale functional and non-functional testing across web apps, mobile apps, APIs, performance, and accessibility for best-in-class digital experiences.
AI Generated Test Cases
AI Generated Test Cases is an innovative tool that leverages artificial intelligence to automatically generate test cases for software applications. By utilizing advanced algorithms and machine learning techniques, this tool can efficiently create a comprehensive set of test scenarios to ensure the quality and reliability of software products. With AI Generated Test Cases, software development teams can save time and effort in the testing phase, leading to faster release cycles and improved overall productivity.
Diffblue Cover
Diffblue Cover is an autonomous AI-powered unit test writing tool for Java development teams. It uses next-generation autonomous AI to automate unit testing, freeing up developers to focus on more creative work. Diffblue Cover can write a complete and correct Java unit test every 2 seconds, and it is directly integrated into CI pipelines, unlike AI-powered code suggestions that require developers to check the code for bugs. Diffblue Cover is trusted by the world's leading organizations, including Goldman Sachs, and has been proven to improve quality, lower developer effort, help with code understanding, reduce risk, and increase deployment frequency.
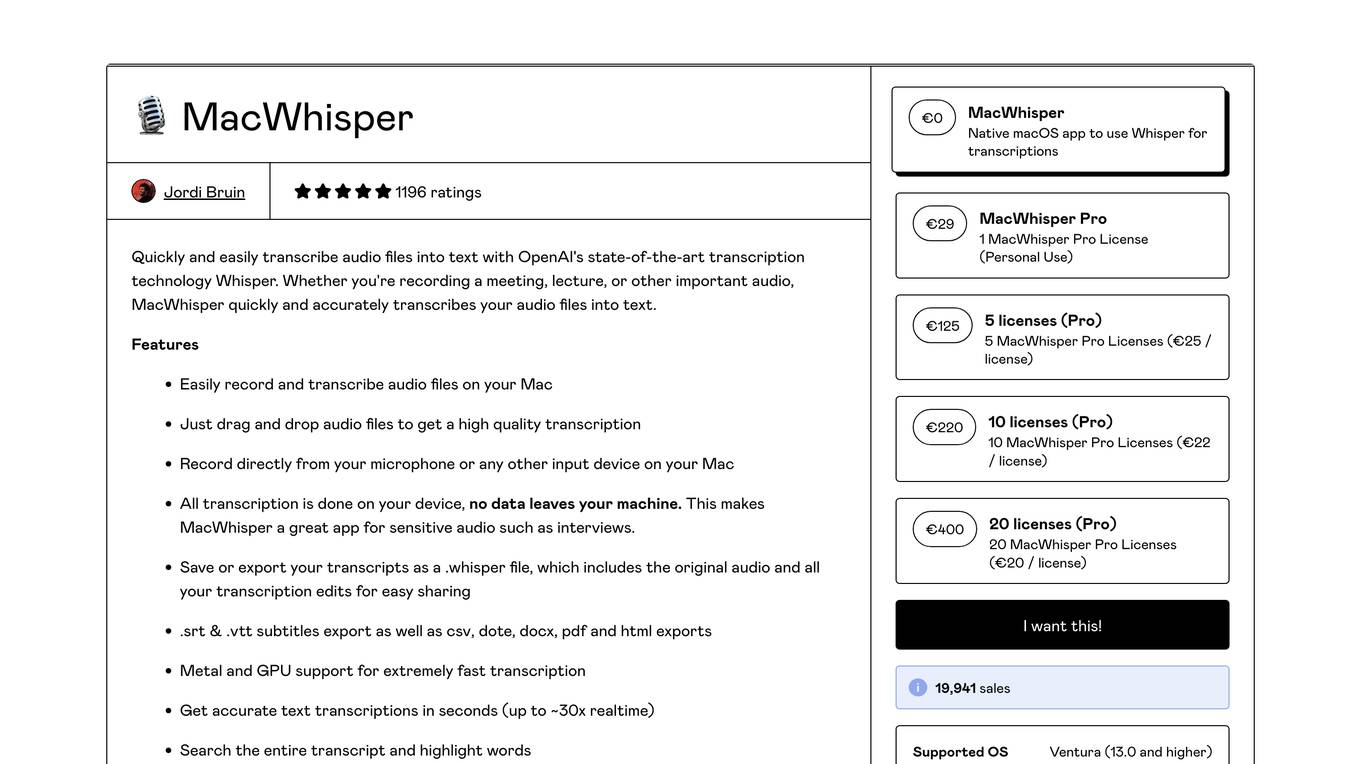
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
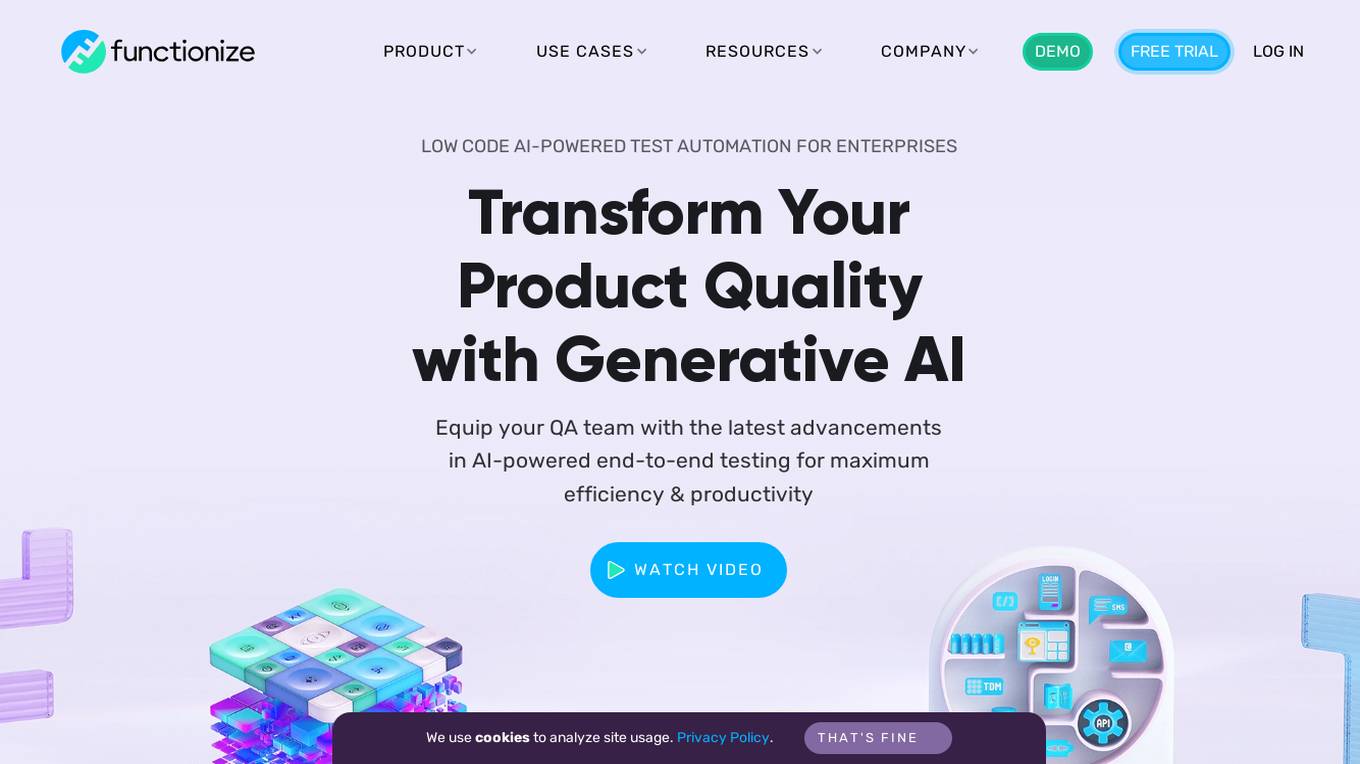
Functionize
Functionize is an AI-powered test automation platform that helps enterprises improve their product quality and release faster. It uses machine learning to automate test creation, maintenance, and execution, and provides a range of features to help teams collaborate and manage their testing process. Functionize integrates with popular CI/CD tools and DevOps pipelines, and offers a range of pricing options to suit different needs.
