Best AI tools for< Audio Transcription >
Infographic
20 - AI tool Sites

Vscoped
Vscoped is an AI-powered audio to text transcribing service that provides fast and accurate transcriptions in over 90 languages. It also offers transcription insights and translation services. Vscoped is suitable for various types of audio content, including business meetings, interviews, sales calls, and videos. With its exceptional accuracy, multilingual capabilities, and intuitive user experience, Vscoped helps businesses and individuals boost productivity and gain insights from their audio data.
Transcriptmate
Transcriptmate is an AI-powered audio to text transcription tool that offers automatic transcription with high accuracy. Users can easily convert audio files to text in just 2 clicks, with the option to add features like diarization and AI content crafting. The tool supports multiple languages, provides transcriptions in various formats, and ensures safe payments. Transcriptmate is recommended by customers for its efficiency, accuracy, and user-friendly interface.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
VidText AI
VidText AI is an advanced tool that offers video and audio to text transcription services with high accuracy and speed. It supports multiple languages, speaker recognition, and secure file management. Users can convert recordings, meetings, and videos into text or mind maps, making it convenient for various scenarios such as learning, meetings, and content creation. The tool also allows for easy summarization, chat interaction, and quick access to specific video positions from the transcribed text.
Transkriptor
Transkriptor is an AI-powered tool that allows users to convert audio or video files into text with high accuracy and efficiency. It supports over 100 languages and offers features like automatic transcription, translation, rich export options, and collaboration tools. With state-of-the-art AI technology, Transkriptor simplifies the transcription process for various purposes such as meetings, interviews, lectures, and more. The platform ensures fast, accurate, and affordable transcription services, making it a valuable tool for professionals and students across different industries.
DeVoice
DeVoice is an AI-powered audio and video transcription tool that allows users to convert any sound or video into precise text. It offers unlimited transcription with unmatched speed and accuracy, making it ideal for podcasters, content creators, and professionals who need fast and reliable transcriptions. DeVoice also provides additional features such as AI rap generation, background noise removal, and AI noise filtering to enhance audio quality. The tool ensures a seamless user experience with a user-friendly interface, affordable plans, fast processing, high accuracy, and customizable results. Privacy is prioritized, as all files are processed securely and deleted automatically after conversion.
Gladia
Gladia provides a fast and accurate way to turn unstructured audio data into valuable business knowledge. Its Audio Intelligence API helps capture, enrich, and leverage hidden insights in audio data, powered by optimized Whisper ASR. Key features include highly accurate audio and video transcription, speech-to-text translation in 99 languages, in-depth insights with add-ons, and secure hosting options. Gladia's AI transcription and multilingual audio intelligence features enhance user experience and boost retention in various industries, including content and media, virtual meetings, workspace collaboration, and call centers. Developers can easily integrate cutting-edge AI into their products without AI expertise or setup costs.
WavoAI
WavoAI is an AI-powered transcription and summarization tool that helps users transcribe audio recordings quickly and accurately. It offers features such as speaker identification, annotations, and interactive AI insights, making it a valuable tool for a wide range of professionals, including academics, filmmakers, podcasters, and journalists.
AudioTranscription.ai
AudioTranscription.ai is a fast, secure, and accurate AI-powered transcription tool for audio and video files. It offers lightning-speed transcriptions, accurate language transcriptions in over 70 languages, speaker identification, and a user-friendly dashboard for easy management. The tool also provides API access for seamless integration and hassle-free transcription services.
AutoRadiant
AutoRadiant is an AI-powered audio monitoring tool designed for businesses to enhance customer experience and optimize operations. It provides real-time audio transcription and insightful analytics, enabling efficient business operations accessible anytime and anywhere. With features like AI noise reduction, daily transcription summaries, and instant alerts, AutoRadiant helps businesses focus on meaningful customer interactions, turn conversations into actionable insights, and make data-driven decisions. The tool ensures top-notch security measures, strict privacy protocols, and full legal compliance to protect business and customer data.
Otter.ai
Otter.ai is an AI meeting assistant application that provides users with the ability to record audio, write notes, automatically capture slides, and generate meeting summaries. Users can collaborate with teammates in real-time, add comments, highlight key points, and assign action items. Otter.ai helps companies and organizations to write notes and summarize meetings 30 times faster. The application also offers features like automated slide capture and automated meeting notes, which can be connected to Google or Microsoft calendar to join and record meetings on platforms like Zoom, Microsoft Teams, and Google Meet. Otter.ai aims to streamline meeting processes and enhance productivity by leveraging AI technology.
