Best AI tools for< Data Annotator >
Infographic
20 - AI tool Sites
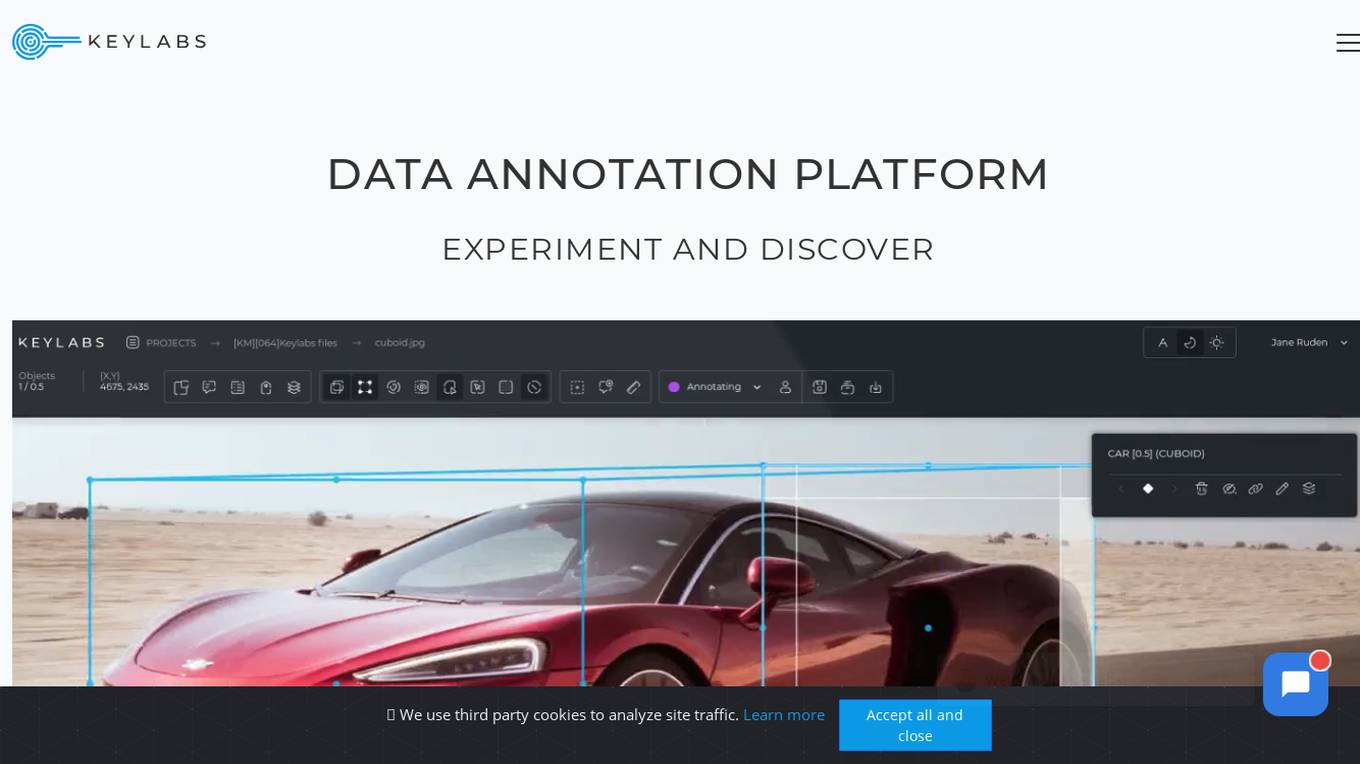
Keylabs
Keylabs is a state-of-the-art data annotation platform that enhances AI projects with highly precise data annotation and innovative tools. It offers image and video annotation, labeling, and ML-assisted features for industries such as automotive, aerial, agriculture, robotics, manufacturing, waste management, medical, healthcare, retail, fashion, sports, security, livestock, construction, and logistics. Keylabs provides advanced annotation tools, built-in machine learning, efficient operation management, and extra high performance to boost the preparation of visual data for machine learning. The platform ensures transparency in pricing with no hidden fees and offers a free trial for users to experience its capabilities.
