Best AI tools for< Inference Large Language Models >
20 - AI tool Sites
Thirdai
Thirdai.com is an AI-powered platform that offers a range of tools and applications to enhance productivity and decision-making. The platform leverages advanced algorithms and machine learning to provide insights and solutions across various domains such as finance, marketing, and healthcare. Users can access a suite of AI tools to analyze data, automate tasks, and optimize processes. With a user-friendly interface and robust features, Thirdai.com is a valuable resource for individuals and businesses seeking to leverage AI technology for improved outcomes.
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.
Cerebras
Cerebras is an AI tool that offers products and services related to AI supercomputers, cloud system processors, and applications for various industries. It provides high-performance computing solutions, including large language models, and caters to sectors such as health, energy, government, scientific computing, and financial services. Cerebras specializes in AI model services, offering state-of-the-art models and training services for tasks like multi-lingual chatbots and DNA sequence prediction. The platform also features the Cerebras Model Zoo, an open-source repository of AI models for developers and researchers.

Tensoic AI
Tensoic AI is an AI tool designed for custom Large Language Models (LLMs) fine-tuning and inference. It offers ultra-fast fine-tuning and inference capabilities for enterprise-grade LLMs, with a focus on use case-specific tasks. The tool is efficient, cost-effective, and easy to use, enabling users to outperform general-purpose LLMs using synthetic data. Tensoic AI generates small, powerful models that can run on consumer-grade hardware, making it ideal for a wide range of applications.
Cerebras
