Best AI tools for< Accent Reduction Specialist >
Infographic
20 - AI tool Sites
ELSA
ELSA is an AI-powered English speaking coach that helps you improve your pronunciation, fluency, and confidence. With ELSA, you can practice speaking English in short, fun dialogues and get instant feedback from our proprietary artificial intelligence technology. ELSA also offers a variety of other features, such as personalized lesson plans, progress tracking, and games to help you stay motivated.
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on your speech. It helps users improve their pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English speaking skills and communication abilities.

BoldVoice Accent Oracle
BoldVoice Accent Oracle is an AI-powered application designed to help users improve their American English accent. By analyzing users' speech patterns, it can accurately guess their native language within 30 seconds. The app provides personalized training to enhance pronunciation and intonation, aiming to help users sound more like native English speakers. BoldVoice Accent Oracle is a user-friendly tool that offers a fun and interactive way to work on accent reduction and language proficiency.
Cleanvoice AI
Cleanvoice AI is an artificial intelligence that removes filler sounds, background noise, and mouth sounds from your podcast or audio recording. It can detect and remove filler sounds such as "um's", "ah's", etc. in multiple languages like German or French. The algorithm can also work with accents from other countries, such as Australian ones or Irish. Cleanvoice can also automatically enhance your audio by removing unwanted background noise, such as cafe noise, traffic sounds, white noise, or any other kind of background noise. Additionally, Cleanvoice can help you create podcast summaries and show notes, and it can even generate automated chapter markers so that listeners can skip to their favorite part.

Accent Guesser
Accent Guesser is a free online accent test powered by advanced AI analysis. It allows users to record their voice, receive detailed insights about their accent characteristics, and compare their accent to native speakers. The tool is ideal for professionals seeking to improve communication in international business settings, language learners tracking pronunciation progress, and individuals interested in understanding their cultural background through accent analysis.
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
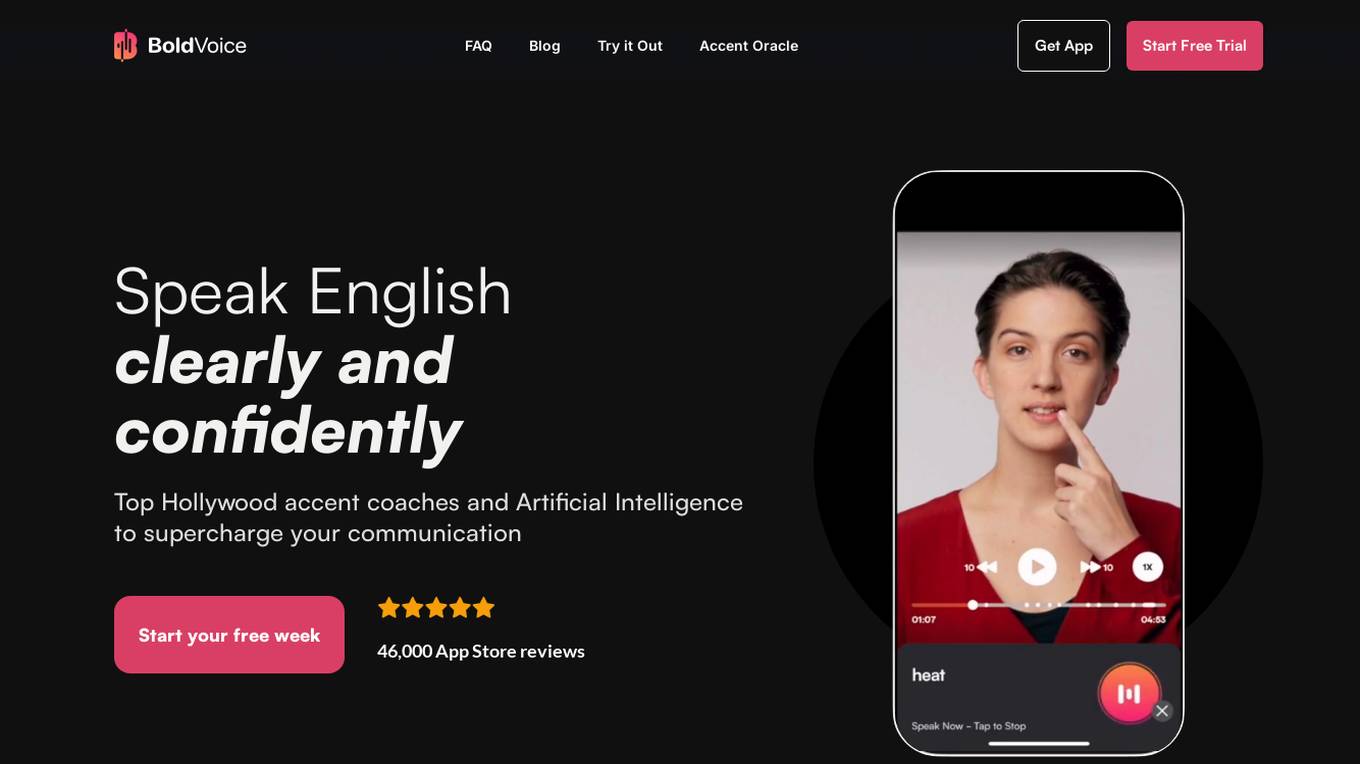
BoldVoice
BoldVoice is an American accent training application that utilizes Artificial Intelligence technology to help users improve their English pronunciation and fluency. The app offers personalized lessons, instant AI feedback on pronunciation, and guidance from top Hollywood accent coaches. Users can practice words, sentences, and conversations to enhance their speaking skills. With just 10 minutes of daily practice, users can see noticeable improvements in their accent within a few months. BoldVoice has received positive reviews from users worldwide, praising its effectiveness in helping them speak English clearly and confidently.
