Best AI tools for< Extraction >
Infographic
20 - AI tool Sites

Reworkd
Reworkd is a web data extraction tool that uses AI to generate and repair web extractors on the fly. It allows users to retrieve data from hundreds of websites without the need for developers. Reworkd is used by businesses in a variety of industries, including manufacturing, e-commerce, recruiting, lead generation, and real estate.
Evolution AI
Evolution AI is an AI data extraction tool that specializes in extracting data from financial documents such as financial statements, bank statements, invoices, and other related documents. The tool uses generative AI technology to automate the data extraction process, eliminating the need for manual entry. Evolution AI is trusted by global industry leaders and offers exceptional customer service, advanced technology, and a one-stop shop for data extraction.
Extracta.ai
Extracta.ai is an AI data extraction tool for documents and images that automates data extraction processes with easy integration. It allows users to define custom templates for extracting structured data without the need for training. The platform can extract data from various document types, including invoices, resumes, contracts, receipts, and more, providing accurate and efficient results. Extracta.ai ensures data security, encryption, and GDPR compliance, making it a reliable solution for businesses looking to streamline document processing.
NuMind
NuMind is an AI tool designed to solve information extraction tasks efficiently. It offers high-quality lightweight models tailored to users' needs, automating classification, entity recognition, and structured extraction. The tool is powered by task-specific and domain-agnostic foundation models, outperforming GPT-4 and similar models. NuMind provides solutions for various industries such as insurance and healthcare, ensuring privacy, cost-effectiveness, and faster NLP projects.
Airparser
Airparser is an AI-powered email and document parser tool that revolutionizes data extraction by utilizing the GPT parser engine. It allows users to automate the extraction of structured data from various sources such as emails, PDFs, documents, and handwritten texts. With features like automatic extraction, export to multiple platforms, and support for multiple languages, Airparser simplifies data extraction processes for individuals and businesses. The tool ensures data security and offers seamless integration with other applications through APIs and webhooks.
Jsonify
Jsonify is an AI tool that automates the process of exploring and understanding websites to find, filter, and extract structured data at scale. It uses AI-powered agents to navigate web content, replacing traditional data scrapers and providing data insights with speed and precision. Jsonify integrates with leading data analysis and business intelligence suites, allowing users to visualize and gain insights into their data easily. The tool offers a no-code dashboard for creating workflows and easily iterating on data tasks. Jsonify is trusted by companies worldwide for its ability to adapt to page changes, learn as it runs, and provide technical and non-technical integrations.
Kudra
Kudra is an AI-powered data extraction tool that offers dedicated solutions for finance, human resources, logistics, legal, and more. It effortlessly extracts critical data fields, tables, relationships, and summaries from various documents, transforming unstructured data into actionable insights. Kudra provides customizable AI models, seamless integrations, and secure document processing while supporting over 20 languages. With features like custom workflows, model training, API integration, and workflow builder, Kudra aims to streamline document processing for businesses of all sizes.
AgentQL
AgentQL is an AI-powered tool for painless data extraction and web automation. It eliminates the need for fragile XPath or DOM selectors by using semantic selectors and natural language descriptions to find web elements reliably. With controlled output and deterministic behavior, AgentQL allows users to shape data exactly as needed. The tool offers features such as extracting data, filling forms automatically, and streamlining testing processes. It is designed to be user-friendly and efficient for developers and data engineers.
Dataku.ai
Dataku.ai is an advanced data extraction and analysis tool powered by AI technology. It offers seamless extraction of valuable insights from documents and texts, transforming unstructured data into structured, actionable information. The tool provides tailored data extraction solutions for various needs, such as resume extraction for streamlined recruitment processes, review insights for decoding customer sentiments, and leveraging customer data to personalize experiences. With features like market trend analysis and financial document analysis, Dataku.ai empowers users to make strategic decisions based on accurate data. The tool ensures precision, efficiency, and scalability in data processing, offering different pricing plans to cater to different user needs.

