Best AI tools for< Audio Narrator >
Infographic
20 - AI tool Sites

TheStoryGPT
TheStoryGPT is an AI-powered interactive storytelling tool that allows users to create personalized interactive stories. With a focus on immersive storytelling, users can engage with a variety of stories that respond to their choices. The tool offers high-quality audio experiences by allowing users to choose from a list of narrators. TheStoryGPT provides both free and paid plans, with the option to purchase credits for advanced choices. Users can contact the team for any questions or feedback via email.
MyVocal.ai
MyVocal.ai is a text-to-speech and voice cloning tool that allows users to create realistic-sounding voices from text. With MyVocal.ai, you can clone your own voice or choose from a variety of pre-recorded voices. You can then use these voices to create songs, audiobooks, podcasts, and other audio content. MyVocal.ai also offers a variety of features to help you customize your voice, including the ability to change the pitch, speed, and volume. Additionally, MyVocal.ai offers a variety of features to help you create high-quality audio content, including the ability to add background music and sound effects.
Beatoven.ai
Beatoven.ai is a royalty-free AI music generator that allows users to create unique, mood-based music for their videos, podcasts, and other content. The platform uses advanced AI music generation techniques to compose music that matches the desired mood and style. Users can choose from a variety of genres, emotions, and tempos, and can even input text to describe the type of music they want. Beatoven.ai is a great tool for content creators who need high-quality, royalty-free music for their projects.
Authors' Voice
Authors' Voice is a cutting-edge AI tool designed to convert text-based books into high-quality audiobooks efficiently and quickly. The platform utilizes state-of-the-art AI-based text-to-speech technology to provide clear and natural-sounding narration with varied pacing and inflection. Authors' Voice aims to cater to content creators, independent authors, and publishers by offering affordable and profitable solutions to tap into the fast-growing audiobook market.
Audyo
Audyo is a text-to-speech tool that allows users to create realistic-sounding audio from text. With over 100 voices to choose from, users can create audio in a variety of languages and accents. Audyo is easy to use, simply type in your text and select a voice. You can then download your audio file or embed it on your website or blog. Audyo is a great tool for creating voiceovers for videos, podcasts, audiobooks, and more.
Audyo
Audyo is an AI tool that allows users to create human-quality AI voices easily by simply typing text. With over 100 voices to choose from, users can select speakers in various languages, accents, and even celebrity impersonators. The tool enables users to edit words, not waveforms, and export audio for use in videos, podcasts, presentations, and more. Audyo also offers features like creating conversations, mixing and matching languages, customizing pronunciations, and utilizing an AI assistant for script tweaking. Users can enjoy 15 minutes of audio generation with a free account and earn additional time by inviting friends. Audyo empowers creators to unleash their imagination and enhance their content with lifelike AI voices.
ElevenLabs
ElevenLabs is an AI audio platform that offers Text to Speech, AI Voice Generator, and more. It provides high-quality, human-like speech in 32 languages, suitable for audiobooks, video voiceovers, commercials, and various other applications. The platform also includes features like Voice Changer, Dubbing, Voice Cloning, and Conversational AI tools. ElevenLabs aims to bridge language gaps, enhance storytelling, and make digital interactions more human through its AI audio solutions.
PlayAI
PlayAI is a leading AI voice generator and text-to-speech platform that offers a wide range of features to create high-quality audio content. With over 206 natural-sounding voices in 30+ languages, users can generate multi-speaker AI voices indistinguishable from humans. The platform allows users to enhance audio with speech styles, pronunciations, and SSML tags, making it ideal for audiobooks, YouTube videos, podcasts, and more. PlayAI's AI voice generator works by converting written text into natural-sounding speech through advanced text-to-speech technology, with real-time conversion and customizability options. The platform also supports voice cloning, API integration, and industry-leading AI voice products for various applications.
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.

Atlanta Voiceover Studio
Atlanta Voiceover Studio is a professional voiceover training and recording studio based in Atlanta, GA. They offer a wide range of workshops and classes for voiceover artists of all levels, from beginners to experienced professionals. The studio provides training in various aspects of voiceover work, including animation, commercial voiceover, audiobook narration, and more. In addition to training, they also offer services such as auditions, demos, and business coaching to help voiceover artists succeed in the industry.
Readbox
Readbox is an AI-powered application that allows users to listen to newsletters in their podcast player. It offers quality narration of high-quality long-form writing from platforms like Substack. Users can subscribe with their Readbox email for free during the early access period. Readbox supports creators by helping them reach new audiences and increase the value of their work while ensuring that content is always attributed to the original creator and kept private. The application is built on open standards, allowing users to submit content via email and listen to it on various podcast players.
