Best AI tools for< Audiobook Author >
Infographic
20 - AI tool Sites
TEXTTOSPEECH.IM
TEXTTOSPEECH.IM is an advanced text to speech tool that utilizes artificial intelligence to convert text to lifelike audio. Users can easily generate and download high-quality speech in multiple languages and voice styles. The tool supports enhanced accessibility, cost-effective content creation, a wide range of voices, convenient offline use, high accuracy in speech synthesis, and cross-device compatibility for maximum flexibility.
Authors' Voice
Authors' Voice is a cutting-edge AI tool designed to convert text-based books into high-quality audiobooks efficiently and quickly. The platform utilizes state-of-the-art AI-based text-to-speech technology to provide clear and natural-sounding narration with varied pacing and inflection. Authors' Voice aims to cater to content creators, independent authors, and publishers by offering affordable and profitable solutions to tap into the fast-growing audiobook market.

BookBud.ai
BookBud.ai is a web-based service that enables self-published authors to create fiction and non-fiction books with the assistance of AI. Authors can publish their books in ebook, print book, and audiobook formats. The platform offers rapid, distribution-ready ebook files, collaboration for AI-augmented audiobooks, and a comprehensive publishing journey from idea to promotion. BookBud.ai aims to make self-publishing profitable and accessible, leveling the playing field for authors in the publishing industry.

BookBud.ai
BookBud.ai is a web-based service that enables self-published authors to create fiction and non-fiction books with the assistance of AI. Authors can publish their books in ebook, print book, and audiobook formats. The platform offers rapid and affordable book creation, distribution-ready ebook files, global platform presence, hassle-free distribution, and high-quality print book formatting. BookBud.ai aims to make self-publishing profitable and accessible to aspiring and established writers.
Acryl
Acryl is an AI-powered tool that helps parents create audiobooks for their children. With Acryl, parents can take photos of any book and have Acryl generate an audiobook from it. Acryl's audiobooks are dynamic and use a unique voice for each character in the book. Acryl also offers a variety of features to help parents manage their children's listening time, such as the ability to set time limits and track how much time their child has spent listening.
NovelistAI
NovelistAI is a cutting-edge website that harnesses the power of artificial intelligence to generate completely original novels, stories, and interactive books. With NovelistAI, you can create your own personalized reading experience by selecting from an array of genres and styles. You can also write your own stories using our intuitive AI-powered tools. Whether you're a seasoned author or just starting out, NovelistAI has something to offer everyone.
AudioBook Bot
AudioBook Bot is an AI-powered application that converts text into spoken audio, providing users with the convenience of listening to books and other text-based content. The tool utilizes advanced natural language processing and speech synthesis technologies to create high-quality audio renditions. Users can simply input text, and the bot will generate an audio version that can be played on various devices. With its user-friendly interface and efficient processing capabilities, AudioBook Bot offers a seamless experience for those who prefer listening over reading.

