Best AI tools for< Speech-to-text >
Infographic
20 - AI tool Sites
Free Audio to Text Converter
The Free Audio to Text Converter is an AI-powered tool that allows users to quickly and accurately transcribe audio files into text. It supports various audio formats and offers features like multi-speaker identification, multiple export formats, and precise timestamps. The tool is designed to enhance productivity by providing high-quality transcriptions for a wide range of needs, from content creation to academic research and sales analysis. Users can trust the tool's accuracy and efficiency to save time and improve workflow.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
Transgate
Transgate is an AI-powered speech-to-text conversion tool that allows users to convert audio/video files to text with high accuracy and efficiency. It offers a pay-as-you-go model, supports over 50 languages, and guarantees 98%+ accuracy. Transgate is designed to boost productivity by minimizing costs and eliminating manual transcription tasks, catering to industries like AI/ML, medical, legal, education, consulting, and market research.
Vocaldo
Vocaldo is a revolutionary speech-to-text application that utilizes cutting-edge AI technology to transcribe speech into text in over 100 languages. It offers accurate, fast, and easy-to-use transcription services, allowing users to effortlessly convert audio or video files into text with high precision. Vocaldo supports multiple speakers, various accents, and background noise, making it a versatile tool for content creators, journalists, and businesses worldwide.