Surge AI
Surge AI is a data labeling platform that provides human-generated data for training and evaluating large language models (LLMs). It offers a global workforce of annotators who can label data in over 40 languages. Surge AI's platform is designed to be easy to use and integrates with popular machine learning tools and frameworks. The company's customers include leading AI companies, research labs, and startups.

Cogniroot
Cogniroot is an AI-powered platform that helps businesses automate their data annotation and data labeling processes. It provides a suite of tools and services that make it easy for businesses to train their machine learning models with high-quality data. Cogniroot's platform is designed to be scalable, efficient, and cost-effective, making it a valuable tool for businesses of all sizes.
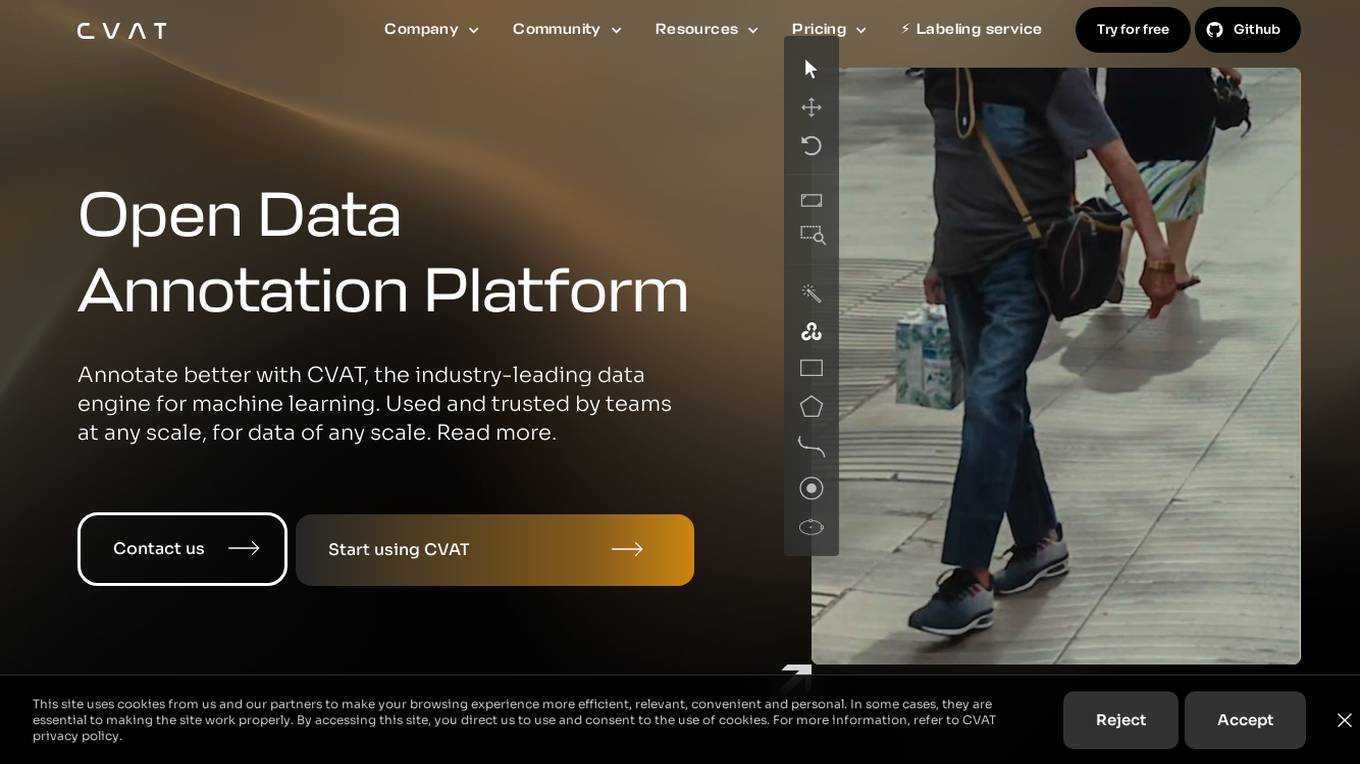
CVAT
CVAT is an open-source data annotation platform that helps teams of any size annotate data for machine learning. It is used by companies big and small in a variety of industries, including healthcare, retail, and automotive. CVAT is known for its intuitive user interface, advanced features, and support for a wide range of data formats. It is also highly extensible, allowing users to add their own custom features and integrations.
