Best AI tools for< Gpu Optimization Engineer >
Infographic
20 - AI tool Sites
Alluxio
Alluxio is a data orchestration platform designed for the cloud, offering seamless access, management, and running of AI/ML workloads. Positioned between compute and storage, Alluxio provides a unified solution for enterprises to handle data and AI tasks across diverse infrastructure environments. The platform accelerates model training and serving, maximizes infrastructure ROI, and ensures seamless data access. Alluxio addresses challenges such as data silos, low performance, data engineering complexity, and high costs associated with managing different tech stacks and storage systems.
FriendliAI
FriendliAI is a generative AI infrastructure company that offers efficient, fast, and reliable generative AI inference solutions for production. Their cutting-edge technologies enable groundbreaking performance improvements, cost savings, and lower latency. FriendliAI provides a platform for building and serving compound AI systems, deploying custom models effortlessly, and monitoring and debugging model performance. The application guarantees consistent results regardless of the model used and offers seamless data integration for real-time knowledge enhancement. With a focus on security, scalability, and performance optimization, FriendliAI empowers businesses to scale with ease.
Rafay
Rafay is an AI-powered platform that accelerates cloud-native and AI/ML initiatives for enterprises. It provides automation for Kubernetes clusters, cloud cost optimization, and AI workbenches as a service. Rafay enables platform teams to focus on innovation by automating self-service cloud infrastructure workflows.
CHAI AI
CHAI AI is a leading conversational AI platform that focuses on building AI solutions for quant traders. The platform has secured significant funding rounds to expand its computational capabilities and talent acquisition. CHAI AI offers a range of models and techniques, such as reinforcement learning with human feedback, model blending, and direct preference optimization, to enhance user engagement and retention. The platform aims to provide users with the ability to create their own ChatAIs and offers custom GPU orchestration for efficient inference. With a strong focus on user feedback and recognition, CHAI AI continues to innovate and improve its AI models to meet the demands of a growing user base.
Backend.AI
Backend.AI is an enterprise-scale cluster backend for AI frameworks that offers scalability, GPU virtualization, HPC optimization, and DGX-Ready software products. It provides a fast and efficient way to build, train, and serve AI models of any type and size, with flexible infrastructure options. Backend.AI aims to optimize backend resources, reduce costs, and simplify deployment for AI developers and researchers. The platform integrates seamlessly with existing tools and offers fractional GPU usage and pay-as-you-play model to maximize resource utilization.
Nomi.cloud
Nomi.cloud is a modern AI-powered CloudOps and HPC assistant designed for next-gen businesses. It offers developers, marketplace, enterprise solutions, and pricing console. With features like single pane of glass view, instant deployment, continuous monitoring, AI-powered insights, and budgets & alerts built-in, Nomi.cloud aims to revolutionize cloud management. It provides a user-friendly interface to manage infrastructure efficiently, optimize costs, and deploy resources across multiple regions with ease. Nomi.cloud is built for scale, trusted by enterprises, and offers a range of GPUs and cloud providers to suit various needs.

Caffe
Caffe is a deep learning framework developed by Berkeley AI Research (BAIR) and community contributors. It is designed for speed, modularity, and expressiveness, allowing users to define models and optimization through configuration without hard-coding. Caffe supports both CPU and GPU training, making it suitable for research experiments and industry deployment. The framework is extensible, actively developed, and tracks the state-of-the-art in code and models. Caffe is widely used in academic research, startup prototypes, and large-scale industrial applications in vision, speech, and multimedia.