Lemonfox.ai
Lemonfox.ai is an affordable and easy-to-use Speech-To-Text API that allows users to transcribe audio files quickly and accurately. With features like support for over 100 languages, speaker recognition, high accuracy, and secure processing, Lemonfox.ai is a cost-effective solution for developers and non-developers alike. The API offers simple and affordable pricing plans, with the first month free to get started. Privacy and data security are prioritized, with all data being deleted immediately after processing. Lemonfox.ai is powered by the latest speech recognition AI model, Whisper large-v3, ensuring top-notch performance and competitive pricing.
FreeTTS
FreeTTS is a free online text-to-speech tool that allows users to convert text into natural-sounding speech in various languages and voices. It supports a range of features such as text-to-speech conversion, speech-to-text conversion, vocal removal, voice enhancement, audio cutting, and audio joining. FreeTTS is suitable for various applications, including content creation, education, accessibility, and entertainment.
DubSmart
DubSmart is an AI-powered platform that offers advanced video dubbing and voice cloning services. It allows users to transform text into lifelike speech, dub videos with voice cloning technology, and generate subtitles for audio or video content. With a user-friendly interface, DubSmart enables users to create unique voices, edit projects, and download finished projects in various formats. The platform supports 33 languages for AI dubbing and 60+ languages for speech-to-text conversion. DubSmart caters to small creators, YouTubers, and companies looking to enhance their audiovisual content with personalized voices and multilingual capabilities.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
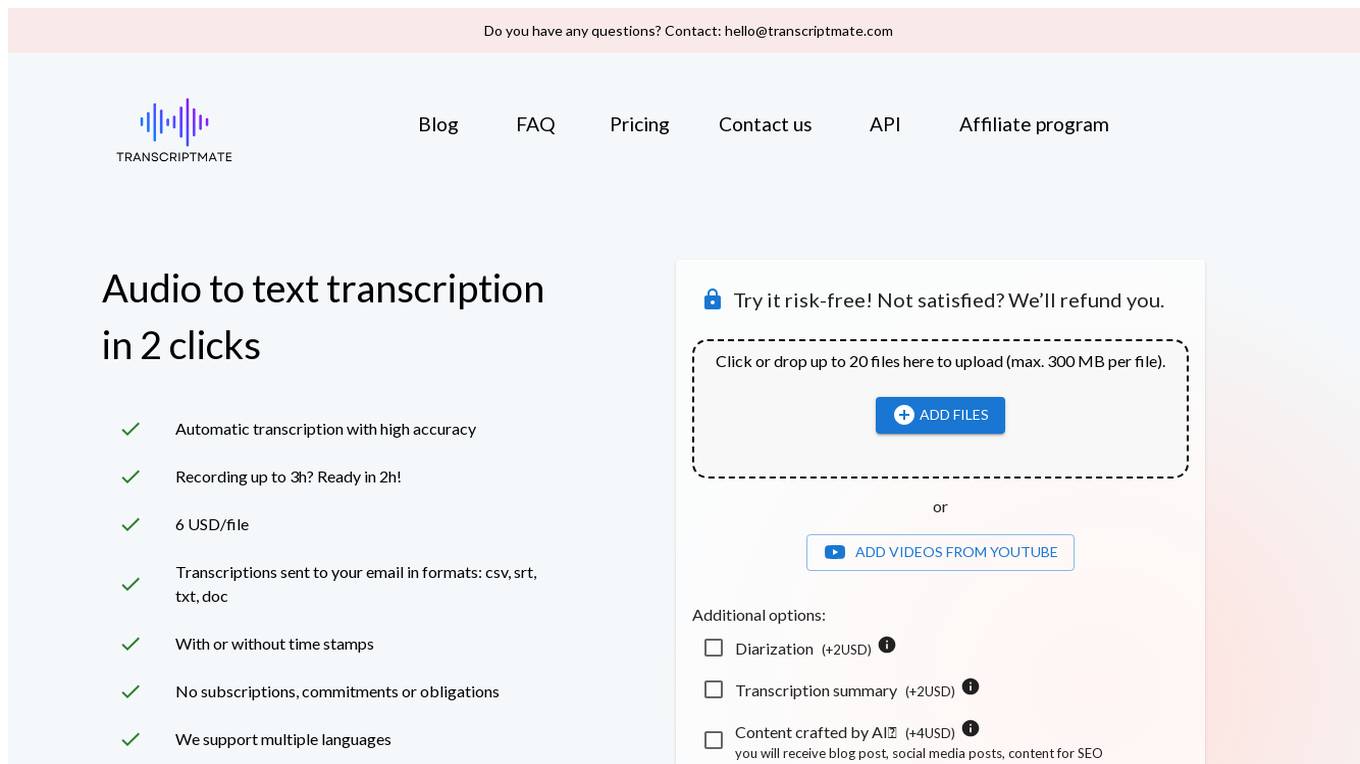
Transcriptmate
Transcriptmate is an AI-powered audio to text transcription tool that offers automatic transcription with high accuracy. Users can easily convert audio files to text in just 2 clicks, with the option to add features like diarization and AI content crafting. The tool supports multiple languages, provides transcriptions in various formats, and ensures safe payments. Transcriptmate is recommended by customers for its efficiency, accuracy, and user-friendly interface.
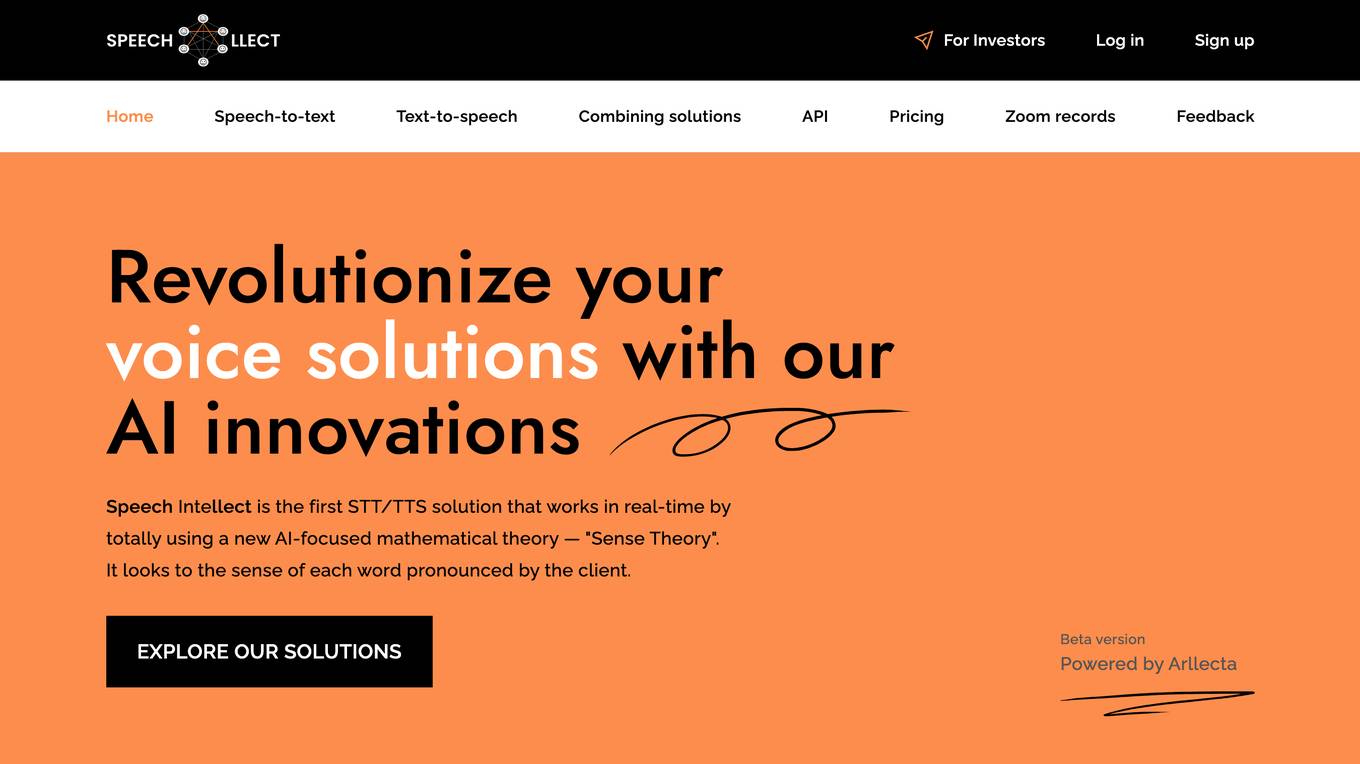
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
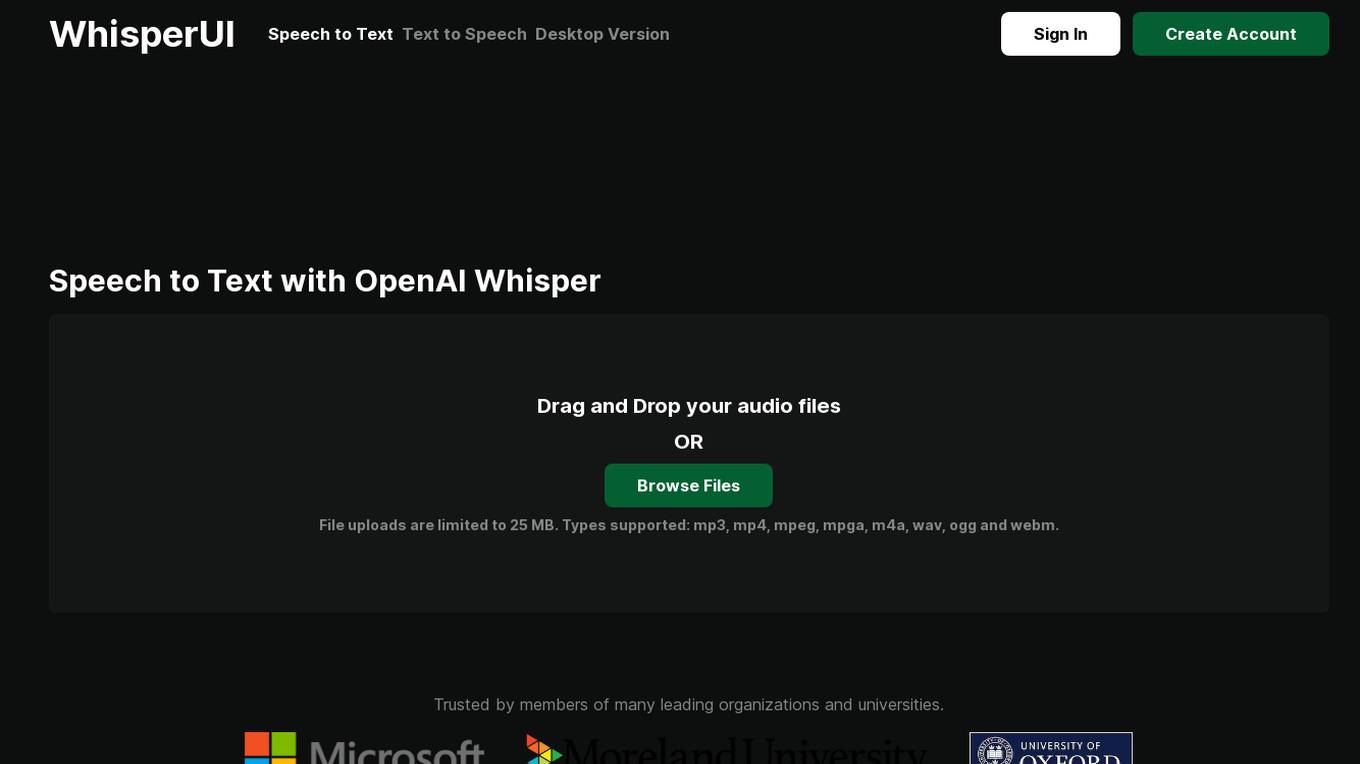
WhisperUI
WhisperUI is an affordable Speech to Text application powered by OpenAI Whisper. It allows users to easily convert audio files into text and SRT files with high accuracy. The application is trusted by members of leading organizations and universities. Users can upload various audio file formats and benefit from premium features such as uploading multiple files at once and unlimited daily file uploads. WhisperUI supports multiple languages and is known for its robustness in transcribing speech in the presence of accents, background noise, and technical language.