Whisper API
Whisper API is an affordable transcription API that can be used to transcribe audio and video files. It is a cloud-based service that is easy to use and can be integrated with a variety of applications. Whisper API is powered by artificial intelligence, which allows it to transcribe audio and video files with high accuracy.
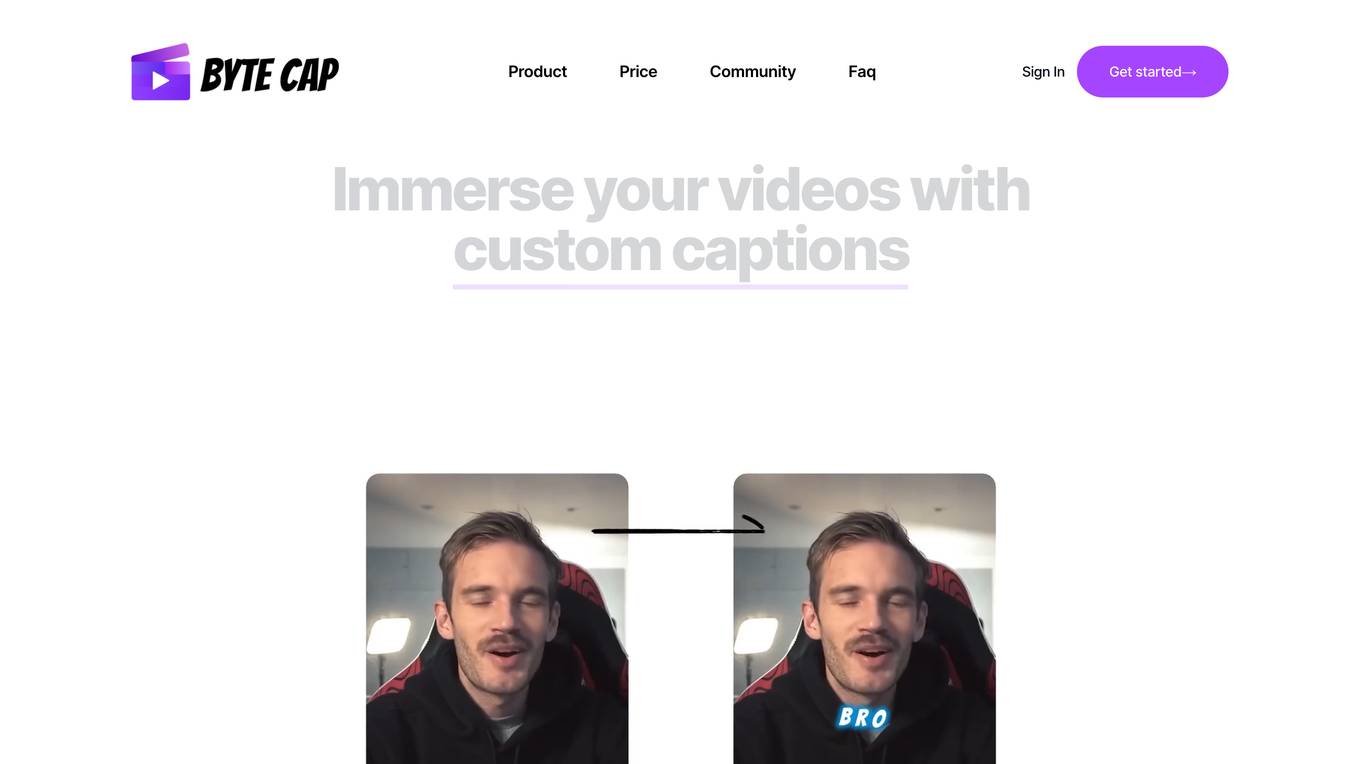
ByteCap
ByteCap is an AI-powered video editing tool that allows users to create engaging and captivating videos with custom AI captions. With advanced speech recognition technology, users can auto-create accurate captions in multiple languages. The tool also enables the creation of stunning faceless videos by incorporating AI images, voice, and captions. Users can personalize their videos with custom captions, images, emojis, effects, music, and highlights. ByteCap offers a range of features such as customizable AI faceless videos, support for various caption formats, trendy sounds, background music, and expertly crafted caption themes. It is a versatile solution for video editors, content creators, podcasters, and streamers to enhance their video content and reach a wider audience.