Cerebium
Cerebium is a serverless AI infrastructure platform that allows teams to build, test, and deploy AI applications quickly and efficiently. With a focus on speed, performance, and cost optimization, Cerebium offers a range of features and tools to simplify the development and deployment of AI projects. The platform ensures high reliability, security, and compliance while providing real-time logging, cost tracking, and observability tools. Cerebium also offers GPU variety and effortless autoscaling to meet the diverse needs of developers and businesses.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.
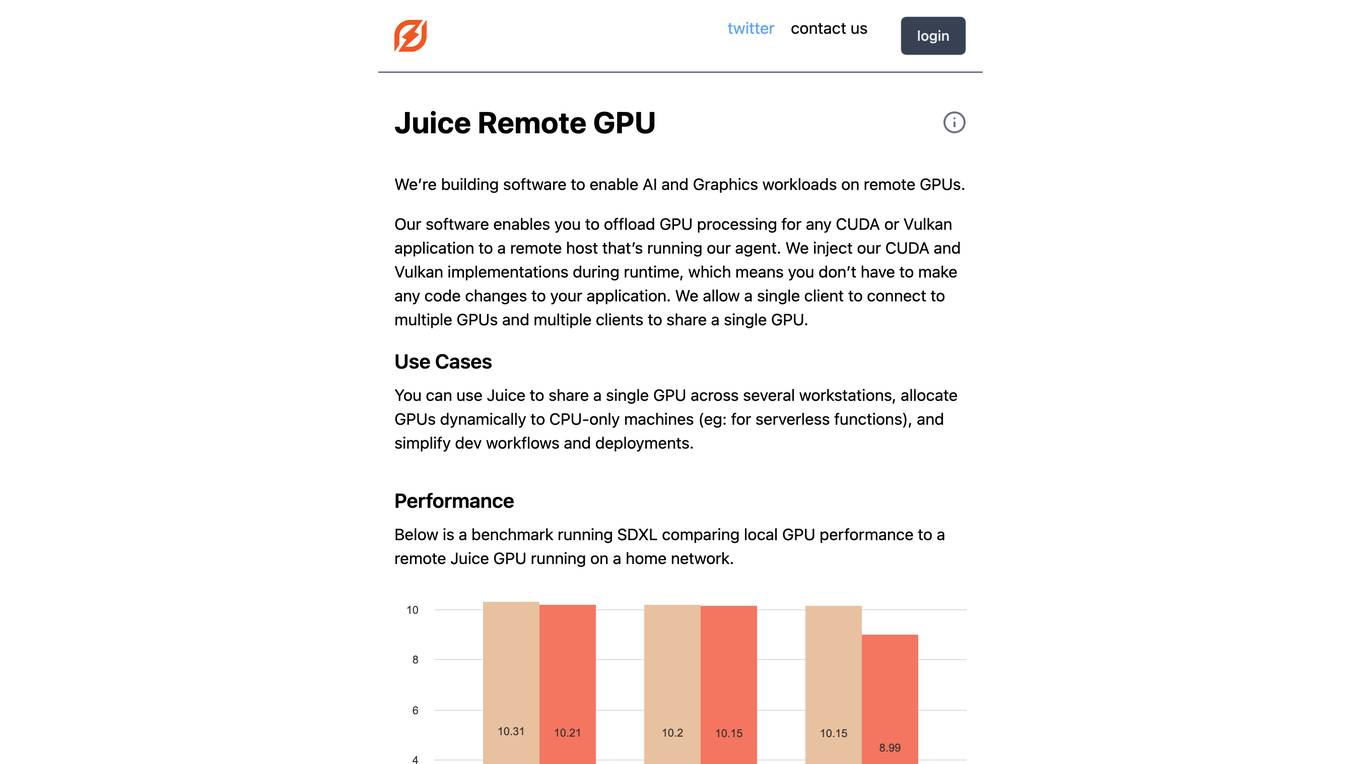
Juice Remote GPU
Juice Remote GPU is a software that enables AI and Graphics workloads on remote GPUs. It allows users to offload GPU processing for any CUDA or Vulkan application to a remote host running the Juice agent. The software injects CUDA and Vulkan implementations during runtime, eliminating the need for code changes in the application. Juice supports multiple clients connecting to multiple GPUs and multiple clients sharing a single GPU. It is useful for sharing a single GPU across multiple workstations, allocating GPUs dynamically to CPU-only machines, and simplifying development workflows and deployments. Juice Remote GPU performs within 5% of a local GPU when running in the same datacenter. It supports various APIs, including CUDA, Vulkan, DirectX, and OpenGL, and is compatible with PyTorch and TensorFlow. The team behind Juice Remote GPU consists of engineers from Meta, Intel, and the gaming industry.
N00MKRAD
N00MKRAD is a free AI image generator that allows users to create their own images using their own GPU. It is a user-friendly tool that is compatible with all recent AMD/Nvidia/Intel GPUs.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing. The company's products and services are used by businesses and governments around the world to develop and deploy AI applications. NVIDIA's AI platform includes hardware, software, and tools that make it easy to build and train AI models. The company also offers a range of cloud-based AI services that make it easy to deploy and manage AI applications. NVIDIA's AI platform is used in a wide variety of industries, including healthcare, manufacturing, retail, and transportation. The company's AI technology is helping to improve the efficiency and accuracy of a wide range of tasks, from medical diagnosis to product design.
Cirrascale Cloud Services
Cirrascale Cloud Services is an AI tool that offers cloud solutions for Artificial Intelligence applications. The platform provides a range of cloud services and products tailored for AI innovation, including NVIDIA GPU Cloud, AMD Instinct Series Cloud, Qualcomm Cloud, Graphcore, Cerebras, and SambaNova. Cirrascale's AI Innovation Cloud enables users to test and deploy on leading AI accelerators in one cloud, democratizing AI by delivering high-performance AI compute and scalable deep learning solutions. The platform also offers professional and managed services, tailored multi-GPU server options, and high-throughput storage and networking solutions to accelerate development, training, and inference workloads.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing, providing hardware and software solutions for gaming, entertainment, data centers, edge computing, and more. Their platforms like Jetson and Isaac enable the development and deployment of AI-powered autonomous machines. NVIDIA's AI applications span various industries, from healthcare to manufacturing, and their technology is transforming the world's largest industries and impacting society profoundly.