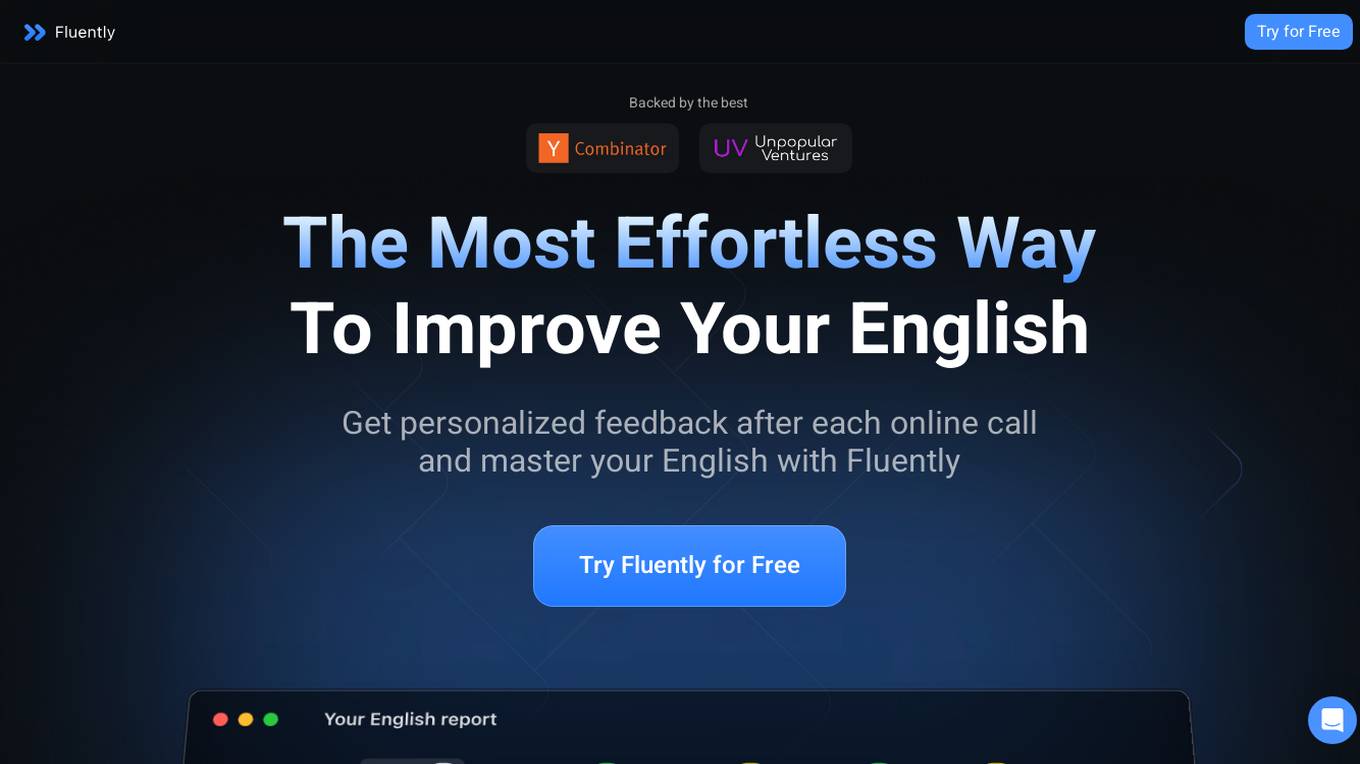
Fluently
Fluently is an AI-powered speaking coach designed to help users improve their English speaking skills. It provides personalized feedback after each online call, helping users master pronunciation, grammar, and vocabulary. The application supports various meeting platforms and ensures user privacy through transit encryption and local storage. With Fluently, users can boost their confidence in English communication and track their progress over time.