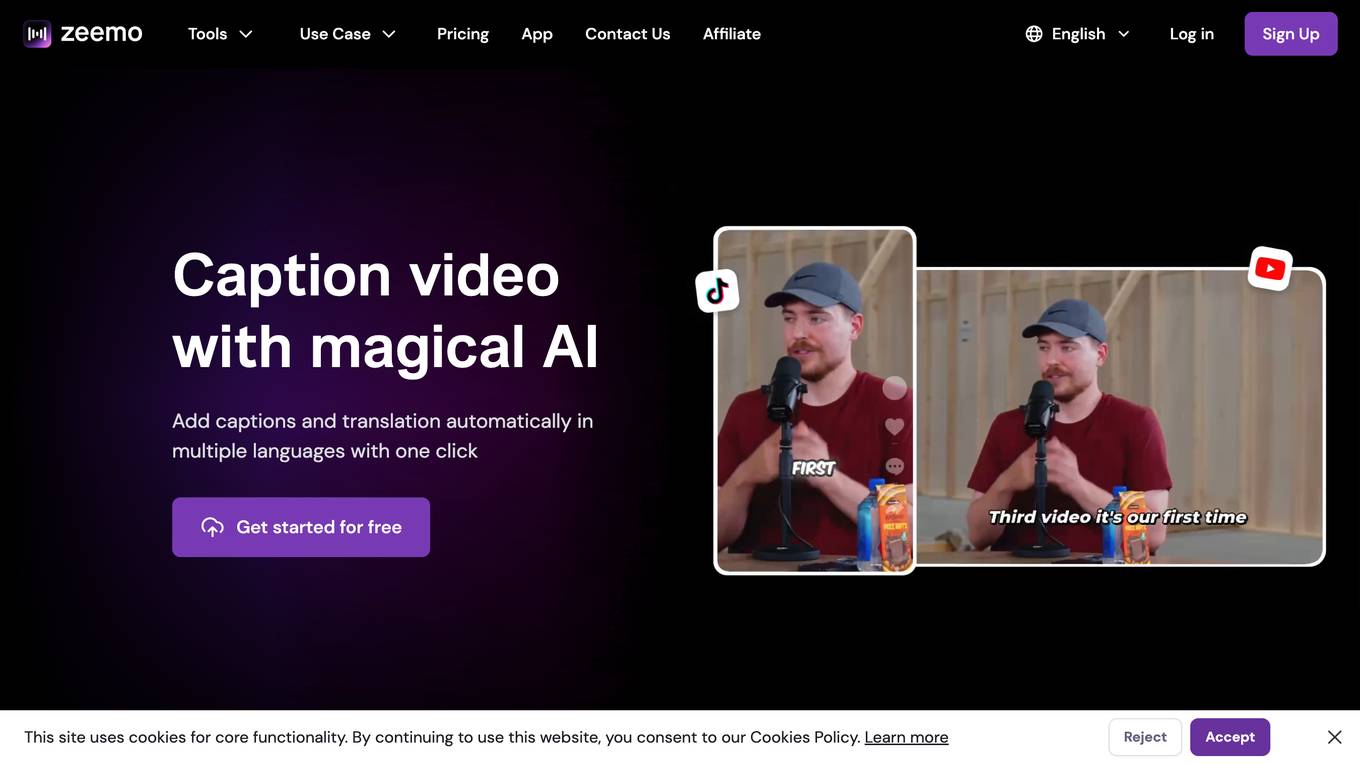
Zeemo AI
Zeemo AI is a powerful caption generator tool that enables users to add subtitles to videos, transcribe video and audio to text, and generate captions using AI technology. It supports multiple languages and provides dynamic visual effects for captions. The tool is designed for content creators, educators, and product sellers to enhance their videos and reach a wider audience across various platforms.