Novels AI
Novels AI is an AI-powered application that allows users to create personalized AI-generated stories where they are the hero. Users can customize characters, settings, and more to experience immersive AI-driven audiobooks tailored just for them. The app harnesses the power of artificial intelligence to bring stories to life with high-quality, realistic AI narration. Novels AI offers endless storytelling options across various genres, from romance to sci-fi, providing users with a unique and engaging listening experience.
PlayAI
PlayAI is a leading AI voice generator and text-to-speech platform that offers a wide range of features to create high-quality audio content. With over 206 natural-sounding voices in 30+ languages, users can generate multi-speaker AI voices indistinguishable from humans. The platform allows users to enhance audio with speech styles, pronunciations, and SSML tags, making it ideal for audiobooks, YouTube videos, podcasts, and more. PlayAI's AI voice generator works by converting written text into natural-sounding speech through advanced text-to-speech technology, with real-time conversion and customizability options. The platform also supports voice cloning, API integration, and industry-leading AI voice products for various applications.
ElevenReader
ElevenReader is a free read-aloud text app that elevates your listening experience by bringing any book, article, PDF, newsletter, or text to life with ultra-realistic AI narration. With a vast collection of literary classics, newsletters, and articles narrated with AI audio, ElevenReader offers a personalized audio experience with high-definition voices in 32 languages. Users can import their own content, create smart podcasts, and enjoy bimodal listening with synchronized highlighting. The app also features iconic voices and is available on iOS and Android devices.
Pozotron Studio
Pozotron Studio is an AI-powered software suite designed to simplify scripted audio production processes for audiobooks, voiceovers, and other audio projects. It leverages state-of-the-art technology to enhance efficiency and accuracy in audio production, while allowing users to focus on creativity and core features. The tool automates tasks such as generating DAW marker files, pronunciation research, and script preparation, providing peace of mind about accuracy and highlighting errors for easy correction.
ElevenLabs
ElevenLabs is a text-to-speech (TTS) platform that uses artificial intelligence (AI) to generate realistic human-like voices. With ElevenLabs, you can convert any text into high-quality spoken audio in over 29 languages and 120 voices. The platform is easy to use and offers a variety of features, including the ability to adjust the voice's pitch, speed, and volume. You can also use ElevenLabs to create custom voices and clone your own voice. ElevenLabs is a powerful tool for content creators, businesses, and anyone who wants to create realistic spoken audio.
ElevenLabs
ElevenLabs is an AI voice generator and text-to-speech application that allows users to convert text into natural-sounding AI voices in various languages. The platform offers high-quality spoken audio with human intonation and inflections, suitable for video creators, developers, and businesses. Users can create lifelike voices for videos, gaming, audiobooks, chatbots, and more. ElevenLabs supports 29 languages and diverse accents, providing advanced AI text-to-speech technology for generating audio content.
Hume AI - Octave
Hume AI is an AI application that offers the Octave language model for text-to-speech (TTS) capabilities. It provides a voice-based LLM that understands words in context to predict emotions, cadence, and more. Users can create various AI voices with specific prompts and scripts, adjusting emotional delivery and speaking styles on command. The application aims to generate expressive AI voices for podcasts, voiceovers, audiobooks, and more, with total control over the voice output.
Audyo
Audyo is a text-to-speech tool that allows users to create realistic-sounding audio from text. With over 100 voices to choose from, users can create audio in a variety of languages and accents. Audyo is easy to use, simply type in your text and select a voice. You can then download your audio file or embed it on your website or blog. Audyo is a great tool for creating voiceovers for videos, podcasts, audiobooks, and more.
OddBooks
OddBooks is an AI-powered tool that transforms books into scenarios, enabling users to create various content types such as audiobooks, webtoons, animations, and movies. It simplifies the process of producing derivative works by extracting character names, emotions, spatial and sound keywords, and inferring character personalities from the text. With OddBooks, users can easily generate scripts for secondary works in a fraction of the time it would traditionally take, revolutionizing the scenario creation process.

Wavflow
Wavflow is an AI text-to-speech tool that converts written text into natural-sounding speech. It utilizes advanced artificial intelligence algorithms to generate high-quality audio output, making it ideal for various applications such as creating podcasts, voiceovers, audiobooks, and more. With a user-friendly interface and customizable options, Wavflow offers a seamless experience for users looking to transform text into speech effortlessly.