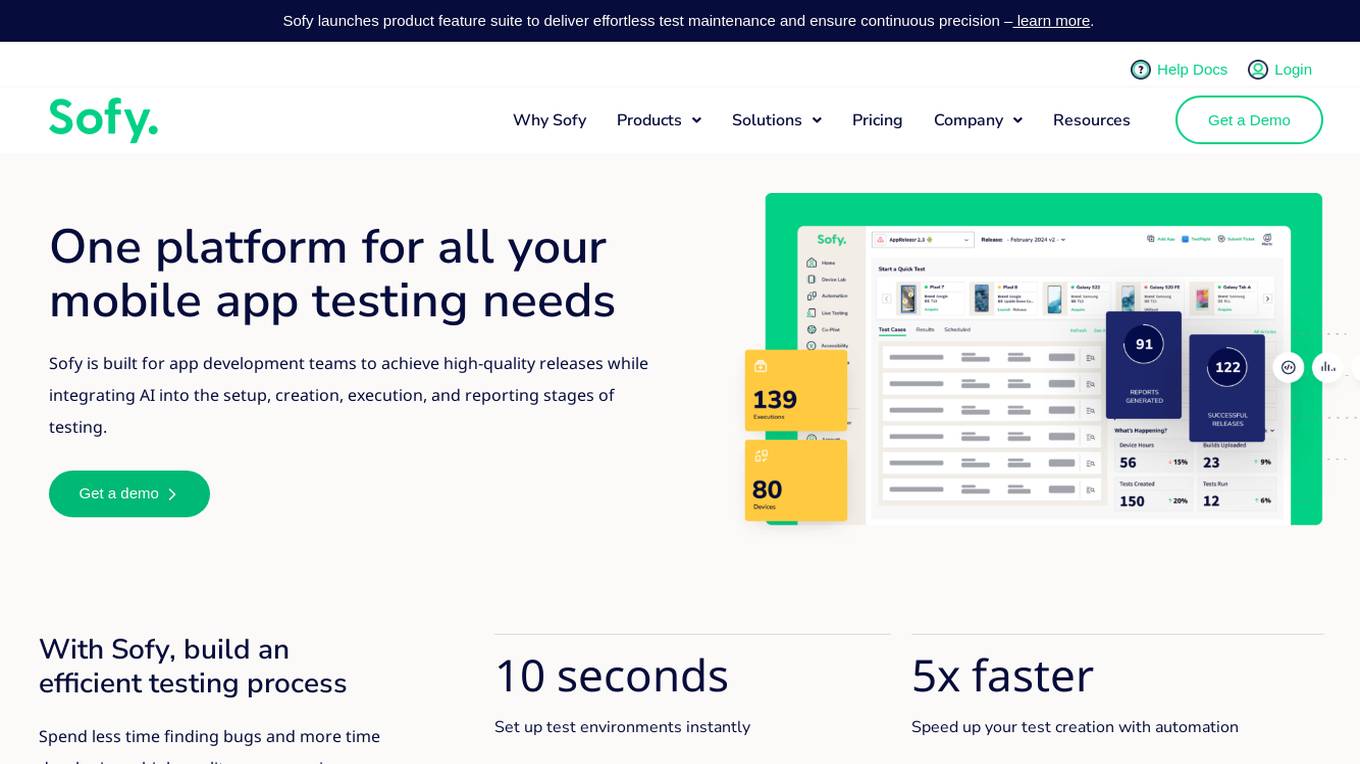
Sofy
Sofy is a revolutionary no-code testing platform for mobile applications that integrates AI to streamline the testing process. It offers features such as manual and ad-hoc testing, no-code automation, AI-powered test case generation, and real device testing. Sofy helps app development teams achieve high-quality releases by simplifying test maintenance and ensuring continuous precision. With a focus on efficiency and user experience, Sofy is trusted by top industries for its all-in-one testing solution.