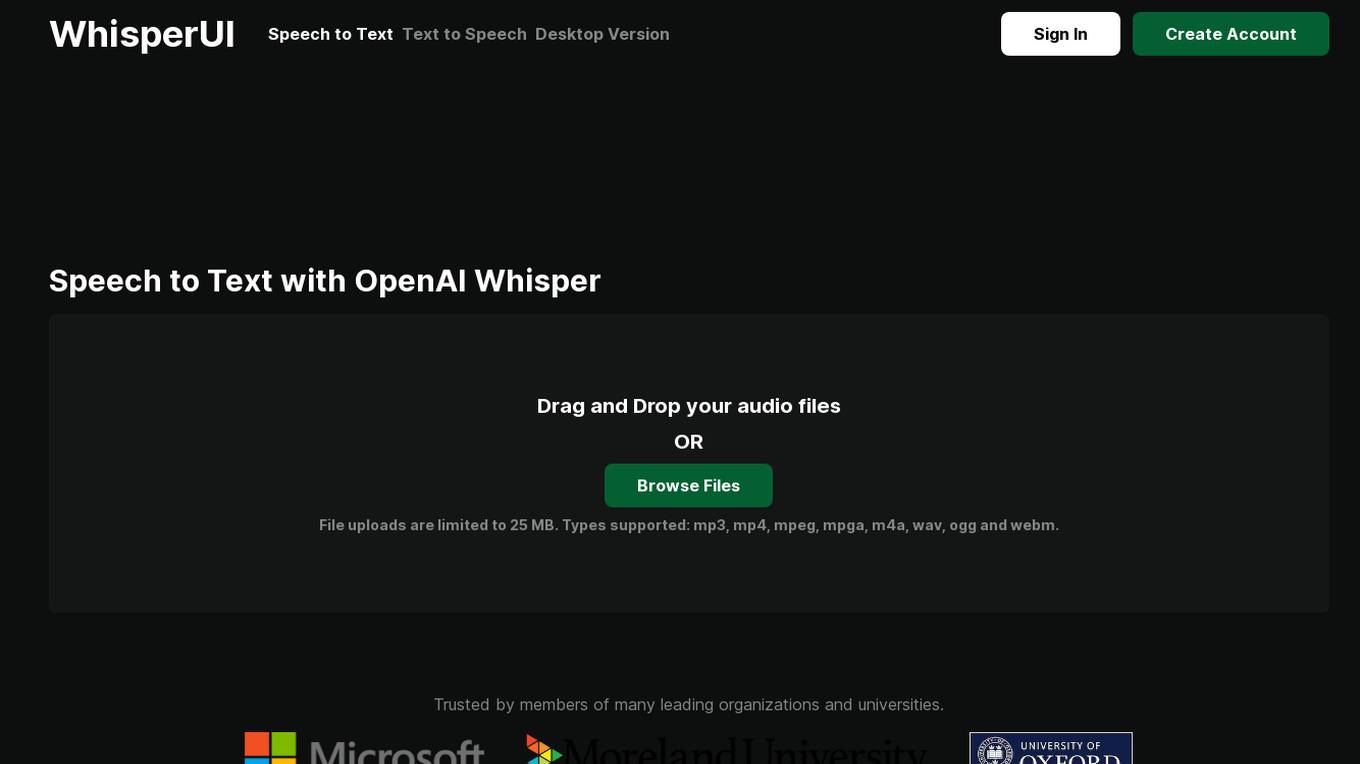
WhisperUI
WhisperUI is an affordable Speech to Text application powered by OpenAI Whisper. It allows users to easily convert audio files into text and SRT files with high accuracy. The application is trusted by members of leading organizations and universities. Users can upload various audio file formats and benefit from premium features such as uploading multiple files at once and unlimited daily file uploads. WhisperUI supports multiple languages and is known for its robustness in transcribing speech in the presence of accents, background noise, and technical language.