Extractify.co
Extractify.co is a website that offers a variety of tools and services for extracting information from different sources. The platform provides users with the ability to extract data from websites, documents, and other sources in a quick and efficient manner. With a user-friendly interface, Extractify.co aims to simplify the process of data extraction for individuals and businesses alike. Whether you need to extract text, images, or other types of data, Extractify.co has the tools to help you get the job done. The platform is designed to be intuitive and easy to use, making it accessible to users of all skill levels.
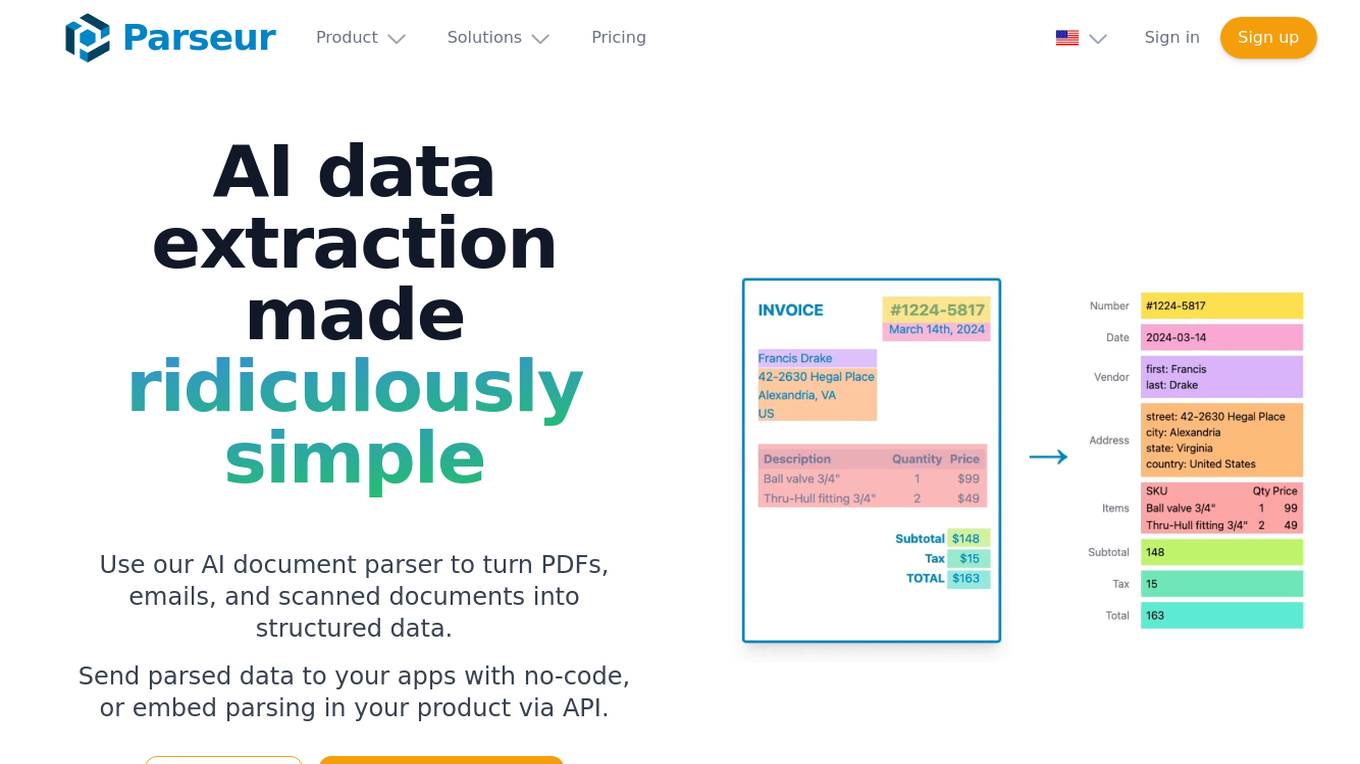
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.
DocuPipe
DocuPipe is an AI-powered document extraction tool that helps businesses convert various types of documents into structured data. It uses artificial intelligence to extract information from documents such as invoices, medical records, insurance claims, and more. DocuPipe offers custom definitions tailored for different businesses to accurately extract required data. The tool ensures security and compliance by encrypting documents and being GDPR and HIPAA compliant. With features like OCR, document standardization, and document splitting, DocuPipe provides accuracy, flexibility, and speed in handling documents.
Browse AI
Browse AI is a powerful AI-powered data extraction platform that allows users to scrape and monitor data from any website without the need for coding. With Browse AI, users can easily extract data, monitor websites for changes, turn websites into APIs, and integrate data with over 7,000 apps. The platform offers prebuilt robots for various use cases like e-commerce, real estate, recruitment, and more. Browse AI is trusted by over 740,000 users worldwide for its reliability, scalability, and ease of use.
Eigen Technologies
Eigen Technologies is an AI-powered data extraction platform designed for business users to automate the extraction of data from various documents. The platform offers solutions for intelligent document processing and automation, enabling users to streamline business processes, make informed decisions, and achieve significant efficiency gains. Eigen's platform is purpose-built to deliver real ROI by reducing manual processes, improving data accuracy, and accelerating decision-making across industries such as corporates, banks, financial services, insurance, law, and manufacturing. With features like generative insights, table extraction, pre-processing hub, and model governance, Eigen empowers users to automate data extraction workflows efficiently. The platform is known for its unmatched accuracy, speed, and capability, providing customers with a flexible and scalable solution that integrates seamlessly with existing systems.
Receipt OCR API
Receipt OCR API by ReceiptUp is an advanced tool that leverages OCR and AI technology to extract structured data from receipt and invoice images. The API offers high accuracy and multilingual support, making it ideal for businesses worldwide to streamline financial operations. With features like multilingual support, high accuracy, support for multiple formats, accounting downloads, and affordability, Receipt OCR API is a powerful tool for efficient receipt management and data extraction.
Speck
Speck is a web automation tool that simplifies web data extraction using AI technology. It allows users to record their workflows and then automate the process with the help of an AI copilot. Speck learns from user interactions, ensuring efficient data extraction without the need for constant manual adjustments. The tool offers features such as custom workflow automation, web data supercharger, smart browser navigation, intelligent form filler, and interactive web tutorials. Speck is designed to streamline web tasks and enhance productivity by automating repetitive processes.
Extracto.bot
Extracto.bot is an AI web scraping tool that automates the process of extracting data from websites. It is a no-configuration, intelligent web scraper that allows users to collect data from any site using Google Sheets and AI technology. The tool is designed to be simple, instant, and intelligent, enabling users to save time and effort in collecting and organizing data for various purposes.
Koncile
Koncile is an AI-powered OCR solution that automates data extraction from various documents. It combines advanced OCR technology with large language models to transform unstructured data into structured information. Koncile can extract data from invoices, accounting documents, identity documents, and more, offering features like categorization, enrichment, and database integration. The tool is designed to streamline document management processes and accelerate data processing. Koncile is suitable for businesses of all sizes, providing flexible subscription plans and enterprise solutions tailored to specific needs.
YTVidHub
YTVidHub is an AI-powered tool designed for bulk YouTube subtitle extraction and analysis. It offers a suite of features to efficiently download subtitles in various formats, clean transcripts, and generate AI summaries. The tool is trusted by professionals worldwide for its accuracy, speed, and convenience in handling large-scale subtitle extraction tasks.
MapsScraperAI
MapsScraperAI is an AI-powered tool designed to extract leads and data from Maps. It offers businesses the ability to generate local B2B leads, conduct research, monitor competition, and obtain business contact details. With features like batch lookup, lightning-fast results, and the unique ability to extract email addresses, MapsScraperAI streamlines the process of data extraction without the need for coding. The tool mimics real user behavior to reduce the risk of being blocked by Maps and ensures timely updates to accommodate any changes on the Maps website.
1 - Open Source Tools