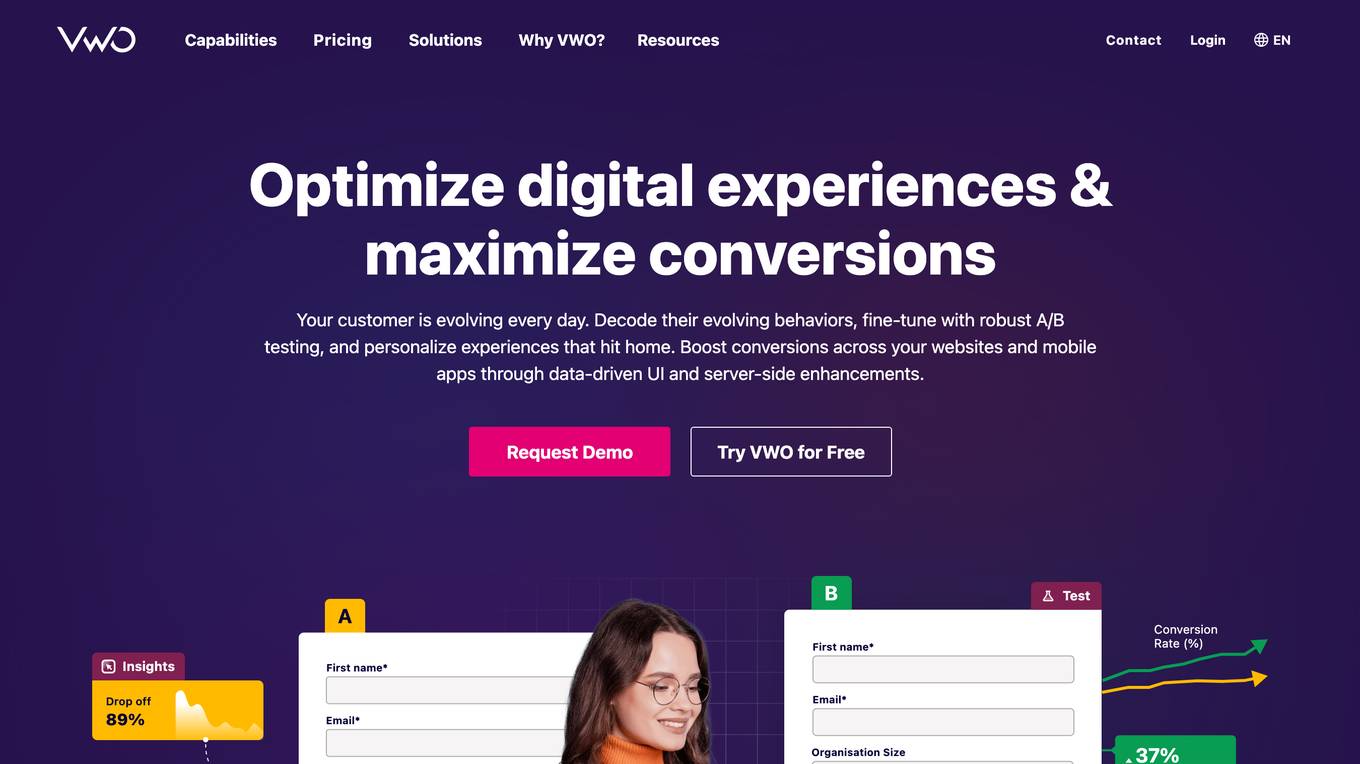
VWO
VWO is a comprehensive experimentation platform that enables businesses to optimize their digital experiences and maximize conversions. With a suite of products designed for the entire optimization program, VWO empowers users to understand user behavior, validate optimization hypotheses, personalize experiences, and deliver tailored content and experiences to specific audience segments. VWO's platform is designed to be enterprise-ready and scalable, with top-notch features, strong security, easy accessibility, and excellent performance. Trusted by thousands of leading brands, VWO has helped businesses achieve impressive growth through experimentation loops that shape customer experience in a positive direction.
Encord
Encord is a complete data development platform designed for AI applications, specifically tailored for computer vision and multimodal AI teams. It offers tools to intelligently manage, clean, and curate data, streamline labeling and workflow management, and evaluate model performance. Encord aims to unlock the potential of AI for organizations by simplifying data-centric AI pipelines, enabling the building of better models and deploying high-quality production AI faster.
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on speech. It helps users improve pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English communication skills in various contexts.

Traceable
Traceable is an intelligent API security platform designed for enterprise-scale security. It offers unmatched API discovery, attack detection, threat hunting, and infinite scalability. The platform provides comprehensive protection against API attacks, fraud, and bot security, along with API testing capabilities. Powered by Traceable's OmniTrace Engine, it ensures unparalleled security outcomes, remediation, and pre-production testing. Security teams trust Traceable for its speed and effectiveness in protecting API infrastructures.
Sympher AI
Sympher AI offers a suite of easy-to-use AI apps for everyday tasks. These apps are designed to help users save time, improve productivity, and make better decisions. Some of the most popular Sympher AI apps include: * **MeMyselfAI:** This app helps users create personalized AI assistants that can automate tasks, answer questions, and provide support. * **Screenshot to UI Components:** This app helps users convert screenshots of UI designs into code. * **User Story Generator:** This app helps project managers quickly and easily generate user stories for their projects. * **EcoQuery:** This app helps businesses assess their carbon footprint and develop strategies to reduce their emissions. * **SensAI:** This app provides user feedback on uploaded images. * **Excel Sheets Function AI:** This app helps users create functions and formulas for Google Sheets or Microsoft Excel. * **ScriptSensei:** This app helps users create tailored setup scripts to streamline the start of their projects. * **Flutterflow Friend:** This app helps users answer their Flutterflow problems or issues. * **TestScenarioInsight:** This app generates test scenarios for apps before deploying. * **CaptionGen:** This app automatically turns images into captions.