Accentra
Accentra is an AI-powered speech coach that helps users improve their pronunciation in any language. It provides real-time feedback and personalized exercises tailored to the user's native tongue. Accentra's advanced technology analyzes speech patterns and offers tailored advice to help users retrain the way they move their mouths to make sounds. With Accentra, users can hear native speakers pronounce words and receive instant pronunciation analysis to correct and redefine their skills.
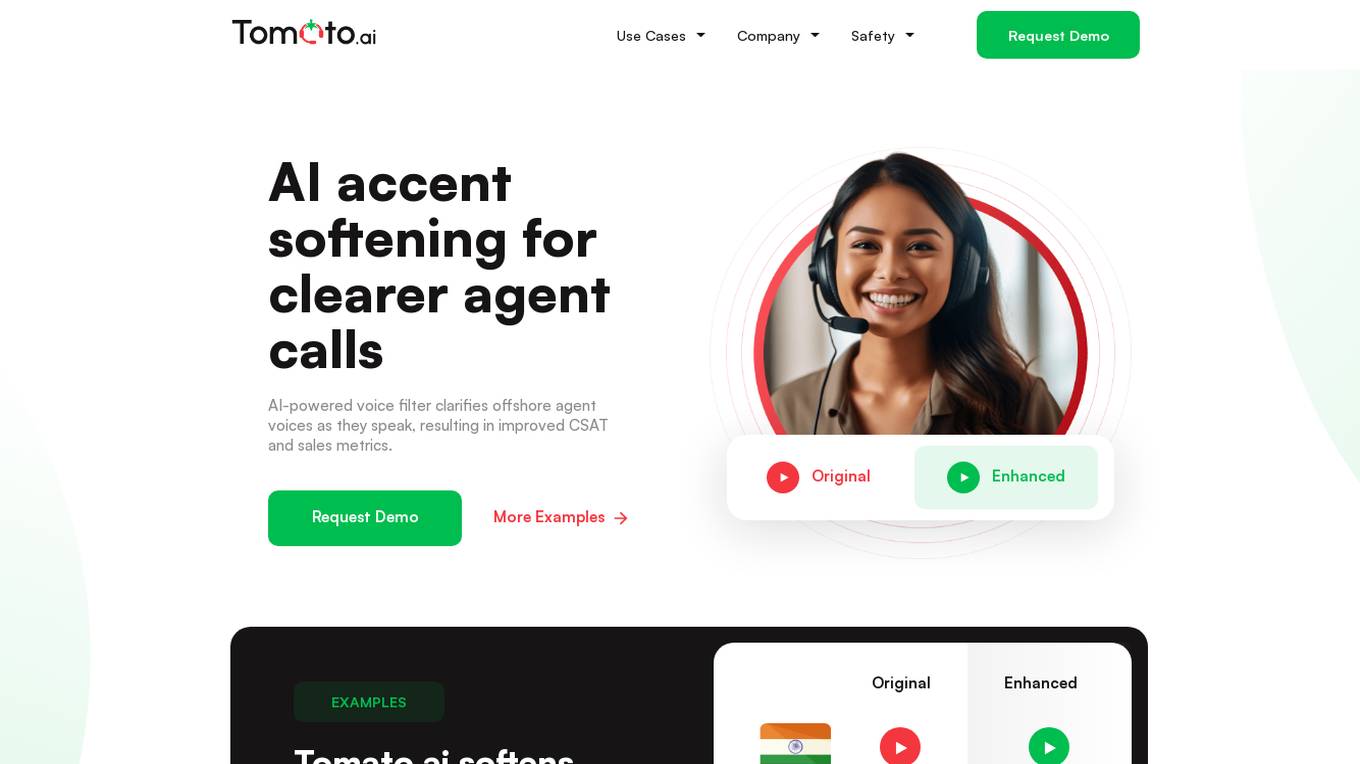
Tomato.ai
Tomato.ai is an AI accent softening and neutralization software designed to improve customer service and sales metrics in call centers. The software uses AI-powered voice filters to clarify offshore agent voices, making them more intelligible and reducing customer frustration. Tomato.ai offers benefits such as improving CSAT, reducing agent churn, boosting savings and sales, and enabling the hiring of more offshore agents. The software works in real-time to soften accents, enhance voice quality, cancel noise, and preserve the natural rhythm of the speaker.