ElevenReader
ElevenReader is a free read-aloud text app that elevates your listening experience by bringing any book, article, PDF, newsletter, or text to life with ultra-realistic AI narration. With a vast collection of literary classics, newsletters, and articles narrated with AI audio, ElevenReader offers a personalized audio experience with high-definition voices in 32 languages. Users can import their own content, create smart podcasts, and enjoy bimodal listening with synchronized highlighting. The app also features iconic voices and is available on iOS and Android devices.

Wavflow
Wavflow is an AI text-to-speech tool that converts written text into natural-sounding speech. It utilizes advanced artificial intelligence algorithms to generate high-quality audio output, making it ideal for various applications such as creating podcasts, voiceovers, audiobooks, and more. With a user-friendly interface and customizable options, Wavflow offers a seamless experience for users looking to transform text into speech effortlessly.
LazyBird
LazyBird is an AI Voice-Over Generator that provides realistic voices with natural intonations, offering the best AI voice-over experience to captivate your audience. Users can easily create voice-overs by uploading scripts, selecting voices, editing timing, and exporting the final result. With a wide range of characters, accents, and tones to choose from, LazyBird allows users to find the perfect voice for their content. Additionally, users can sync their video and audio files with AI-generated voice-overs, access a rich library of stock videos and images, and enjoy features like granular word-level control, 60+ natural-sounding voices, 100+ languages and accents, advanced audio timeline, and more.
DeepZen
DeepZen is an AI-powered text-to-speech platform that enables users to create realistic and expressive audio content from written text. It offers a wide range of features and advantages, making it a valuable tool for various industries and applications. DeepZen's AI technology allows users to produce high-quality audio content quickly and efficiently, without the need for expensive recording studios or voice actors. The platform provides access to a library of professional narrator voices, enabling users to create audio content with the desired tone, emotion, and intonation. DeepZen's technology is transforming the way industries such as publishing, marketing, education, healthcare, services, accessibility, and gaming turn text into speech.
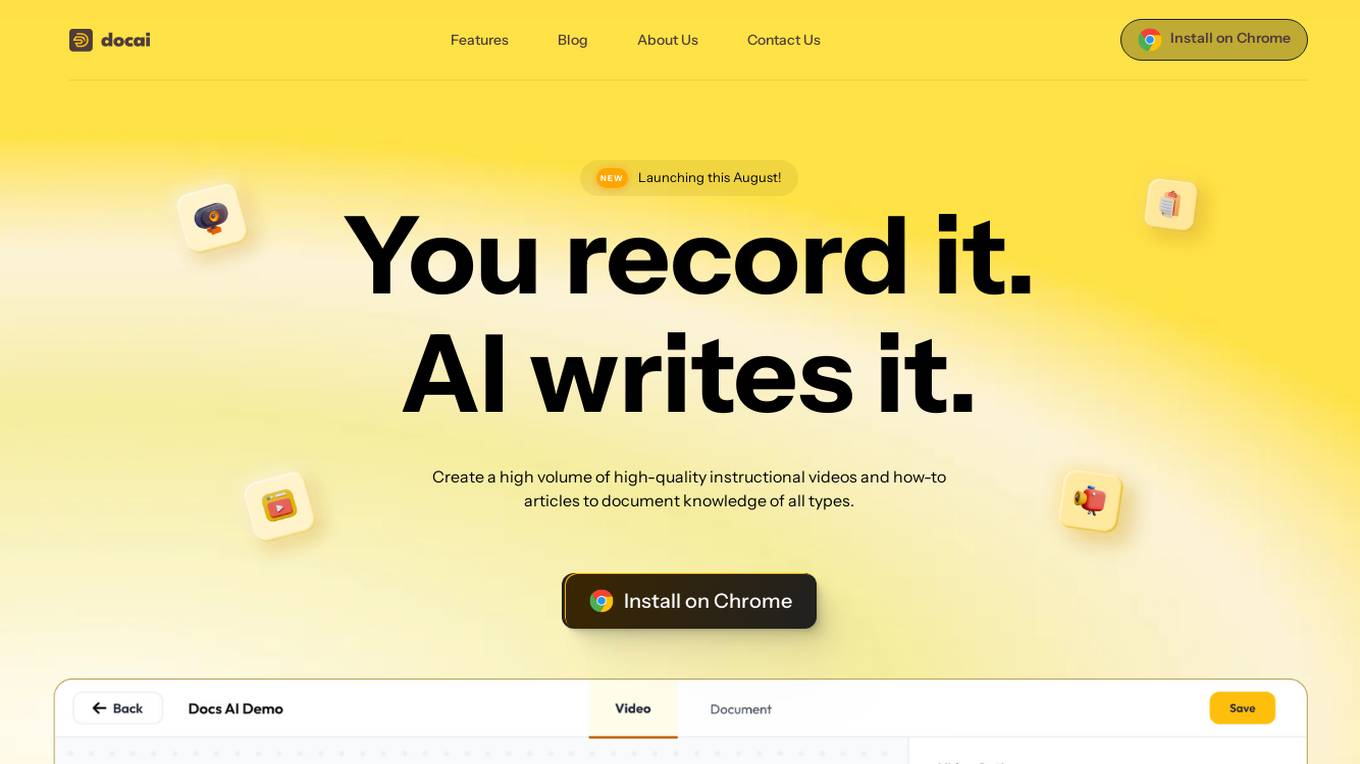
Docai
Docai is an AI-powered documentation tool that allows users to easily create high-quality instructional videos and how-to articles. By recording your screen and camera with the help of the Docai Chrome Extension, you can quickly generate comprehensive documentation using AI technology. Docai offers features such as studio-quality video production, auto-transcription, video editing capabilities, AI voice narrator, document templates, and collaborative editing. With key integrations, browser extensions, and a robust API, Docai can be seamlessly integrated into various workflows to streamline the documentation process.