Filuta AI
Filuta AI is an advanced AI application that redefines game testing with planning agents. It utilizes Composite AI with planning techniques to provide a 24/7 testing environment for smooth, bug-free releases. The application brings deep space technology to game testing, enabling intelligent agents to analyze game states, adapt in real time, and execute action sequences to achieve test goals. Filuta AI offers goal-driven testing, adaptive exploration, detailed insights, and shorter development cycles, making it a valuable tool for game developers, QA leads, game designers, automation engineers, and producers.
TestLabs
TestLabs is an AI-powered platform that offers automated real device app testing for developers. It simplifies the process of ensuring Google Play app compliance by providing real device testing on 20 devices, expert-driven insights, detailed reporting, and secure and reliable testing environment. TestLabs accelerates Play Store approval, saves time and effort, and offers a cost-effective solution for app testing. It is designed to streamline the compliance process, enhance app performance, and provide actionable feedback to developers.
Nokia Rapid Technology Acquisition
Nokia, a global leader in the technologies that connect people and things, has acquired Rapid technology and its team. This acquisition is a strategic move to enhance Nokia's capabilities in the rapidly evolving technology landscape. Rapid technology is known for its innovative solutions in the field of [specific field]. With this acquisition, Nokia aims to strengthen its position in the market and drive innovation to better serve its customers worldwide.
RoostGPT
RoostGPT is an AI-driven testing copilot that offers automated test case generation using Large Language Models (LLMs). It helps in building reliable software by providing 100% test coverage every single time. RoostGPT leverages generative AI to automate test case generation, freeing up developer time and enhancing test accuracy and coverage. It also detects static vulnerabilities in artifacts like source code and logs to ensure data security. The platform is trusted by global financial institutions and industry leaders for its ability to fill gaps in test coverage and simplify testing and deployment processes.
Education Data Center
The Education Data Center (EDC) Version 2.0 is a platform dedicated to providing clear and timely access to education data for researchers and education stakeholders. It offers a State Assessment Data Repository, a leading database of state assessment data in the United States. Users can download data files, utilize a custom-made AI tool to query the data, and access information about the EDC. The platform aims to support evidence-based decision-making to enhance the educational support for the nation's students.
SD Times
The website is a comprehensive platform for software development news, covering a wide range of topics such as AI, DevOps, Observability, CI/CD, Cloud Native, Data, Test Automation, Mobile, API, Performance, Security, DevSecOps, Enterprise Security, Supply Chain Security, Teams & Culture, Dev Manager, Agile, Value Stream, Productivity, and more. It provides news articles, webinars, podcasts, and white papers to keep developers informed about the latest trends and technologies in the software development industry.
GitStart
GitStart is an AI-powered platform that offers Elastic Engineering Capacity by assigning tickets and delivering high-quality production code. It leverages AI agents and a global developer community to increase engineering capacity without hiring more staff. GitStart is supported by top tech leaders and provides solutions for bugs, tech debt, frontend and backend development. The platform aims to empower developers, create economic opportunities, and grow the world's future software talent.
Autoblocks AI
Autoblocks AI is an AI application designed to help users build safe AI apps efficiently. It allows users to ship AI agents in minutes, speeding up the development process significantly. With Autoblocks AI, users can prototype quickly, test at a faster rate, and deploy with confidence. The application is trusted by leading AI teams and focuses on making AI agent development more predictable by addressing the unpredictability of user inputs and non-deterministic models.
0 - Open Source Tools
20 - OpenAI Gpts

INSIGHT Business SIM
The future of business education: Generate and test ideas in a complex global market simulation, populated by autonomous agents. Powered by the MANNS engine for unparalleled entity autonomy and simulated market forces
Prompt QA
Designed for excellence in Quality Assurance, fine-tuning custom GPT configurations through continuous refinement.


Test Shaman
Test Shaman: Guiding software testing with Grug wisdom and humor, balancing fun with practical advice.
Raven's Progressive Matrices Test
Provides Raven's Progressive Matrices test with explanations and calculates your IQ score.

IQ Test Assistant
An AI conducting 30-question IQ tests, assessing and providing detailed feedback.
Test Case GPT
I will provide guidance on testing, verification, and validation for QA roles.

GRE Test Vocabulary Learning
Helps user learn essential vocabulary for GRE test with multiple choice questions
Lab Test Insights
I'm your lab test consultant for blood tests and microbial cultures. How can I help you today?
