Best AI tools for< Document Extraction >
Infographic
20 - AI tool Sites
DocuPipe
DocuPipe is an AI-powered document extraction tool that helps businesses convert various types of documents into structured data. It uses artificial intelligence to extract information from documents such as invoices, medical records, insurance claims, and more. DocuPipe offers custom definitions tailored for different businesses to accurately extract required data. The tool ensures security and compliance by encrypting documents and being GDPR and HIPAA compliant. With features like OCR, document standardization, and document splitting, DocuPipe provides accuracy, flexibility, and speed in handling documents.
Infrrd
Infrrd is an intelligent document automation platform that offers advanced document extraction solutions. It leverages AI technology to enhance, classify, extract, and review documents with high accuracy, eliminating the need for human review. Infrrd provides effective process transformation solutions across various industries, such as mortgage, invoice, insurance, and audit QC. The platform is known for its world-class document extraction engine, supported by over 10 patents and award-winning algorithms. Infrrd's AI-powered automation streamlines document processing, improves data accuracy, and enhances operational efficiency for businesses.
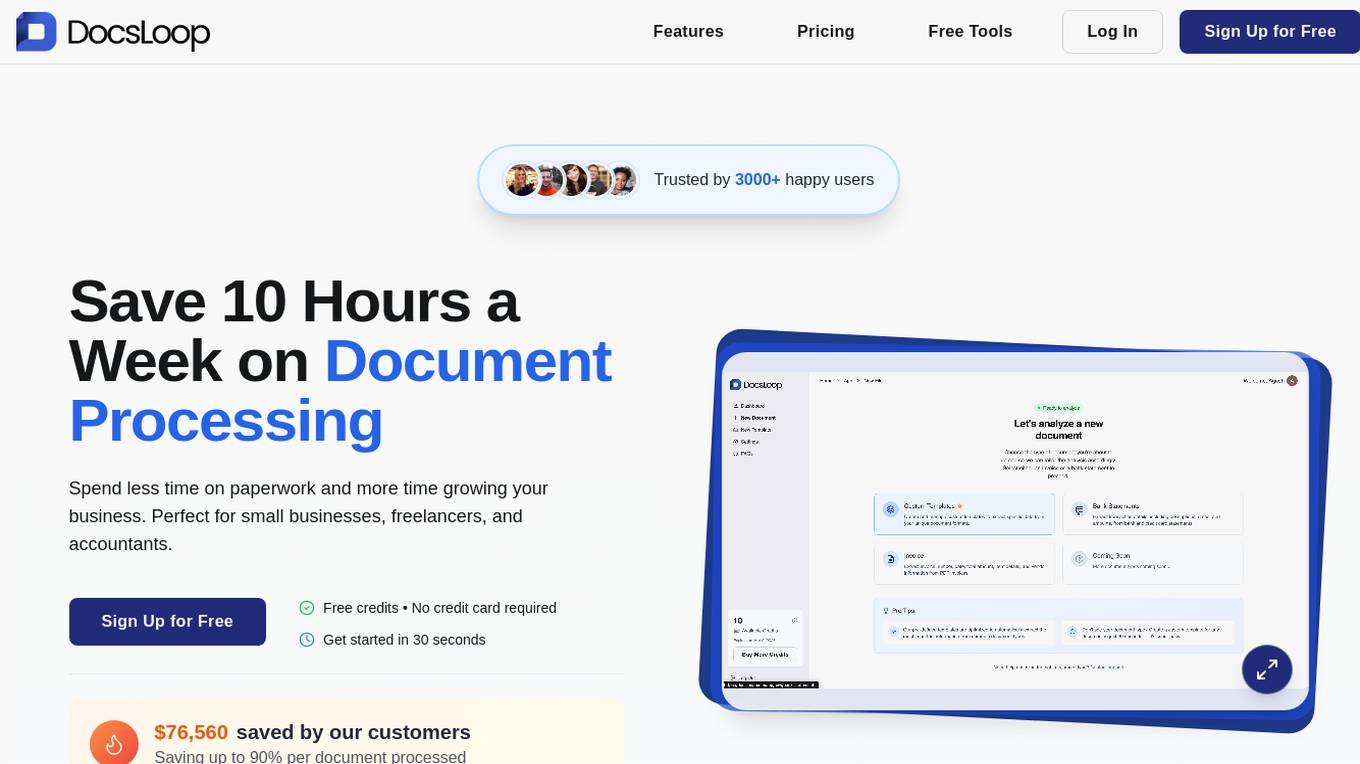
DocsLoop
DocsLoop is a document extraction tool designed to simplify and automate document processing tasks for businesses, freelancers, and accountants. It offers a user-friendly interface, high accuracy in data extraction, and fully automated processing without the need for technical skills or human intervention. With DocsLoop, users can save hours every week by effortlessly extracting structured data from various document types, such as invoices and bank statements, and export it in their preferred format. The platform provides pay-as-you-go pricing plans with credits that never expire, catering to different user needs and business sizes.