Atlanta Voiceover Studio
Atlanta Voiceover Studio is a professional voiceover training and recording studio based in Atlanta, GA. They offer a wide range of workshops and classes for voiceover artists of all levels, from beginners to experienced professionals. The studio provides training in various aspects of voiceover work, including animation, commercial voiceover, audiobook narration, and more. In addition to training, they also offer services such as auditions, demos, and business coaching to help voiceover artists succeed in the industry.
Auphonic
Auphonic is an AI-powered audio post-production web tool designed to help users achieve professional-quality audio results effortlessly. It offers a range of features such as Intelligent Leveler, Noise & Reverb Reduction, Filtering & AutoEQ, Cut Filler Words and Silence, Multitrack Algorithms, Loudness Specifications, Speech2Text & Automatic Shownotes, Video Support, Metadata & Chapters, and more. Auphonic is widely used by podcasters, educators, content creators, and audiobook producers to enhance their audio content and streamline their workflows. With its intuitive interface and advanced algorithms, Auphonic simplifies the audio editing process and ensures consistent audio quality across different platforms.
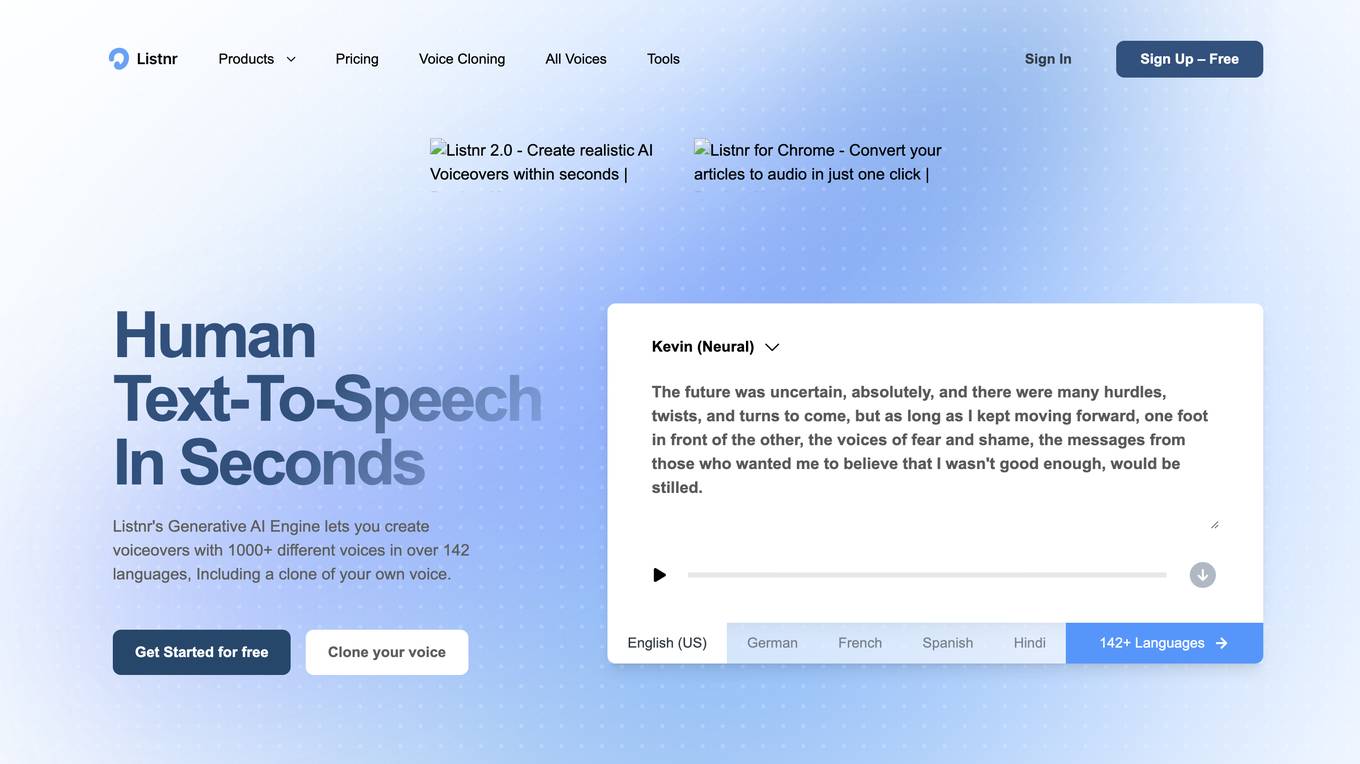
Listnr AI
Listnr AI is a leading AI voice generator tool that offers ultra-realistic AI voices indistinguishable from humans. With over 1000 different voices in more than 142 languages, including voice cloning capabilities, Listnr AI is trusted by 2,500,000+ users worldwide. The tool allows users to create voiceovers for various content types such as shorts, TikToks, YouTube videos, gaming, podcasts, sales, social media, and audiobooks. Listnr AI's state-of-the-art generative AI technology ensures that the voiceovers sound extremely natural, providing a seamless experience for content creators. Additionally, Listnr AI offers features like emotion fine-tuning, punctuations, pauses, and a wide range of multi-lingual voices to cater to diverse content needs.
0 - Open Source Tools
2 - OpenAI Gpts