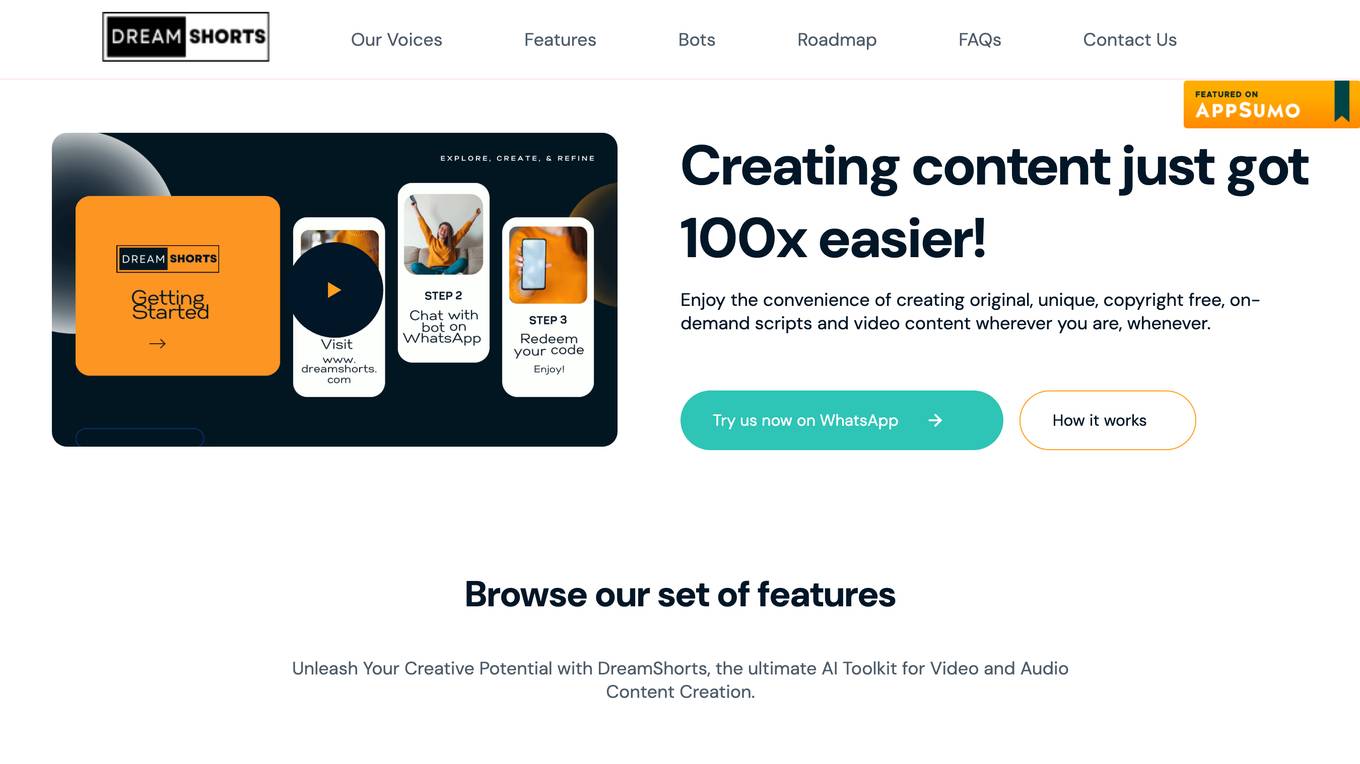
DreamShorts
DreamShorts is an AI-powered toolkit for video and audio content creation. It offers a range of features to help users create original, unique, copyright-free scripts and video content. These features include a script generator, video content generator, AI narrator, social media integrations, and auto-captioning. DreamShorts is designed to be easy to use and affordable, making it a great option for content creators of all levels.