Veryfi
Veryfi is an OCR API tool for invoice and receipt data extraction. It offers fast, accurate, and secure document capture and data extraction on any type of document. Veryfi empowers users to process documents efficiently, automate manual data entry, and implement AI into various business processes. The tool is designed to streamline workflows, enhance accuracy, and unlock new levels of efficiency across industries such as finance, insurance, and more.

PaperEntry AI
Deep Cognition offers PaperEntry AI, an Intelligent Document Processing solution powered by generative AI. It automates data entry tasks with high accuracy, scalability, and configurability, handling complex documents of any type or format. The application is trusted by leading global organizations for customs clearance automation and government document processing, delivering significant time and cost savings. With industry-specific features and a proven track record, Deep Cognition provides a state-of-the-art solution for businesses seeking efficient data extraction and automation.
Macgence AI Training Data Services
Macgence is an AI training data services platform that offers high-quality off-the-shelf structured training data for organizations to build effective AI systems at scale. They provide services such as custom data sourcing, data annotation, data validation, content moderation, and localization. Macgence combines global linguistic, cultural, and technological expertise to create high-quality datasets for AI models, enabling faster time-to-market across the entire model value chain. With more than 5 years of experience, they support and scale AI initiatives of leading global innovators by designing custom data collection programs. Macgence specializes in handling AI training data for text, speech, image, and video data, offering cognitive annotation services to unlock the potential of unstructured textual data.
Weavely
Weavely is an AI form builder that offers instant smart forms for various purposes such as contact forms, surveys, event registrations, feedback forms, and lead generation forms. It provides a free and smarter alternative to Google Forms and Typeform, allowing users to create custom forms effortlessly using AI technology. Weavely's AI-powered platform simplifies the form-building process by automatically generating form fields based on user prompts, voice inputs, PDF uploads, and document extractions. The tool also offers effortless styling and branding, multistep flows, conditional logic, answer piping, and a wide range of form elements to enhance user experience. Weavely is designed to help businesses gather structured feedback, capture high-quality leads, validate ideas, and improve customer experience through data-driven campaigns.
Swiftask
Swiftask is an all-in-one AI Assistant designed to enhance individual and team productivity and creativity. It integrates a range of AI technologies, chatbots, and productivity tools into a cohesive chat interface. Swiftask offers features such as generating text, language translation, creative content writing, answering questions, extracting text from images and PDFs, table and form extraction, audio transcription, speech-to-text conversion, AI-based image generation, and project management capabilities. Users can benefit from Swiftask's comprehensive AI solutions to work smarter and achieve more.
Mindee Platform
Mindee Platform is an AI Document Data Extraction API that offers end-to-end document-based workflows automation. It provides pre-built API catalog, custom document understanding, and continuous learning capabilities. The platform enables users to automate invoice processing, receipt extraction, and document management with high accuracy and scalability. Mindee's AI models support structured, semi-structured, and unstructured documents, making it a versatile solution for various industries. With features like RAG-enhanced continuous learning, security compliance, and table extraction technology, Mindee offers a comprehensive document automation platform for businesses and developers.
AlgoDocs
AlgoDocs is a powerful AI Platform developed based on the latest technologies to streamline your processes and free your team from annoying and error-prone manual data entry by offering fast, secure, and accurate document data extraction.
Collate
Collate is a local-first AI tool designed for PDF analysis, chat, and summaries. It operates entirely on your Mac without the need for an internet connection, ensuring complete privacy and security for your data. With Collate, users can ask questions, receive instant summaries, and extract key insights from any document quickly and efficiently. The application simplifies the process of turning lengthy PDFs into actionable insights, allowing users to chat with their documents and generate concise summaries effortlessly. Collate is a user-friendly and powerful tool for individuals looking to streamline their document analysis workflow.