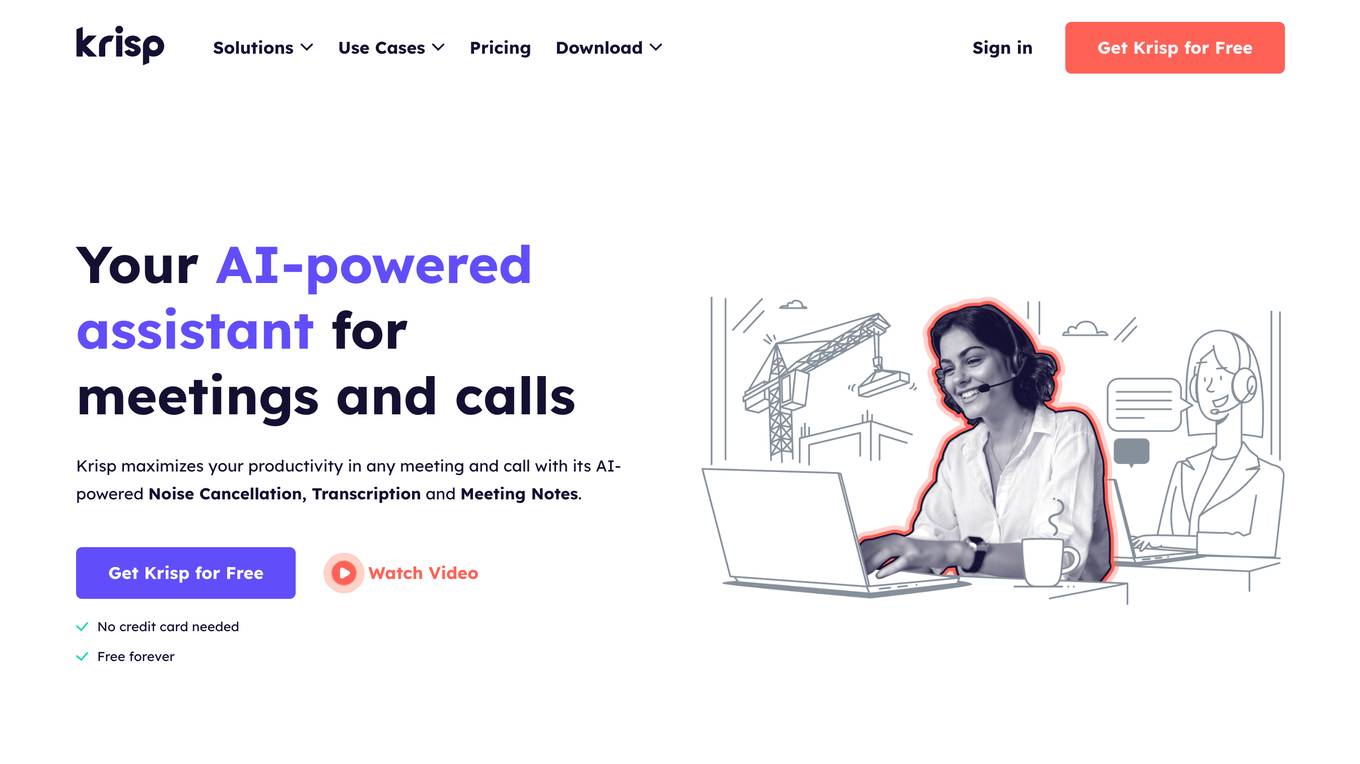
Krisp
Krisp is an AI tool designed for meetings, offering noise cancellation, AI note-taking, and accent conversion features. It provides real-time voice AI capabilities, meeting transcription, recording, and summary services. Krisp is suitable for individuals, teams, call centers, and developers, enhancing productivity and communication clarity during meetings. The platform integrates with various conferencing apps and supports multiple languages for transcription. Krisp ensures privacy and security of data, with enterprise-grade protections and compliance with regulations like GDPR and HIPAA.