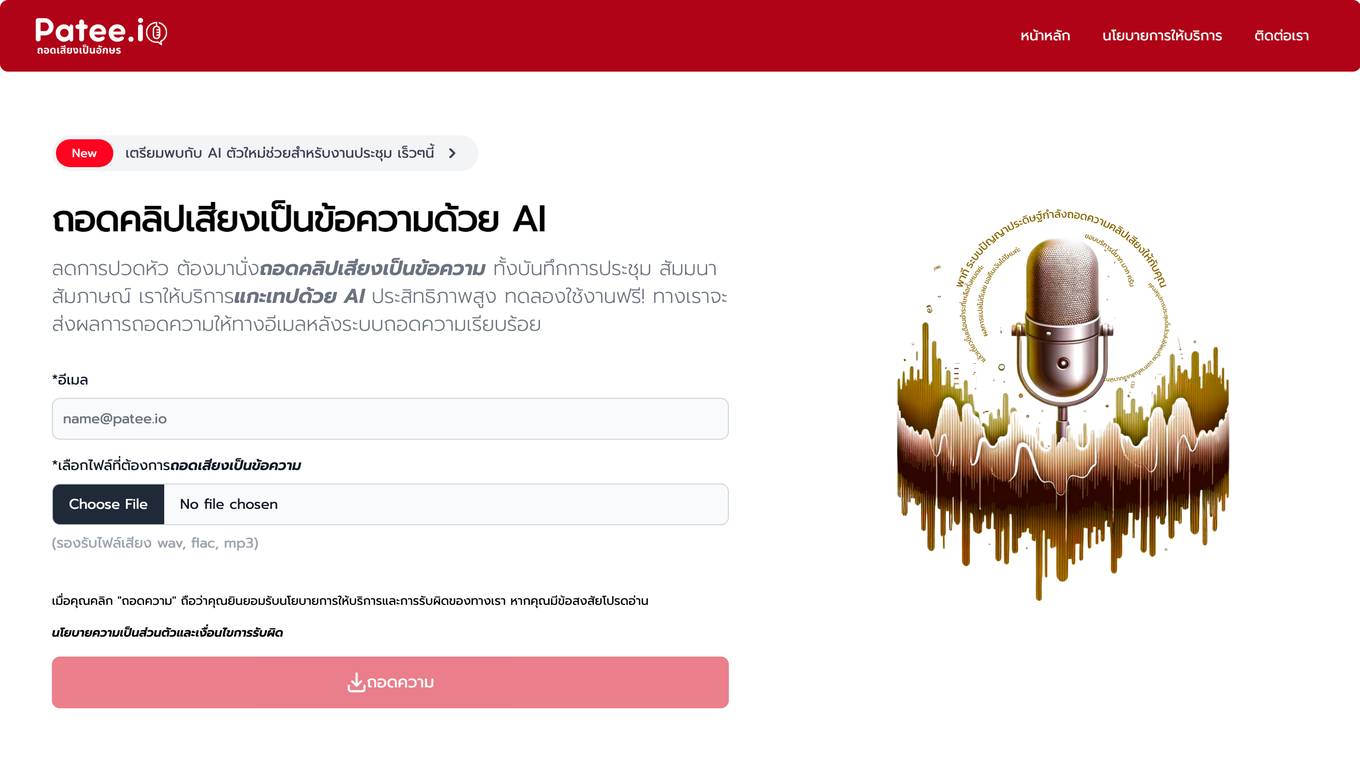
Patee.io
Patee.io is an AI-powered platform that helps businesses automate their data annotation and labeling tasks. With Patee.io, businesses can easily create, manage, and annotate large datasets, which can then be used to train machine learning models. Patee.io offers a variety of features that make it easy to annotate data, including a user-friendly interface, a variety of annotation tools, and the ability to collaborate with others. Patee.io also offers a number of pre-built models that can be used to automate the annotation process, saving businesses time and money.