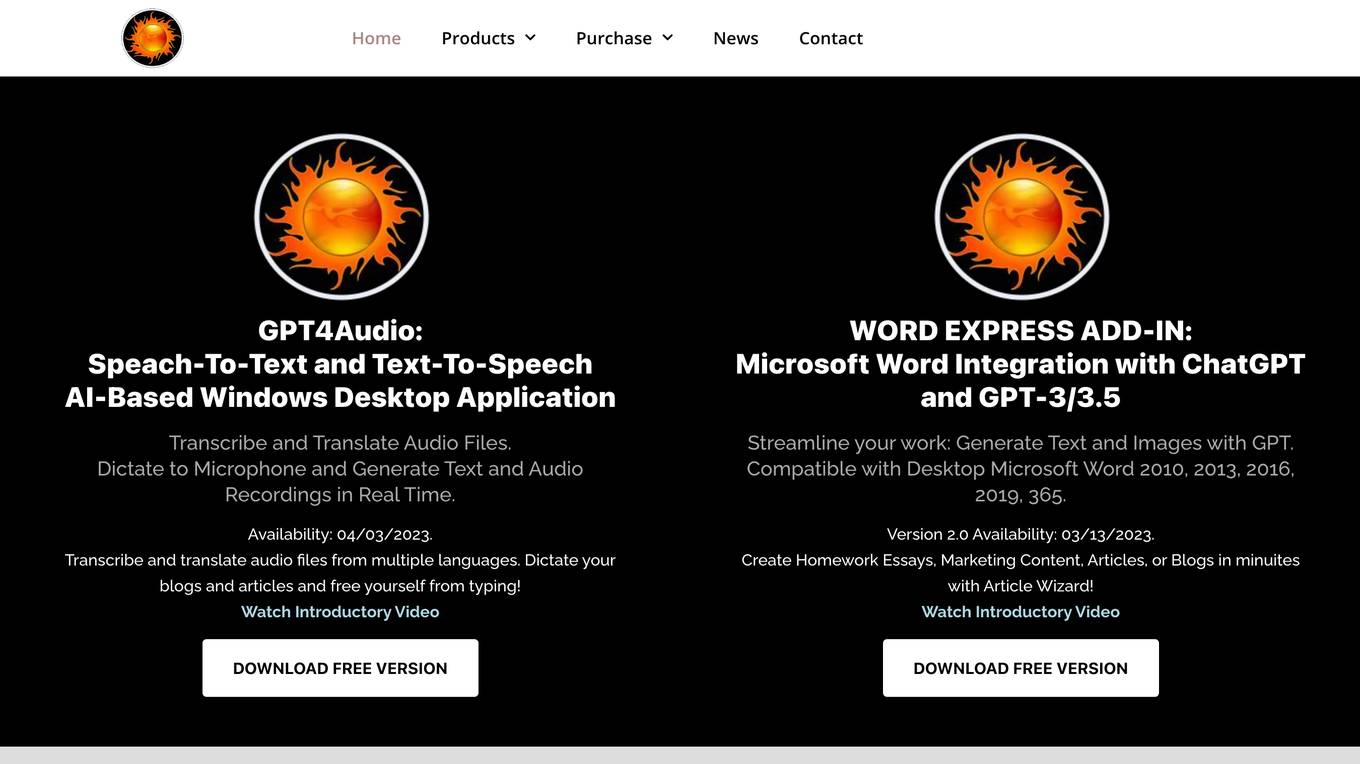
GPT4Audio
GPT4Audio is an AI-based desktop application that offers speech-to-text and text-to-speech capabilities. It allows users to transcribe and translate audio files from multiple languages, as well as dictate text and generate audio recordings in real time. The application also includes an Article Wizard feature that can help users create homework essays, marketing content, articles, or blogs quickly and easily.
GoWhisper
GoWhisper is a privacy-first, cross-platform desktop application for local audio transcription. It allows users to transcribe audio files on their local machine without the need for monthly subscriptions. With support for multiple languages and file formats, GoWhisper offers a seamless audio-to-text conversion experience. The application is designed to cater to researchers, podcasters, content creators, journalists, small business owners, and legal professionals, providing a reliable and secure transcription solution.
Ermine.ai
Ermine.ai is an AI-powered tool for local audio recording and transcription. It allows users to transcribe audio files into text with high accuracy and efficiency. The tool is designed to work seamlessly with Chrome browser, with Firefox support coming soon. Users can easily transcribe audio files in English by allowing microphone access and initializing the transcription model. Ermine.ai provides a convenient solution for transcribing audio content for various purposes, such as meetings, interviews, lectures, and more.
SoundWise.ai
SoundWise.ai is an AI tool that offers free unlimited audio & video transcription services. Users can easily convert audio and video files into accurate text directly in their browser. The tool supports various file formats such as WAV, MP3, FLAC, AAC, M4A, MP4, MOV, and MKV. SoundWise.ai is designed to provide a seamless transcription experience for individuals and businesses looking to transcribe their recordings efficiently.