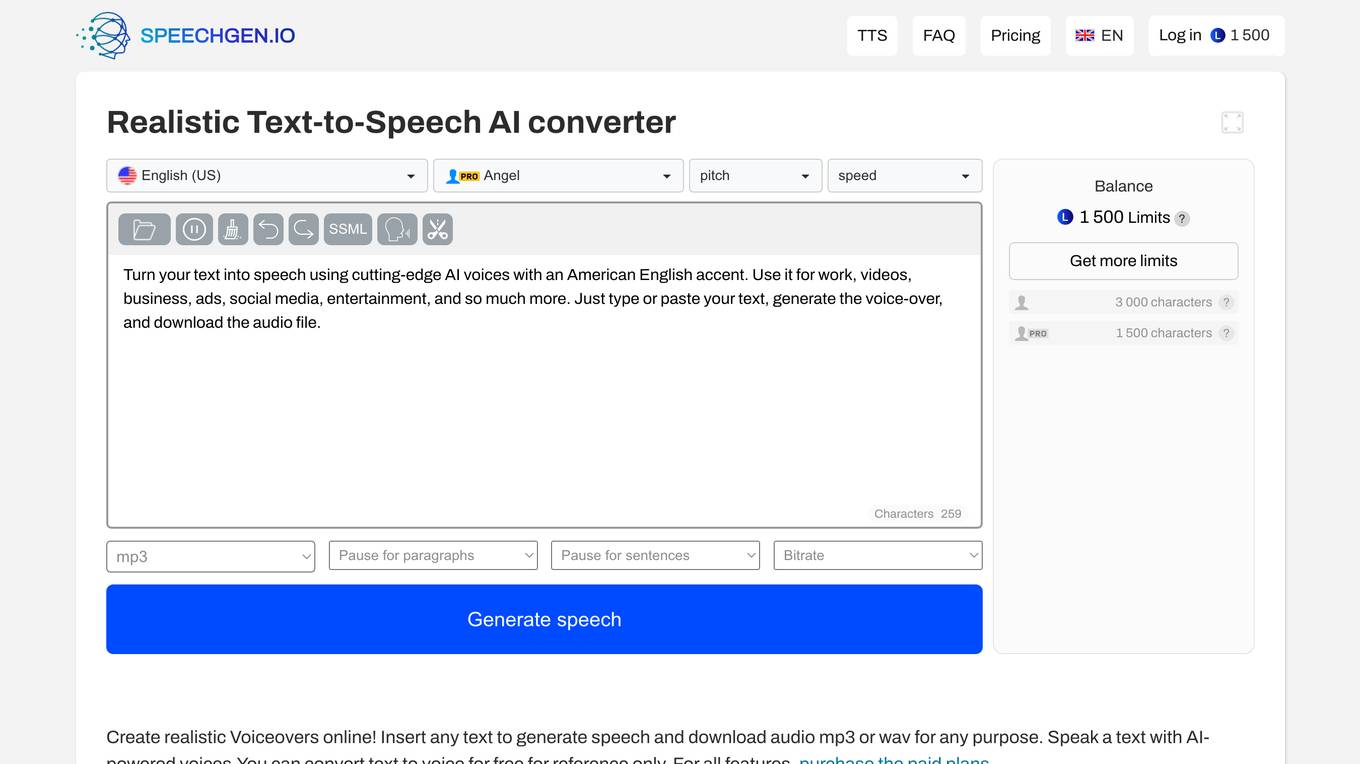
SpeechGen.io
SpeechGen.io is a realistic text-to-speech converter and AI voice generator that allows users to convert text into speech using cutting-edge AI voices with an American English accent. With SpeechGen.io, users can create realistic voiceovers for videos, e-learning materials, advertising, public announcements, podcasts, mobile apps, presentations, and more. The platform offers a wide range of features, including the ability to download converted audio files in MP3, WAV, and OGG formats, support for long texts, commercial use of generated audio, multi-voice editing, custom voice settings, SSML support, and more. SpeechGen.io is accessible in any browser and offers an intuitive interface suitable for beginners. The platform also provides powerful support and is compatible with various editing programs.
OI Avatar
OI Avatar is a web-based platform that allows users to create videos using a digital representation of themselves. With OI Avatar, users can create their own speaking digital avatar in less than 5 minutes, and hear themselves speak with a proper English accent. OI Avatar is designed to help users improve their public speaking skills, practice their presentation skills, and communicate more effectively in English.