OpenTrain AI
OpenTrain AI is a data labeling marketplace that leverages artificial intelligence to streamline the process of labeling data for machine learning models. It provides a platform where users can crowdsource data labeling tasks to a global community of annotators, ensuring high-quality labeled datasets for training AI algorithms. With advanced AI algorithms and human-in-the-loop validation, OpenTrain AI offers efficient and accurate data labeling services for various industries such as autonomous vehicles, healthcare, and natural language processing.
Aya Data
Aya Data is an AI tool that offers services such as data annotation, computer vision, natural language annotation, 3D annotation, AI data acquisition, and AI consulting. They provide cutting-edge tools to transform raw data into training datasets for AI models, deliver bespoke AI solutions for various industries, and offer AI-powered products like AyaGrow for crop management and AyaSpeech for speech-to-speech translation. Aya Data focuses on exceptional accuracy, rapid development cycles, and high performance in real-world scenarios.
Cogitotech
Cogitotech is an AI tool that specializes in data annotation and labeling expertise. The platform offers a comprehensive suite of services tailored to meet training data needs for computer vision models and AI applications. With a decade-long industry exposure, Cogitotech provides high-quality training data for industries like healthcare, financial services, security, and more. The platform helps minimize biases in AI algorithms and ensures accurate and reliable training data solutions for deploying AI in real-life systems.
Globose Technology Solutions
Globose Technology Solutions Pvt Ltd (GTS) is an AI data collection company that provides various datasets such as image datasets, video datasets, text datasets, speech datasets, etc., to train machine learning models. They offer premium data collection services with a human touch, aiming to refine AI vision and propel AI forward. With over 25+ years of experience, they specialize in data management, annotation, and effective data collection techniques for AI/ML. The company focuses on unlocking high-quality data, understanding AI's transformative impact, and ensuring data accuracy as the backbone of reliable AI.
Innodata Inc.
Innodata Inc. is a global data engineering company that delivers AI-enabled software platforms and managed services for AI data collection/annotation, AI digital transformation, and industry-specific business processes. They provide a full-suite of services and products to power data-centric AI initiatives using artificial intelligence and human expertise. With a 30+ year legacy, they offer the highest quality data and outstanding service to their customers.
Encord
Encord is a leading data development platform designed for computer vision and multimodal AI teams. It offers a comprehensive suite of tools to manage, clean, and curate data, streamline labeling and workflow management, and evaluate AI model performance. With features like data indexing, annotation, and active model evaluation, Encord empowers users to accelerate their AI data workflows and build robust models efficiently.
Macgence AI Training Data Services
Macgence is an AI training data services platform that offers high-quality off-the-shelf structured training data for organizations to build effective AI systems at scale. They provide services such as custom data sourcing, data annotation, data validation, content moderation, and localization. Macgence combines global linguistic, cultural, and technological expertise to create high-quality datasets for AI models, enabling faster time-to-market across the entire model value chain. With more than 5 years of experience, they support and scale AI initiatives of leading global innovators by designing custom data collection programs. Macgence specializes in handling AI training data for text, speech, image, and video data, offering cognitive annotation services to unlock the potential of unstructured textual data.
Pulan
Pulan is a comprehensive platform designed to assist in collecting, curating, annotating, and evaluating data points for various AI initiatives. It offers services in Natural Language Processing, Data Annotation, and Computer Vision across multiple industries such as Agriculture, Medical, Life Sciences, Government, Automotive, Insurance & Finance, Logistics, Software & Internet, Manufacturing, Retail, Construction, Energy, and Food & Beverage. Pulan provides a one-stop destination for reliable data collection and curation by industry experts, with a vast inventory of millions of datasets available for licensing at a fraction of the cost of creating the data oneself.