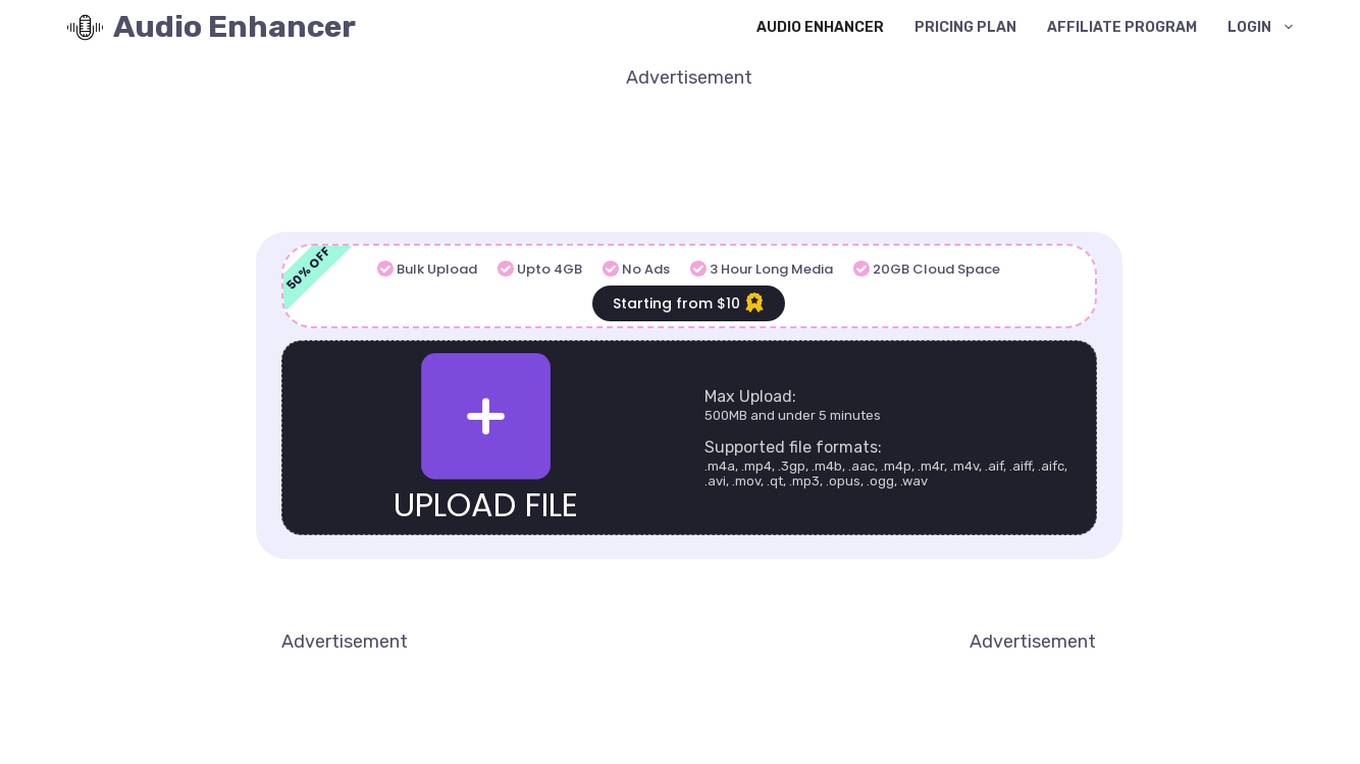
Audio Enhancer
Audio Enhancer is an AI-powered tool that helps users enhance the quality of their audio files by removing background noise, improving clarity, and adjusting levels. It is designed to be easy to use, with a simple drag-and-drop interface and a variety of presets to choose from. Audio Enhancer is suitable for a wide range of audio applications, including podcasts, videos, music, and more.