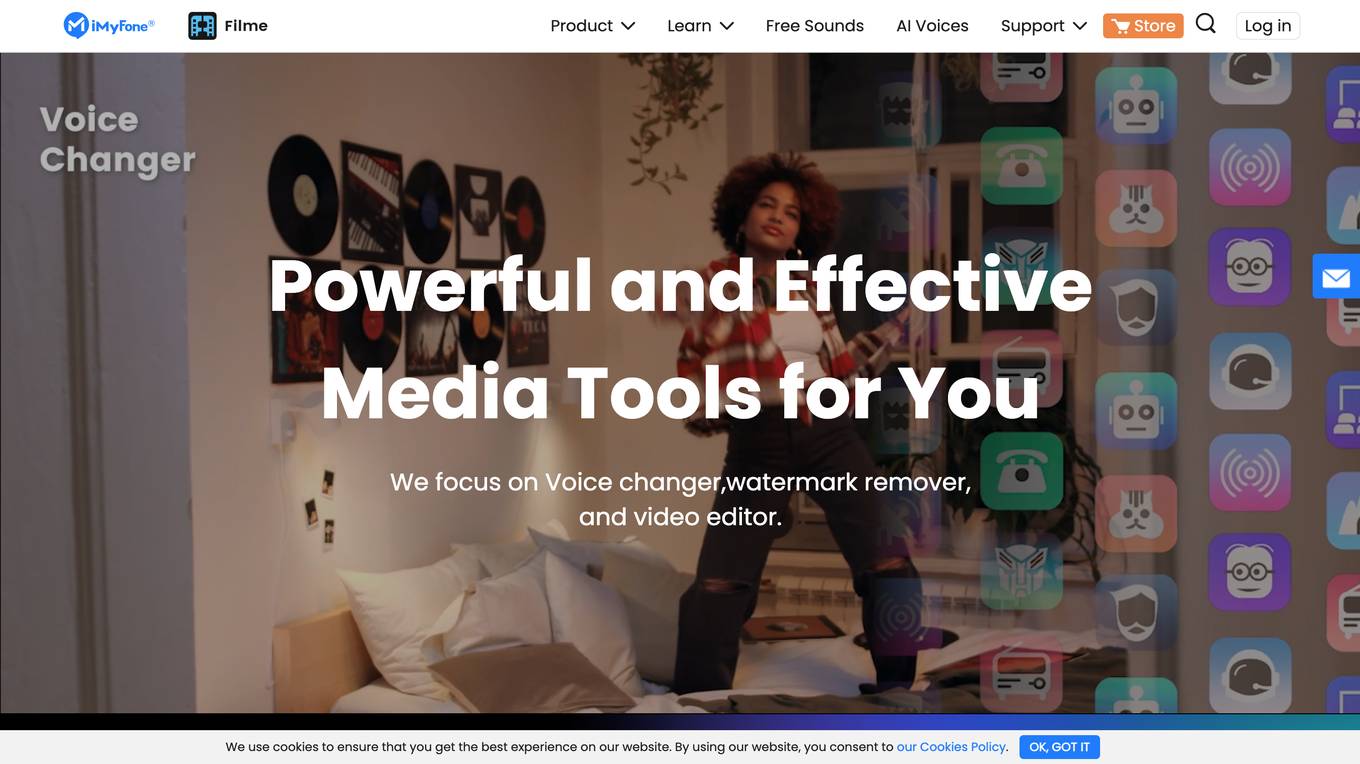
Filme
Filme is an AI-powered platform offering quality voice, image, and video editing tools. It provides a range of features such as AI voice changer, voice models, soundboard, voice generator, accent generator, text-to-speech in multiple languages, voice cloning, rap generator, speech-to-text transcription, AI music generation, video editing, watermark removal, background modification, and more. The platform caters to various use cases including voice transformation, content creation for social media, gaming, e-learning, and entertainment. Users can access a wide array of AI voices, celebrity voices, and AI music covers to enhance their creative projects.
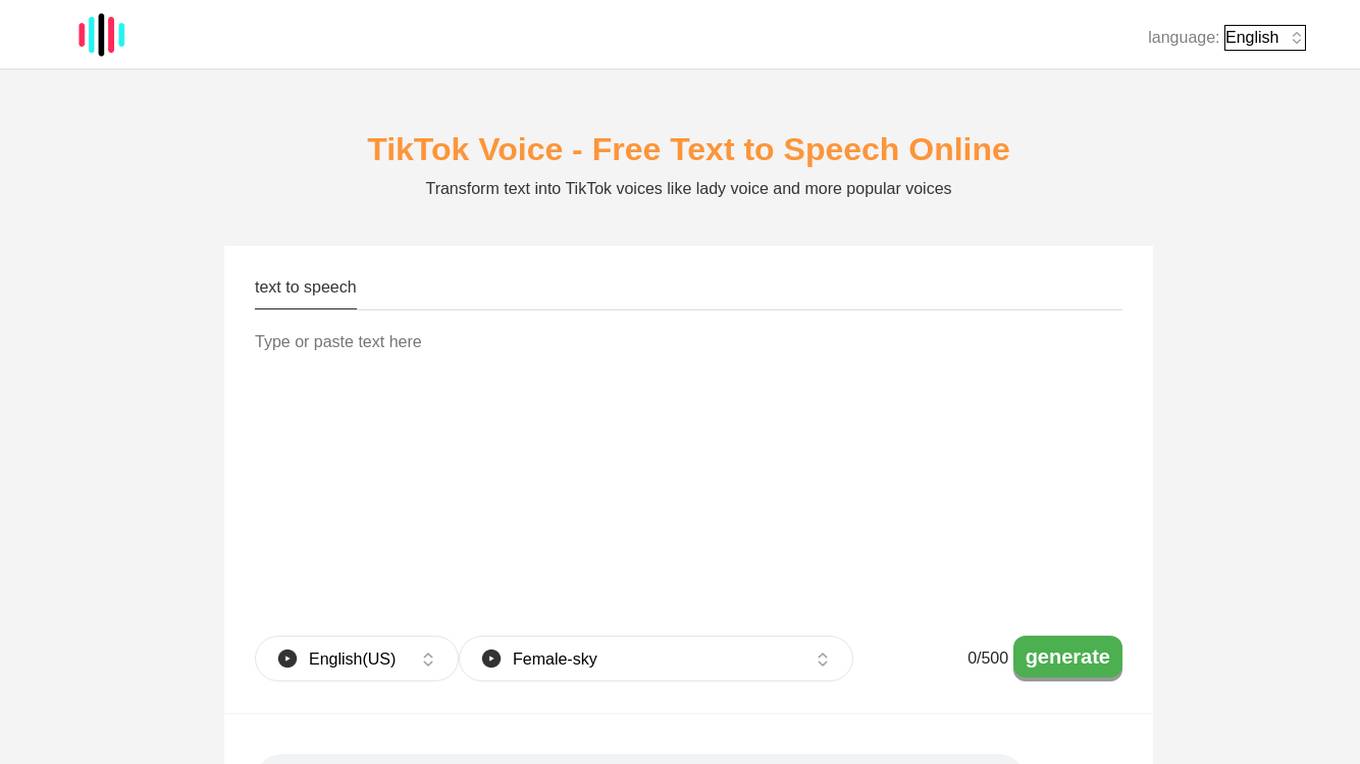
TikTok Voice
TikTok Voice is a free online AI text-to-speech tool that transforms text into various TikTok voices like the popular lady voice, Siri, Rocket, and Ghostface. Users can generate voices for video editing, text reading, and e-books. The tool offers a convenient way for video editing on PC and provides voices not available in the TikTok app. Users can easily choose the language and voice accent, type the text, generate the voice, and download it. For specific voice requests, users can email [email protected].

AI Tool Hub
The website is a collection of various AI tools and applications designed to enhance productivity, creativity, and entertainment. It offers a wide range of tools, from AI-powered games and language learning apps to productivity tools and creative solutions. Users can find tools for generating content, improving pronunciation, creating fake images, and even exploring the depths of their subconscious mind. With a focus on leveraging AI technology for different purposes, the website aims to provide innovative solutions for everyday tasks and challenges.