Doc2cart
Doc2cart is an AI-powered platform that automates the extraction of product information from various documents such as invoices, price lists, and catalogs. It utilizes advanced OCR technology to convert paper or digital documents into structured e-commerce data that can be seamlessly integrated into popular e-commerce platforms and shopping carts. The platform focuses on data extraction and processing, providing users with the flexibility to utilize the extracted data in their systems efficiently.
Base64.ai
Base64.ai is an AI-powered document intelligence platform that offers a comprehensive solution for document processing and data extraction. It leverages advanced AI technology to streamline workflows, improve accuracy, and drive digital transformation for organizations. With features like Generative AI agents, workflow automation, and data intelligence, Base64.ai enables users to extract insights from structured and unstructured documents with ease. The platform is designed to enhance efficiency, reduce processing time, and increase productivity by eliminating manual document processing tasks.
Dataku.ai
Dataku.ai is an advanced data extraction and analysis tool powered by AI technology. It offers seamless extraction of valuable insights from documents and texts, transforming unstructured data into structured, actionable information. The tool provides tailored data extraction solutions for various needs, such as resume extraction for streamlined recruitment processes, review insights for decoding customer sentiments, and leveraging customer data to personalize experiences. With features like market trend analysis and financial document analysis, Dataku.ai empowers users to make strategic decisions based on accurate data. The tool ensures precision, efficiency, and scalability in data processing, offering different pricing plans to cater to different user needs.
Doclingo
Doclingo is an AI-powered document translation tool that supports translating documents in various formats such as PDF, Word, Excel, PowerPoint, SRT subtitles, ePub ebooks, AR&ZIP packages, and more. It utilizes large language models to provide accurate and professional translations, preserving the original layout of the documents. Users can enjoy a limited-time free trial upon registration, with the option to subscribe for more features. Doclingo aims to offer high-quality translation services through continuous algorithm improvements.
Receipt OCR API
Receipt OCR API by ReceiptUp is an advanced tool that leverages OCR and AI technology to extract structured data from receipt and invoice images. The API offers high accuracy and multilingual support, making it ideal for businesses worldwide to streamline financial operations. With features like multilingual support, high accuracy, support for multiple formats, accounting downloads, and affordability, Receipt OCR API is a powerful tool for efficient receipt management and data extraction.
Docsumo
Docsumo is an advanced Document AI platform designed for scalability and efficiency. It offers a wide range of capabilities such as pre-processing documents, extracting data, reviewing and analyzing documents. The platform provides features like document classification, touchless processing, ready-to-use AI models, auto-split functionality, and smart table extraction. Docsumo is a leader in intelligent document processing and is trusted by various industries for its accurate data extraction capabilities. The platform enables enterprises to digitize their document processing workflows, reduce manual efforts, and maximize data accuracy through its AI-powered solutions.
Eigen Technologies
Eigen Technologies is an AI-powered data extraction platform designed for business users to automate the extraction of data from various documents. The platform offers solutions for intelligent document processing and automation, enabling users to streamline business processes, make informed decisions, and achieve significant efficiency gains. Eigen's platform is purpose-built to deliver real ROI by reducing manual processes, improving data accuracy, and accelerating decision-making across industries such as corporates, banks, financial services, insurance, law, and manufacturing. With features like generative insights, table extraction, pre-processing hub, and model governance, Eigen empowers users to automate data extraction workflows efficiently. The platform is known for its unmatched accuracy, speed, and capability, providing customers with a flexible and scalable solution that integrates seamlessly with existing systems.
FormX.ai
FormX.ai is an AI-powered data extraction and conversion tool that automates the process of extracting data from physical documents and converting it into digital formats. It supports a wide range of document types, including invoices, receipts, purchase orders, bank statements, contracts, HR forms, shipping orders, loyalty member applications, annual reports, business certificates, personnel licenses, and more. FormX.ai's pre-configured data extraction models and effortless API integration make it easy for businesses to integrate data extraction into their existing systems and workflows. With FormX.ai, businesses can save time and money on manual data entry and improve the accuracy and efficiency of their data processing.
Extracta.ai
Extracta.ai is an AI data extraction tool for documents and images that automates data extraction processes with easy integration. It allows users to define custom templates for extracting structured data without the need for training. The platform can extract data from various document types, including invoices, resumes, contracts, receipts, and more, providing accurate and efficient results. Extracta.ai ensures data security, encryption, and GDPR compliance, making it a reliable solution for businesses looking to streamline document processing.
1 - Open Source Tools

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.
20 - OpenAI Gpts
Property Manager Document Assistant
Provides analysis and data extraction of Property Management documents and contracts for managers

Ringkesan
Nyimpulkeun sareng nimba poin konci tina téks, artikel, video, dokumén sareng seueur deui

Fill PDF Forms
Fill legal forms & complex PDF documents easily! Upload a file, provide data sources and I'll handle the rest.


Law Document
Convert simple documents and notes into supported legal terminology. Copyright (C) 2024, Sourceduty - All Rights Reserved.


Refine Product Management Enhancement Document
I help refine product enhancements. Logic - Essential Details - Business Value
LaTeX Picture & Document Transcriber
Convert into usable LaTeX code any pictures of your handwritten notes, documents in any format. Start by uploading what you need to convert.

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Florida Entrepreneur Startup Documents Package
Startup document generator for Florida entrepreneurs.