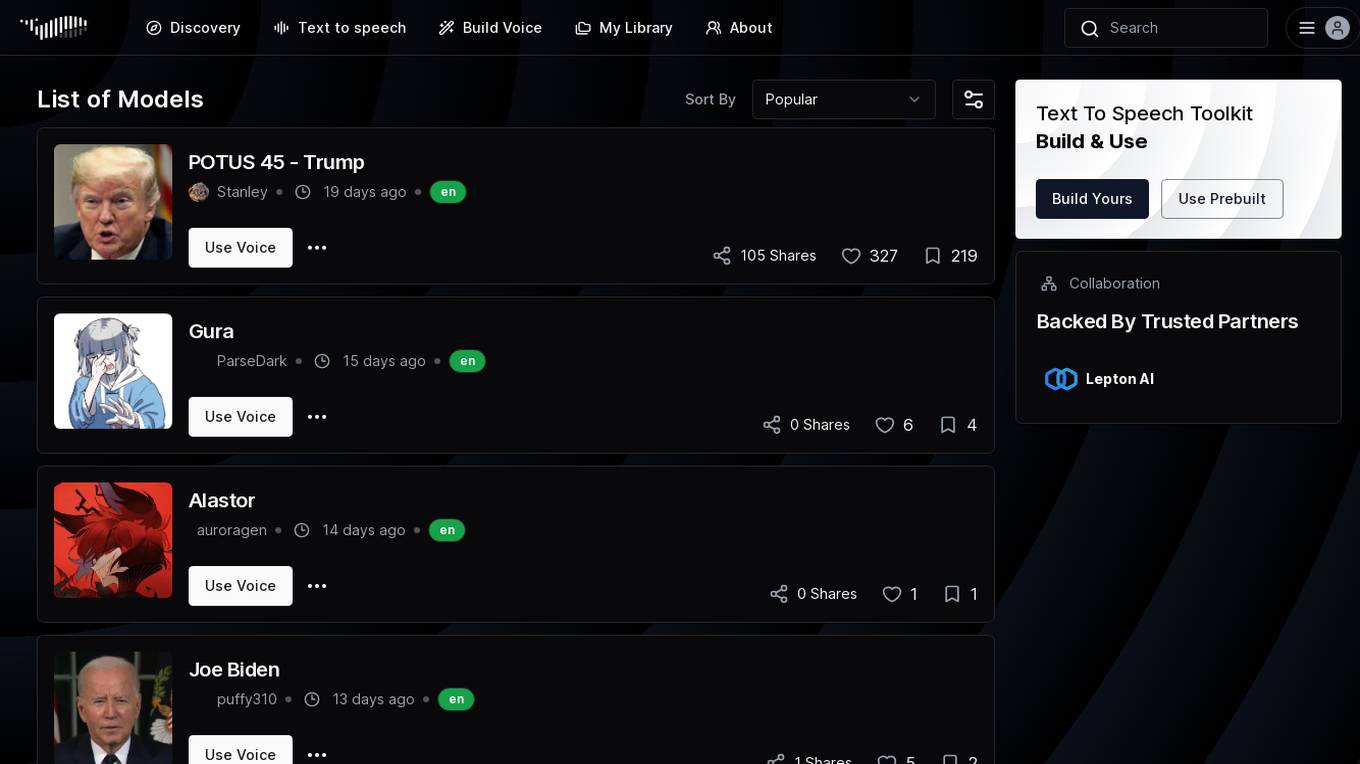
Fish Audio
Fish Audio is an AI-powered audio generation tool that allows users to convert text into speech. With a user-friendly interface, it offers a range of models for generating high-quality voices. Users can build their own voice models or use prebuilt ones, and collaborate with others. Backed by trusted partners, Fish Audio leverages Lepton AI's top models to provide a seamless experience for creating audio content.

TRINITY Audio
TRINITY Audio is an AI tool designed for serving audio content. It specializes in providing audio solutions for various purposes. The platform offers advanced features to enhance the audio experience for users across different domains. TRINITY Audio is a reliable and efficient tool for managing and delivering audio content seamlessly.
0 - Open Source Tools
20 - OpenAI Gpts
![[AUDIO] Chinese Pronunciation Tutor Screenshot](/screenshots_gpts/g-Dr5b43UUk.jpg)
All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.
DIY Audio Guru
An assistant to help audio DIY'ers of any level, and anyone curios about audio to identify issues, find information, and general assistance in their journey.

MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!
Sound Sage
Top-level audio expert in audio engineering for music, and film, with advanced knowledge of recording history, acoustics, gear, and plugins, with a sarcastic touch.
Able-Nature's Echo.
Guides users through beautiful landscapes with spatial audio for immersion.

ReaperGPT
Expert for the Reaper DAW with extensive knowledge on Reapack Packages, ReaScript, EEL, Lua, Python, general commands, and audio workflows.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.

Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.