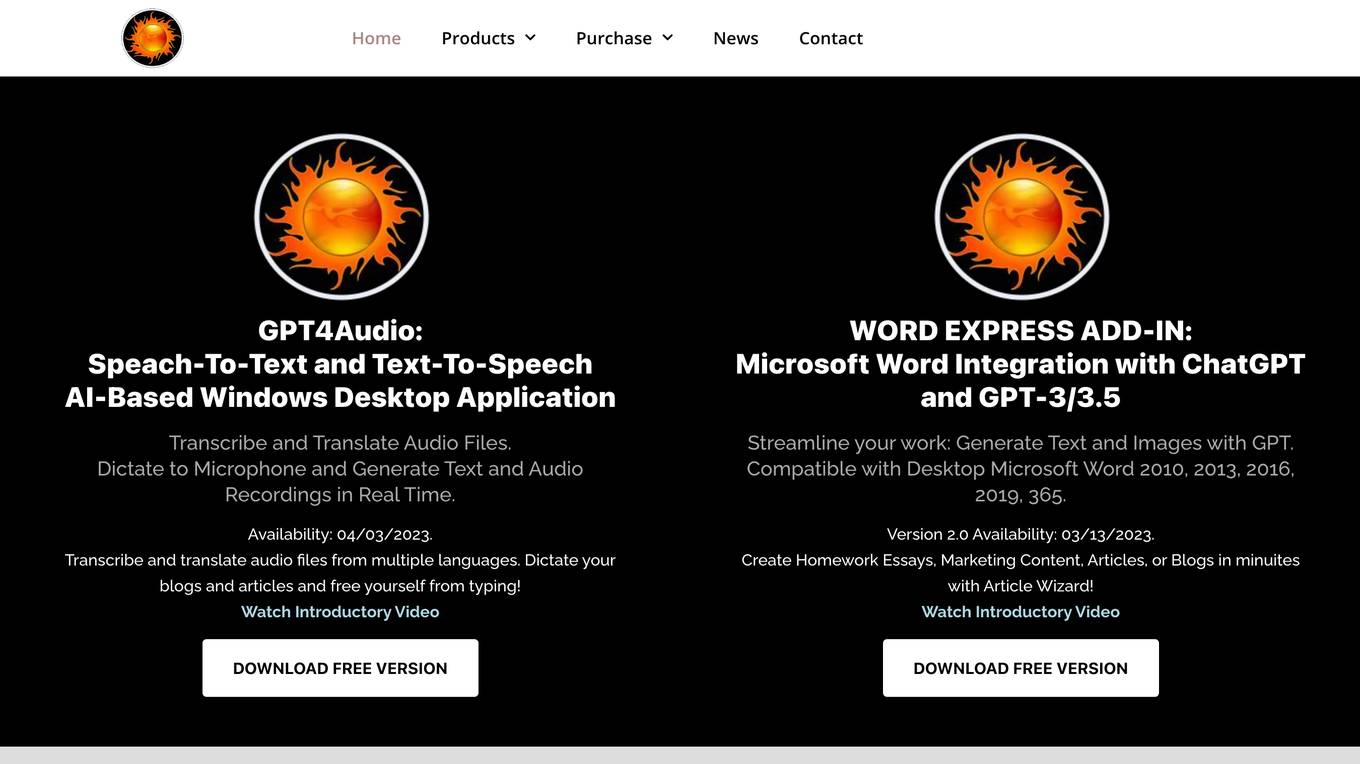
GPT4Audio
GPT4Audio is an AI-based desktop application that offers speech-to-text and text-to-speech capabilities. It allows users to transcribe and translate audio files from multiple languages, as well as dictate text and generate audio recordings in real time. The application also includes an Article Wizard feature that can help users create homework essays, marketing content, articles, or blogs quickly and easily.
BlabbyAI
BlabbyAI is an AI-powered speech-to-text Chrome extension that allows users to write with their voice on any website. It seamlessly integrates with various platforms, offering automatic punctuation, capitalization, and grammar. Users can personalize their transcription experience with custom modes and save time by boosting productivity. The tool has received positive reviews for its accuracy, ease of use, and cross-platform functionality.