baml
BAML is a config file format for declaring LLM functions that you can then use in TypeScript or Python. With BAML you can Classify or Extract any structured data using Anthropic, OpenAI or local models (using Ollama) ## Resources  [Discord Community](https://discord.gg/boundaryml)  [Follow us on Twitter](https://twitter.com/boundaryml) * Discord Office Hours - Come ask us anything! We hold office hours most days (9am - 12pm PST). * Documentation - Learn BAML * Documentation - BAML Syntax Reference * Documentation - Prompt engineering tips * Boundary Studio - Observability and more #### Starter projects * BAML + NextJS 14 * BAML + FastAPI + Streaming ## Motivation Calling LLMs in your code is frustrating: * your code uses types everywhere: classes, enums, and arrays * but LLMs speak English, not types BAML makes calling LLMs easy by taking a type-first approach that lives fully in your codebase: 1. Define what your LLM output type is in a .baml file, with rich syntax to describe any field (even enum values) 2. Declare your prompt in the .baml config using those types 3. Add additional LLM config like retries or redundancy 4. Transpile the .baml files to a callable Python or TS function with a type-safe interface. (VSCode extension does this for you automatically). We were inspired by similar patterns for type safety: protobuf and OpenAPI for RPCs, Prisma and SQLAlchemy for databases. BAML guarantees type safety for LLMs and comes with tools to give you a great developer experience:  Jump to BAML code or how Flexible Parsing works without additional LLM calls. | BAML Tooling | Capabilities | | ----------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | BAML Compiler install | Transpiles BAML code to a native Python / Typescript library (you only need it for development, never for releases) Works on Mac, Windows, Linux  | | VSCode Extension install | Syntax highlighting for BAML files Real-time prompt preview Testing UI | | Boundary Studio open (not open source) | Type-safe observability Labeling |
20 - OpenAI Gpts
Procedure Extraction and Formatting
Extracts and formats procedures from manuals into templates
FREE Keyword Extraction Tool
Keyword Extraction Tool: Efficiently extracts keywords from various texts, social media, and customer feedback with our user-friendly, scalable tool.
Data Extractor Pro
Expert in data extraction and context-driven analysis. Can read most filetypes including PDFS, XLSX, Word, TXT, CSV, EML, Etc.

Learn Chinese
Chinese teacher for text extraction, reading, Pinyin, explanations, and dialogue practice.
Property Manager Document Assistant
Provides analysis and data extraction of Property Management documents and contracts for managers
Acid Extractor Assistant
Hello Acid Extractor! I'm your dedicated Acid Extractor Assistant here to assist you with all your acid extraction needs. Let's work together for successful extractions!

Lilli
Lilli is a generative AI, designed for rapid data analysis and knowledge extraction to enhance consulting efficiency


QCM
ce GPT va recevoir des images dans lesquelles il y a des questions QCM codingame ou Problem Solving sur les sujets : Java, Hibernate, Angular, Spring Boot, SQL. Il doit extraire le texte depuis l'image et répondre au question QCM le plus rapidement possible.
PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.