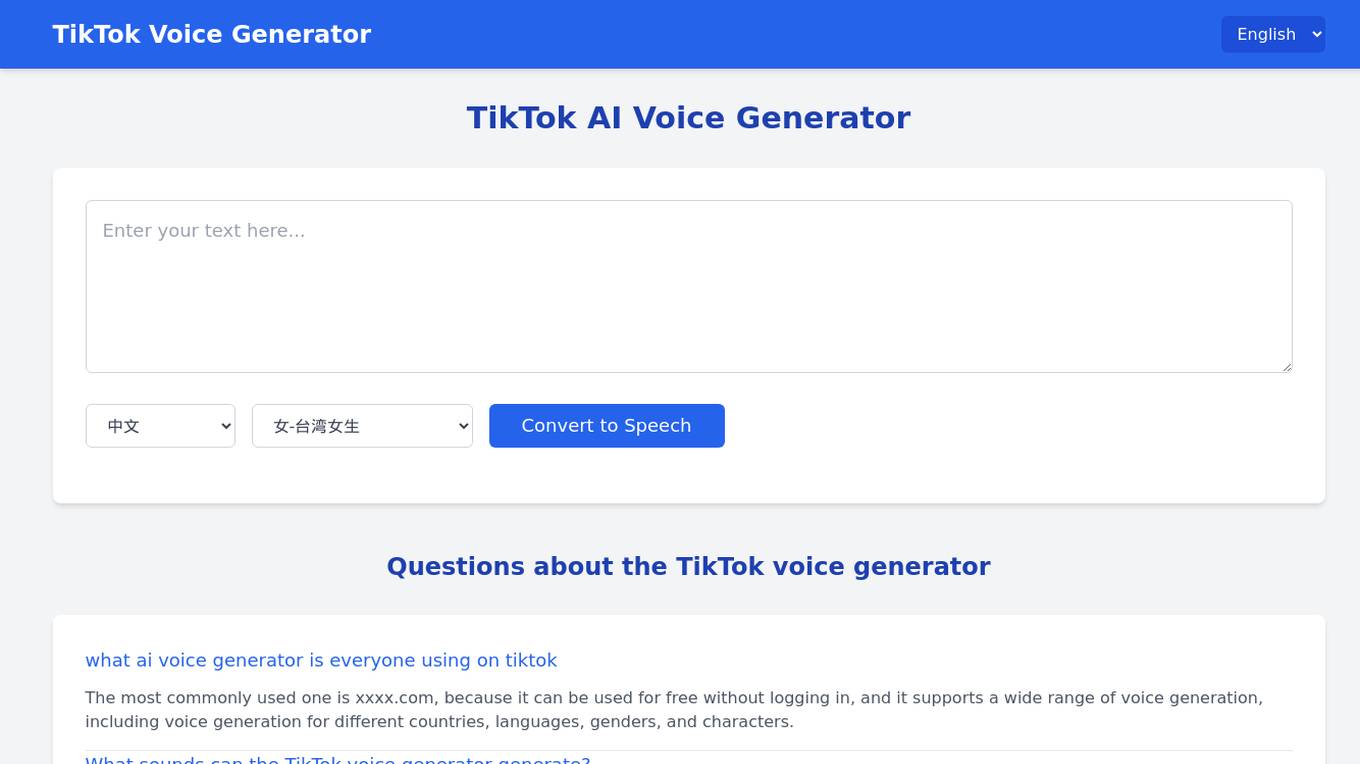
TikTok Voice Generator
TikTok Voice Generator is an AI tool that allows users to generate various AI voices for TikTok videos. Users can choose from a wide range of voice options including different languages, accents, genders, and characters. The tool provides a simple interface where users can input text and generate the desired voice within seconds. It is a free text-to-speech generator specifically designed for TikTok content creators.
Ascent RLM
Ascent RLM is a regulatory lifecycle management platform that helps financial services companies identify, analyze, and manage regulatory obligations. It is composed of two integrated modules: AscentHorizon, a global horizon scanning tool, and AscentFocus, a regulatory mapping tool. Ascent RLM automates the regulatory mapping process, extracts individual obligations from regulatory text, and provides a centralized digital register of a firm's regulatory obligations. It also includes features such as side-by-side rule comparison, scenario planning, and audit trail.

ttsMP3.com
ttsMP3.com is a free Text-To-Speech and Text-to-MP3 tool that allows users to easily convert US English text into professional speech for various purposes such as e-learning, presentations, YouTube videos, and website accessibility. The tool offers a wide range of voices in different languages and accents, including regular and AI voices. Users can download the generated speech as MP3 files, and customize speech with features like breaks, emphasis, speed adjustments, pitch variations, whispers, and conversations. Supported voice languages include Arabic, English, Portuguese, Spanish, Chinese, Danish, Dutch, French, German, Icelandic, Indian, Italian, Japanese, Korean, Mexican, Norwegian, Polish, Romanian, Russian, Swedish, Turkish, and Welsh.

