Best AI tools for< Latin Teacher >
Infographic
3 - AI tool Sites
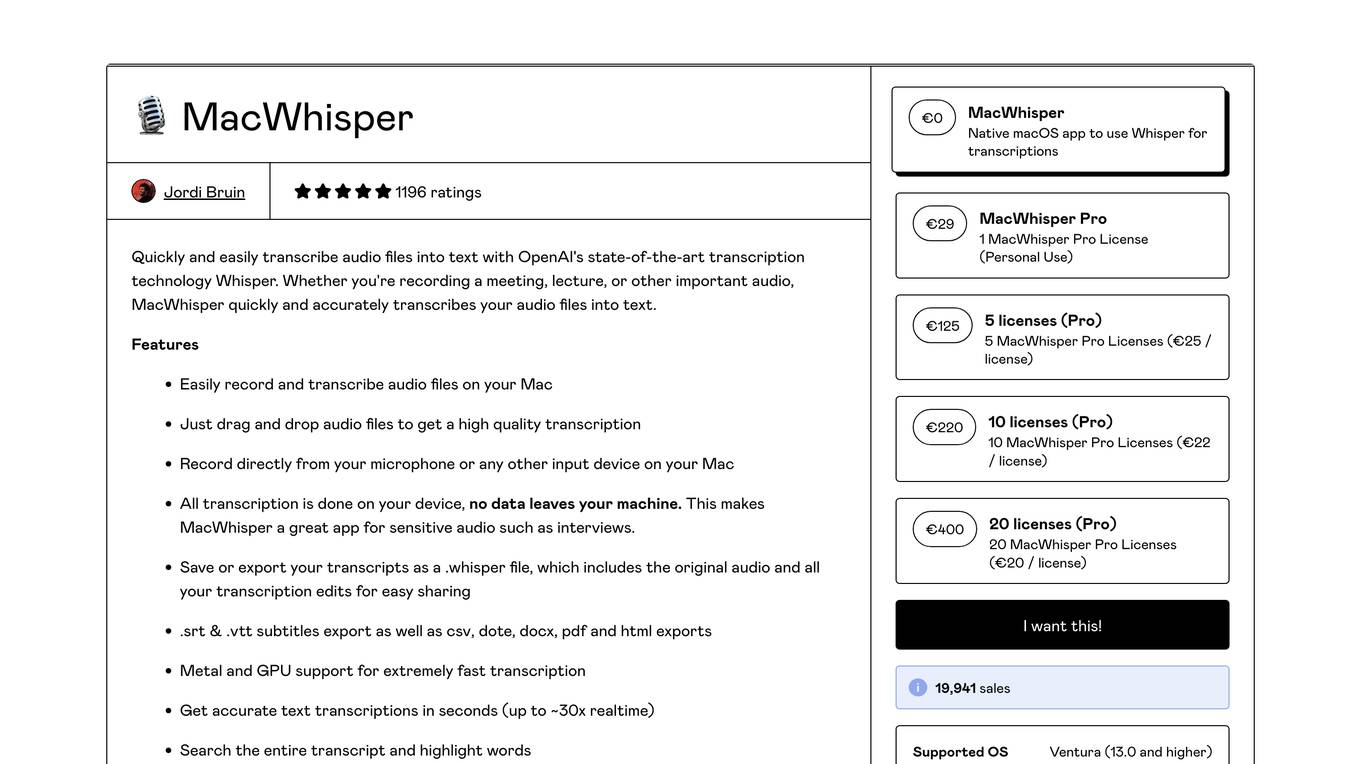
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.

CUX
CUX is a leading emotional well-being platform in Latin America that combines artificial intelligence with telemedicine to provide personalized support. Users can talk about their feelings, seek advice, access telemedicine services, and receive emotional support 24/7. The platform offers emotional support through AI-powered chats, quick access to healthcare professionals, and well-being metrics for emotional improvement. CUX aims to combat loneliness and provide immediate emotional support without judgment.
IA Latina
IA Latina is an AI-powered platform that provides a wide range of tools for content creators, students, and professionals across various industries. It offers features such as text generation, image creation, chatbot development, voice-to-text and text-to-voice conversion, and more. The platform aims to enhance productivity and efficiency by automating content creation tasks and providing users with high-quality results.
0 - Open Source Tools
9 - OpenAI Gpts
Dialect Detective
Expert in distinguishing language dialects like Castilian vs Latin Spanish, and Parisian vs Canadian French.
Arabizi
Arabizi translates and transliterates between English, Arabizi, and Arabic script, considering regional dialects and slang. Use Latin characters to represent the Arabic language.