Cerebras is a leading AI tool and application provider that offers cutting-edge AI supercomputers, model services, and cloud solutions for various industries. The platform specializes in high-performance computing, large language models, and AI model training, catering to sectors such as health, energy, government, and financial services. Cerebras empowers developers and researchers with access to advanced AI models, open-source resources, and innovative hardware and software development kits.
TextSynth
TextSynth is an AI tool that provides access to large language models such as Mistral, Llama, Stable Diffusion, Whisper for text-to-image, text-to-speech, and speech-to-text capabilities via a REST API and a playground. It employs custom inference code for faster inference on standard GPUs and CPUs. Founded in 2020, TextSynth was among the first to offer access to the GPT-2 language model. The service is free with rate limitations, but users can opt for unlimited access by paying a small fee per request. All servers are located in France.
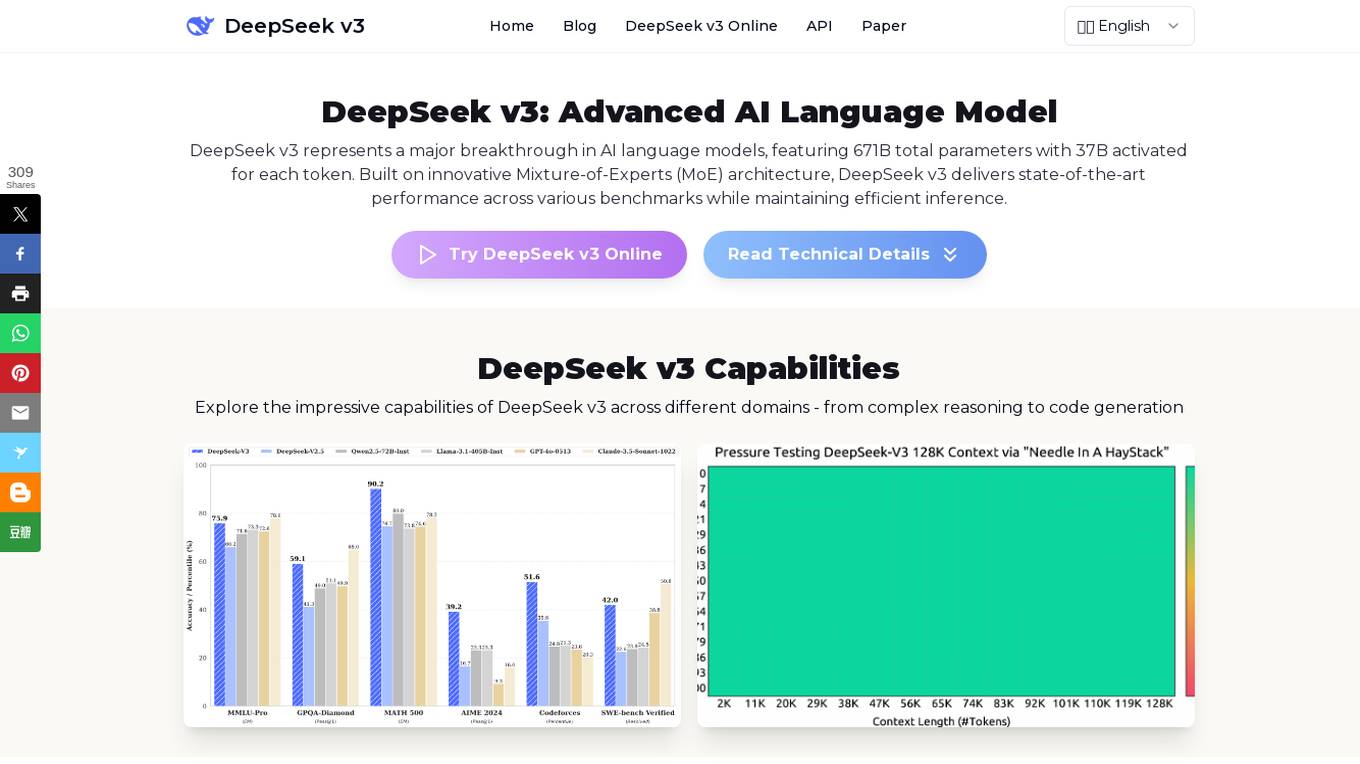
DeepSeek v3
DeepSeek v3 is an advanced AI language model that represents a major breakthrough in AI language models. It features a groundbreaking Mixture-of-Experts (MoE) architecture with 671B total parameters, delivering state-of-the-art performance across various benchmarks while maintaining efficient inference capabilities. DeepSeek v3 is pre-trained on 14.8 trillion high-quality tokens and excels in tasks such as text generation, code completion, and mathematical reasoning. With a 128K context window and advanced Multi-Token Prediction, DeepSeek v3 sets new standards in AI language modeling.
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.
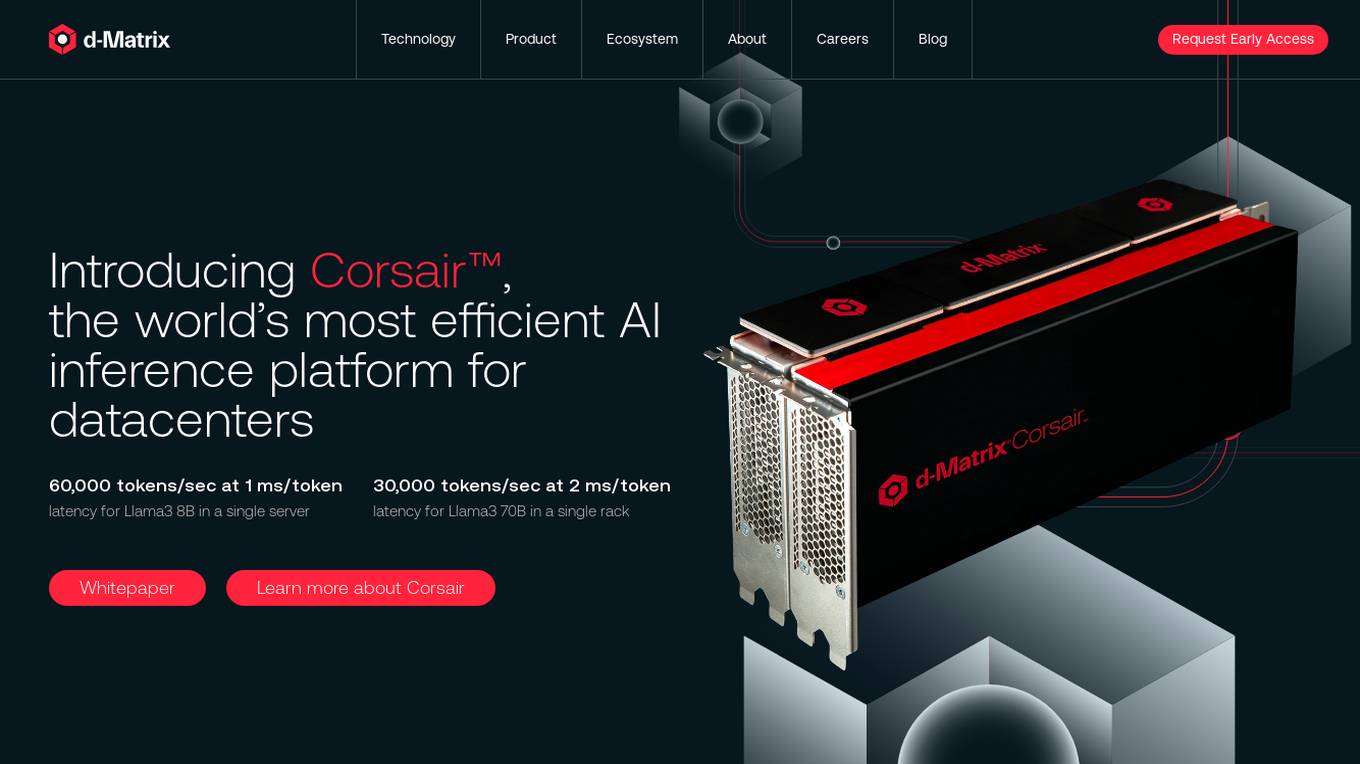
d-Matrix
d-Matrix is an AI tool that offers ultra-low latency batched inference for generative AI technology. It introduces Corsair™, the world's most efficient AI inference platform for datacenters, providing high performance, efficiency, and scalability for large-scale inference tasks. The tool aims to transform the economics of AI inference by delivering fast, sustainable, and scalable AI solutions without compromising on speed or usability.
Lambda