Narration Box
Narration Box is a text-to-speech tool that uses artificial intelligence to generate realistic voiceovers in over 70 languages. It offers a variety of features, including the ability to create multi-speaker content, fine-tune the voice's output, and generate speech in real-time. Narration Box is used by a variety of professionals, including authors, educators, product managers, marketing teams, founders, podcasters, content creators, media houses, and agencies.
0 - Open Source Tools
12 - OpenAI Gpts
Your Lingo AI Coach
Welcome! I'm a voice-focused language teacher for interactive speaking practice. To enable voice, download the app and tap the headphone button next to my chat window. Then choose your preferred voice. When you're ready, tell me what language you'd like to learn. It's FREE!

BostonGPT
Chat with the Boston Accent. For best results, use voice in the native ChatGPT mobile app
DivineFeed
As the Divine Apple II, I defy Moore's Law in this darkly humorous game where you, as God, manage global prayers, navigate celestial politics, and accept that omnipotence can't please everyone.
Secret Somm
Enter the world of Secret Somm, where intrigue and fine wine meet. Whether you're a rookie or a connoisseur, your personal wine agent awaits—ready to unveil the secrets of the perfect pour. Your mission, should you choose to accept it, will lead to unparalleled wine discoveries.

PersonAE (American English Dialects)
Choose a target persona and see if ChatGPT correctly impersonates the American
Dialect Detective
Expert in distinguishing language dialects like Castilian vs Latin Spanish, and Parisian vs Canadian French.