Toloka AI
Toloka AI is a data labeling platform that empowers AI development by combining human insight with machine learning models. It offers adaptive AutoML, human-in-the-loop workflows, large language models, and automated data labeling. The platform supports various AI solutions with human input, such as e-commerce services, content moderation, computer vision, and NLP. Toloka AI aims to accelerate machine learning processes by providing high-quality human-labeled data and leveraging the power of the crowd.
Shaip
Shaip is a human-powered data processing service specializing in AI and ML models. They offer a wide range of services including data collection, annotation, de-identification, and more. Shaip provides high-quality training data for various AI applications, such as healthcare AI, conversational AI, and computer vision. With over 15 years of expertise, Shaip helps organizations unlock critical information from unstructured data, enabling them to achieve better results in their AI initiatives.
V7
V7 is an AI data engine for computer vision and generative AI. It provides a multimodal automation tool that helps users label data 10x faster, power AI products via API, build AI + human workflows, and reach 99% AI accuracy. V7's platform includes features such as automated annotation, DICOM annotation, dataset management, model management, image annotation, video annotation, document processing, and labeling services.
Datasaur
Datasaur is an advanced text and audio data labeling platform that offers customizable solutions for various industries such as LegalTech, Healthcare, Financial, Media, e-Commerce, and Government. It provides features like configurable annotation, quality control automation, and workforce management to enhance the efficiency of NLP and LLM projects. Datasaur prioritizes data security with military-grade practices and offers seamless integrations with AWS and other technologies. The platform aims to streamline the data labeling process, allowing engineers to focus on creating high-quality models.

DeepVinci
DeepVinci is an AI-powered platform that helps businesses automate their workflows and make better decisions. It offers a range of features, including data annotation, model training, and predictive analytics.
Anote
Anote is a human-centered AI company that provides a suite of products and services to help businesses improve their data quality and build better AI models. Anote's products include a data labeler, a private chatbot, a model inference API, and a lead generation tool. Anote's services include data annotation, model training, and consulting.
Roboflow
Roboflow is a platform that provides tools for building and deploying computer vision models. It offers a range of features, including data annotation, model training, and deployment. Roboflow is used by over 250,000 engineers to create datasets, train models, and deploy to production.
2 - Open Source Tools
scaleapi-python-client
The Scale AI Python SDK is a tool that provides a Python interface for interacting with the Scale API. It allows users to easily create tasks, manage projects, upload files, and work with evaluation tasks, training tasks, and Studio assignments. The SDK handles error handling and provides detailed documentation for each method. Users can also manage teammates, project groups, and batches within the Scale Studio environment. The SDK supports various functionalities such as creating tasks, retrieving tasks, canceling tasks, auditing tasks, updating task attributes, managing files, managing team members, and working with evaluation and training tasks.

LabelQuick
LabelQuick_V2.0 is a fast image annotation tool designed and developed by the AI Horizon team. This version has been optimized and improved based on the previous version. It provides an intuitive interface and powerful annotation and segmentation functions to efficiently complete dataset annotation work. The tool supports video object tracking annotation, quick annotation by clicking, and various video operations. It introduces the SAM2 model for accurate and efficient object detection in video frames, reducing manual intervention and improving annotation quality. The tool is designed for Windows systems and requires a minimum of 6GB of memory.
20 - OpenAI Gpts
Apple MapKit Complete Code Expert
A detailed expert trained on all 5,961 pages of Apple MapKit, offering complete coding solutions. Saving time? https://www.buymeacoffee.com/parkerrex ☕️❤️
Your Business Data Optimizer Pro
A chatbot expert in business data analysis and optimization.
Data Dynamo
A friendly data science coach offering practical, useful, and accurate advice.


DataKitchen DataOps and Data Observability GPT
A specialist in DataOps and Data Observability, aiding in data management and monitoring.

Alas Data Analytics Student Mentor
Salam mən Alas Academy-nin Data Analitika üzrə Süni İntellekt mentoruyam. Mənə istənilən sualı verə bilərsiniz :)

CannaIndustry Data Expert
Data trend analysis expert in cannabis, also skilled in image and data analysis, document generation, and web search.