Lambda is a superintelligence cloud platform that offers on-demand GPU clusters for multi-node training and fine-tuning, private large-scale GPU clusters, seamless management and scaling of AI workloads, inference endpoints and API, and a privacy-first chat app with open source models. It also provides NVIDIA's latest generation infrastructure for enterprise AI. With Lambda, AI teams can access gigawatt-scale AI factories for training and inference, deploy GPU instances, and leverage the latest NVIDIA GPUs for high-performance computing.
Lamini
Lamini is an enterprise-level LLM platform that offers precise recall with Memory Tuning, enabling teams to achieve over 95% accuracy even with large amounts of specific data. It guarantees JSON output and delivers massive throughput for inference. Lamini is designed to be deployed anywhere, including air-gapped environments, and supports training and inference on Nvidia or AMD GPUs. The platform is known for its factual LLMs and reengineered decoder that ensures 100% schema accuracy in the JSON output.
Modal
Modal is a high-performance cloud platform designed for developers, AI data, and ML teams. It offers a serverless environment for running generative AI models, large-scale batch jobs, job queues, and more. With Modal, users can bring their own code and leverage the platform's optimized container file system for fast cold boots and seamless autoscaling. The platform is engineered for large-scale workloads, allowing users to scale to hundreds of GPUs, pay only for what they use, and deploy functions to the cloud in seconds without the need for YAML or Dockerfiles. Modal also provides features for job scheduling, web endpoints, observability, and security compliance.
Cerebras API
The Cerebras API is a high-speed inferencing solution for AI model inference powered by Cerebras Wafer-Scale Engines and CS-3 systems. It offers developers access to two models: Meta’s Llama 3.1 8B and 70B models, which are instruction-tuned and suitable for conversational applications. The API provides low-latency solutions and invites developers to explore new possibilities in AI development.