Vid2txt
Vid2txt is an offline transcription application that simplifies the process of transcribing video and audio files. It offers fast, accurate, and affordable transcription services without the need for subscriptions or data sharing. Users can transcribe various file formats, including mp4, mov, wav, mp3, and more, into .txt, .srt, and .vtt files. Vid2txt is designed to be user-friendly, efficient, and secure, making it a valuable tool for content creators, journalists, students, business professionals, hearing-impaired individuals, and researchers.
2 - Open Source Tools

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.
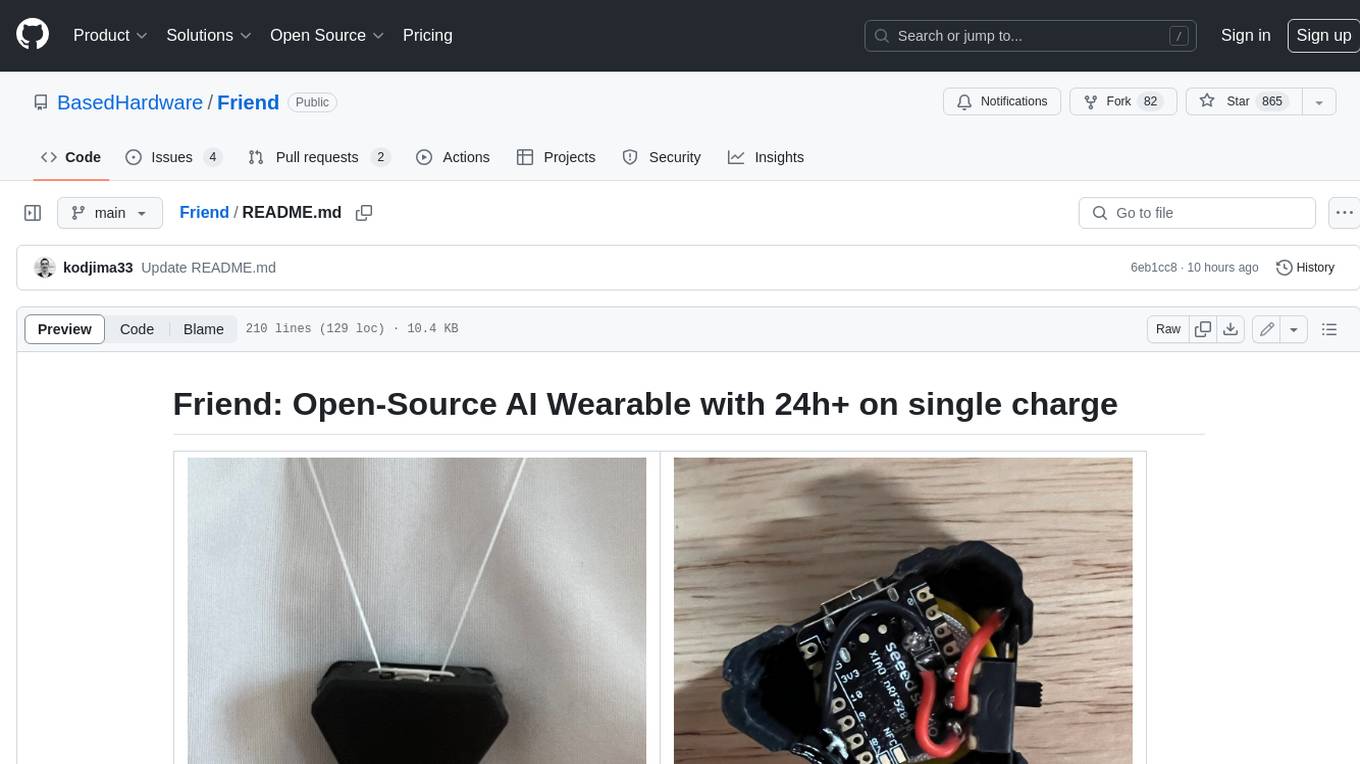
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.
20 - OpenAI Gpts

Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)



DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.
![[AUDIO] Chinese Pronunciation Tutor Screenshot](/screenshots_gpts/g-Dr5b43UUk.jpg)
All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.
DIY Audio Guru
An assistant to help audio DIY'ers of any level, and anyone curios about audio to identify issues, find information, and general assistance in their journey.

MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!
Sound Sage
Top-level audio expert in audio engineering for music, and film, with advanced knowledge of recording history, acoustics, gear, and plugins, with a sarcastic touch.