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing, providing solutions for cloud services, data center, embedded systems, gaming, and creating graphics cards and GPUs. They offer a wide range of products and services, including AI-driven platforms for life sciences research, end-to-end AI platforms, generative AI deployment, advanced simulation integration, and more. NVIDIA focuses on modernizing data centers with AI and accelerated computing, offering enterprise AI platforms, supercomputers, advanced networking solutions, and professional workstations. They also provide software tools for AI development, data center management, GPU monitoring, and more.
Novita AI
Novita AI is an AI cloud platform offering Model APIs, Serverless, and GPU Instance services in a cost-effective and integrated manner to accelerate AI businesses. It provides optimized models for high-quality dialogue use cases, full spectrum AI APIs for image, video, audio, and LLM applications, serverless auto-scaling based on demand, and customizable GPU solutions for complex AI tasks. The platform also includes a Startup Program, 24/7 service support, and has received positive feedback for its reasonable pricing and stable services.
Nebius AI
Nebius AI is an AI-centric cloud platform designed to handle intensive workloads efficiently. It offers a range of advanced features to support various AI applications and projects. The platform ensures high performance and security for users, enabling them to leverage AI technology effectively in their work. With Nebius AI, users can access cutting-edge AI tools and resources to enhance their projects and streamline their workflows.
NVIDIA Run:ai
NVIDIA Run:ai is an enterprise platform for AI workloads and GPU orchestration. It accelerates AI and machine learning operations by addressing key infrastructure challenges through dynamic resource allocation, comprehensive AI life-cycle support, and strategic resource management. The platform significantly enhances GPU efficiency and workload capacity by pooling resources across environments and utilizing advanced orchestration. NVIDIA Run:ai provides unparalleled flexibility and adaptability, supporting public clouds, private clouds, hybrid environments, or on-premises data centers.
GPUDeploy
GPUDeploy is an AI tool that offers low-cost on-demand GPUs for machine learning and AI tasks. Users can easily connect their GPUs and launch GPU instances that are preconfigured for machine learning tasks. The platform provides various GPU configurations with different specifications to cater to diverse computing needs. GPUDeploy also allows users to earn by renting out idle GPUs, making it a versatile solution for both individuals and AI companies.
2 - Open Source Tools

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

marlin
Marlin is a highly optimized FP16xINT4 matmul kernel designed for large language model (LLM) inference, offering close to ideal speedups up to batchsizes of 16-32 tokens. It is suitable for larger-scale serving, speculative decoding, and advanced multi-inference schemes like CoT-Majority. Marlin achieves optimal performance by utilizing various techniques and optimizations to fully leverage GPU resources, ensuring efficient computation and memory management.
2 - OpenAI Gpts


CUDA GPT
Expert in CUDA for configuration, installation, troubleshooting, and programming.