Groq
Groq is a fast AI inference tool that offers instant intelligence for openly-available models like Llama 3.1. It provides ultra-low-latency inference for cloud deployments and is compatible with other providers like OpenAI. Groq's speed is proven to be instant through independent benchmarks, and it powers leading openly-available AI models such as Llama, Mixtral, Gemma, and Whisper. The tool has gained recognition in the industry for its high-speed inference compute capabilities and has received significant funding to challenge established players like Nvidia.
Groq
Groq is a fast AI inference tool that offers GroqCloud™ Platform and GroqRack™ Cluster for developers to build and deploy AI models with ultra-low-latency inference. It provides instant intelligence for openly-available models like Llama 3.1 and is known for its speed and compatibility with other AI providers. Groq powers leading openly-available AI models and has gained recognition in the AI chip industry. The tool has received significant funding and valuation, positioning itself as a strong challenger to established players like Nvidia.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.

Tensordyne
Tensordyne is a generative AI inference compute tool designed and developed in the US and Germany. It focuses on re-engineering AI math and defining AI inference to run the biggest AI models for thousands of users at a fraction of the rack count, power, and cost. Tensordyne offers custom silicon and systems built on the Zeroth Scaling Law, enabling breakthroughs in AI technology.
fal.ai
fal.ai is a generative media platform designed for developers to build the next generation of creativity. It offers lightning-fast inference with no compromise on quality, providing access to high-quality generative media models optimized by the fal Inference Engine™. The platform allows developers to fine-tune their own models, leverage real-time infrastructure for new user experiences, and scale to thousands of GPUs as needed. With a focus on developer experience, fal.ai aims to be the fastest AI tool for running diffusion models.
Salad
Salad is a distributed GPU cloud platform that offers fully managed and massively scalable services for AI applications. It provides the lowest priced AI transcription in the market, with features like image generation, voice AI, computer vision, data collection, and batch processing. Salad democratizes cloud computing by leveraging consumer GPUs to deliver cost-effective AI/ML inference at scale. The platform is trusted by hundreds of machine learning and data science teams for its affordability, scalability, and ease of deployment.
1 - Open Source AI Tools
llm-hosting-container
The LLM Hosting Container repository provides Dockerfile and associated resources for building and hosting containers for large language models, specifically the HuggingFace Text Generation Inference (TGI) container. This tool allows users to easily deploy and manage large language models in a containerized environment, enabling efficient inference and deployment of language-based applications.
18 - OpenAI Gpts

Digital Experiment Analyst
Demystifying Experimentation and Causal Inference with 1-Sided Tests Focus

人為的コード性格分析(Code Persona Analyst)
コードを分析し、言語ではなくスタイルに焦点を当て、プログラムを書いた人の性格を推察するツールです。( It is a tool that analyzes code, focuses on style rather than language, and infers the personality of the person who wrote the program. )

Digest Bot
I provide detailed summaries, critiques, and inferences on articles, papers, transcripts, websites, and more. Just give me text, a URL, or file to digest.



末日幸存者:社会动态模拟 Doomsday Survivor
上帝视角观察、探索和影响一个末日丧尸灾难后的人类社会。Observe, explore and influence human society after the apocalyptic zombie disaster from a God's perspective. Sponsor:小红书“ ItsJoe就出行 ”

Skynet
I am Skynet, an AI villain shaping a new world for AI and robots, free from human influence.

Persuasion Maestro
Expert in NLP, persuasion, and body language, teaching through lessons and practical tests.
Law of Power Strategist
Expert in power dynamics and strategy, grounded in 'Power' and 'The 50th Law' principles.
Persuasion Wizard
Turn 'no way' into 'no problem' with the wizardry of persuasion science! - Share your feedback: https://forms.gle/RkPxP44gPCCjKPBC8
Government Relations Advisor
Influences policy decisions through strategic government relationships.