VideoToWords.ai
VideoToWords.ai is an AI-powered transcription tool that converts audio and video files into accurate written text. It utilizes advanced machine learning algorithms to transcribe files quickly and efficiently, catering to a wide range of users such as journalists, students, researchers, podcast hosts, filmmakers, content creators, marketers, and professionals from various industries. The platform supports multiple languages, offers convenient text editing and export options, and ensures data security and privacy for users.
Lingvanex
Lingvanex is a cloud-based machine translation and speech recognition platform that provides businesses with a variety of tools to translate text, documents, and speech in over 100 languages. The platform is powered by artificial intelligence (AI) and machine learning (ML) technologies, which enable it to deliver high-quality translations that are both accurate and fluent. Lingvanex also offers a variety of features that make it easy for businesses to integrate translation and speech recognition into their workflows, including APIs, SDKs, and plugins for popular programming languages and platforms.
Picovoice
Picovoice is an on-device Voice AI and local LLM platform designed for enterprises. It offers a range of voice AI and LLM solutions, including speech-to-text, noise suppression, speaker recognition, speech-to-index, wake word detection, and more. Picovoice empowers developers to build virtual assistants and AI-powered products with compliance, reliability, and scalability in mind. The platform allows enterprises to process data locally without relying on third-party remote servers, ensuring data privacy and security. With a focus on cutting-edge AI technology, Picovoice enables users to stay ahead of the curve and adapt quickly to changing customer needs.
SpeechFlow
SpeechFlow is a powerful speech-to-text API that transcribes audio and video files into text with high accuracy. It supports 14 languages and offers features such as punctuation, easy deployment, scalability, and fast processing. SpeechFlow is ideal for businesses and individuals who need accurate and timely transcription services.

Voam
Voam is a productive AI platform that helps you to automate your tasks and improve your productivity. With Voam, you can create custom AI models to automate any task, from simple data entry to complex decision-making. Voam is easy to use and requires no coding experience. You can create an AI model in minutes and start automating your tasks right away.
OneAudio
OneAudio is an AI-powered tool that allows users to summarize, transcribe, and convert audio files into notes. With features like recording, summarization, and language selection, OneAudio helps users organize and transform their ideas efficiently. The tool leverages OpenAI GPT-4 and GPT-4o models to provide accurate transcriptions and summaries. Users can choose from different pricing plans based on their needs, from a free tier to a premium plan with unlimited features. OneAudio is designed to streamline the process of converting audio content into written notes, making it ideal for students, professionals, and anyone looking to enhance their productivity.
Voice Pen
Voice Pen is a Speech to Text AI application available on the App Store for Apple devices. It allows users to record and transcribe speech into text, which can then be used to create notes, summaries, emails, messages, and blog posts. The app supports more than 50 languages and offers AI options for rewriting and transforming text. Voice Pen enhances productivity by providing features like background audio recording, language autodetection, and the ability to create various types of content. It also prioritizes user privacy by only collecting app usage analytics and not storing any audio or text data on its servers.
1 - Open Source Tools

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.
20 - OpenAI Gpts
Chat with GPT 4o ("Omni") Assistant
Try the new AI chat model: GPT 4o ("Omni") Assistant. It's faster and better than regular GPT. Plus it will incorporate speech-to-text, intelligence, and speech-to-text capabilities with extra low latency.

Video GPT
AI Video Maker. Generate videos for social media - YouTube, Instagram, TikTok and more! Free text to video & speech tool with AI Avatars, TTS, music, and stock footage.
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.

Cat Translator
Your Feline Language Specialist for translating human speech to cat sounds.
AI.EX Wedding Speech Consultant
Your partner in crafting perfect wedding speeches. Let me be your guide to writing impactful, memorable speeches for unforgettable moments.

Visionary Quotations And Context
Thought-provoking quotes relate to visionary thinking, human-AI collaboration, and Doughnut Economics. Fostering a sustainable and equitable future for all.
Book to Prompt
Turn Any Book into Actionable Prompts. 1. Upload the PDF of a book 2. Tell your goal to be turned into a prompt

Sensory Integration Guide
Your personalized guide guide to all things sensory, including Sensory Processing Disorder and Sensory Integration Therapy.

Reading Tutor
A nurturing tutor dedicated to assisting children in grades K-5, enhancing their reading and literacy skills with patience and encouragement.